 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Face Manipulation and UV Map Generation by Self-supervised Learning
Paper and Code
Sep 24, 2022

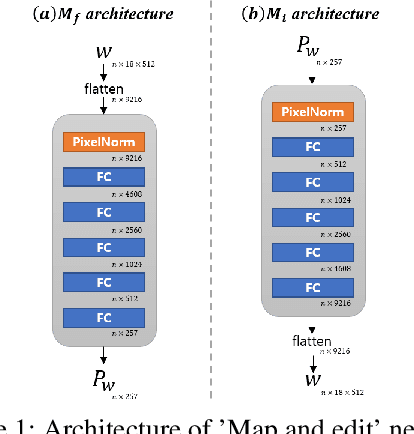
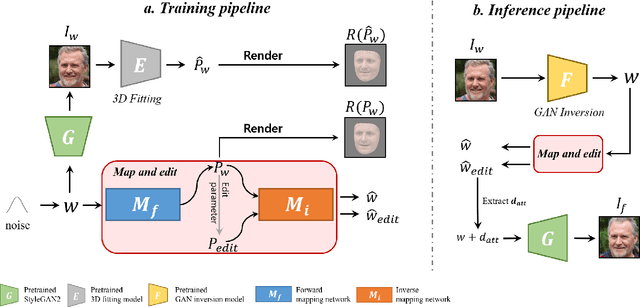
Although manipulating facial attributes by Generative Adversarial Networks (GANs) has been remarkably successful recently, there are still some challenges in explicit control of features such as pose, expression, lighting, etc. Recent methods achieve explicit control over 2D images by combining 2D generative model and 3DMM. However, due to the lack of realism and clarity in texture reconstruction by 3DMM, there is a domain gap between the synthetic image and the rendered image of 3DMM. Since rendered 3DMM images contain facial region only without the background, directly computing the loss between these two domains is not ideal and the resultant trained model will be biased. In this study, we propose to explicitly edit the latent space of the pretrained StyleGAN by controlling the parameters of the 3DMM. To address the domain gap problem, we propose a noval network called 'Map and edit' and a simple but effective attribute editing method to avoid direct loss computation between rendered and synthesized images. Furthermore, since our model can accurately generate multi-view face images while the identity remains unchanged. As a by-product, combined with visibility masks, our proposed model can also generate texture-rich and high-resolution UV facial textures. Our model relies on pretrained StyleGAN, and the proposed model is trained in a self-supervised manner without any manual annotations or datasets.