 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multi-domain Face Landmark Detection with Synthetic Data from Diffusion model
Jan 24, 2024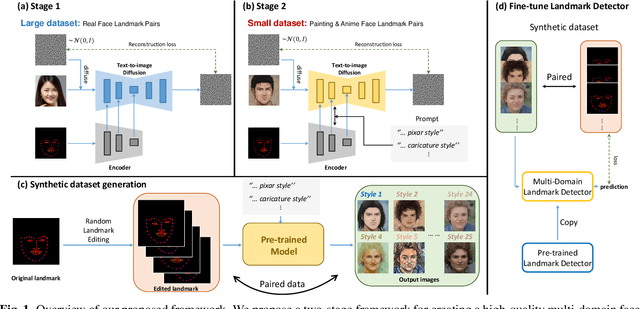
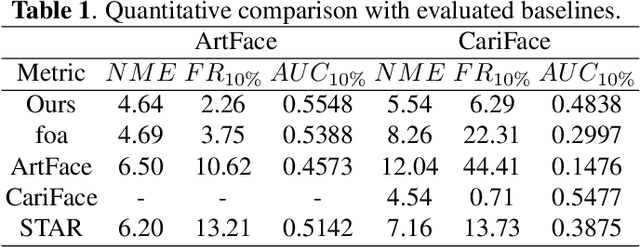

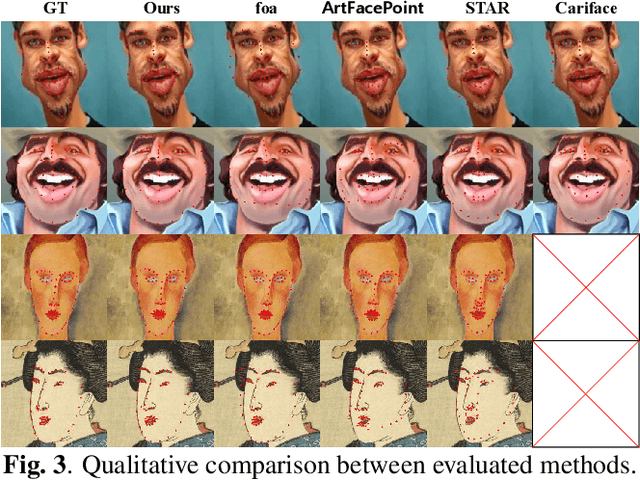
Recently, deep learning-based facial landmark detection for in-the-wild faces has achieved significant improvement. However, there are still challenges in face landmark detection in other domains (e.g. cartoon, caricature, etc). This is due to the scarcity of extensively annotated training data. To tackle this concern, we design a two-stage training approach that effectively leverages limited datasets and the pre-trained diffusion model to obtain aligned pairs of landmarks and face in multiple domains. In the first stage, we train a landmark-conditioned face generation model on a large dataset of real faces. In the second stage, we fine-tune the above model on a small dataset of image-landmark pairs with text prompts for controlling the domain. Our new designs enable our method to generate high-quality synthetic paired datasets from multiple domains while preserving the alignment between landmarks and facial features. Finally, we fine-tuned a pre-trained face landmark detection model on the synthetic dataset to achieve multi-domain face landmark detection. Our qualitative and quantitative results demonstrate that our method outperforms existing methods on multi-domain face landmark detection.
ViVid-1-to-3: Novel View Synthesis with Video Diffusion Models
Dec 03, 2023Generating novel views of an object from a single image is a challenging task. It requires an understanding of the underlying 3D structure of the object from an image and rendering high-quality, spatially consistent new views. While recent methods for view synthesis based on diffusion have shown great progress, achieving consistency among various view estimates and at the same time abiding by the desired camera pose remains a critical problem yet to be solved. In this work, we demonstrate a strikingly simple method, where we utilize a pre-trained video diffusion model to solve this problem. Our key idea is that synthesizing a novel view could be reformulated as synthesizing a video of a camera going around the object of interest -- a scanning video -- which then allows us to leverage the powerful priors that a video diffusion model would have learned. Thus, to perform novel-view synthesis, we create a smooth camera trajectory to the target view that we wish to render, and denoise using both a view-conditioned diffusion model and a video diffusion model. By doing so, we obtain a highly consistent novel view synthesis, outperforming the state of the art.
MPE4G: Multimodal Pretrained Encoder for Co-Speech Gesture Generation
May 25, 2023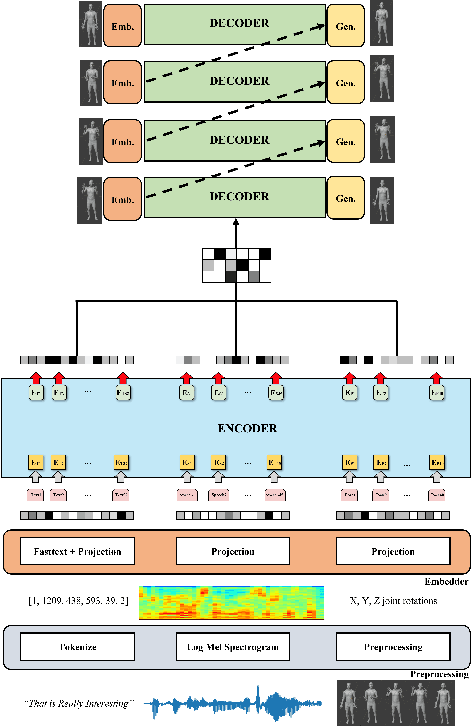
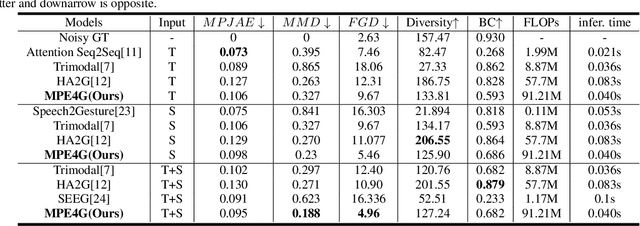
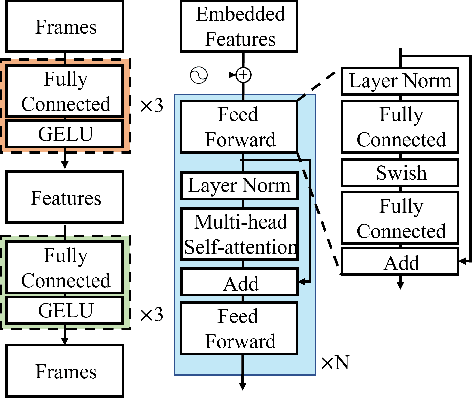
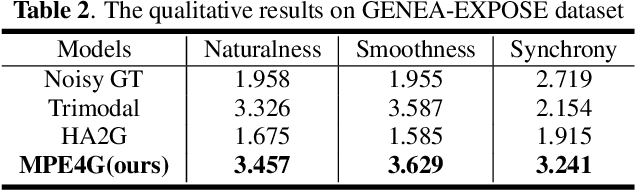
When virtual agents interact with humans, gestures are crucial to delivering their intentions with speech. Previous multimodal co-speech gesture generation models required encoded features of all modalities to generate gestures. If some input modalities are removed or contain noise, the model may not generate the gestures properly. To acquire robust and generalized encodings, we propose a novel framework with a multimodal pre-trained encoder for co-speech gesture generation. In the proposed method, the multi-head-attention-based encoder is trained with self-supervised learning to contain the information on each modality. Moreover, we collect full-body gestures that consist of 3D joint rotations to improve visualization and apply gestures to the extensible body model. Through the series of experiments and human evaluation, the proposed method renders realistic co-speech gestures not only when all input modalities are given but also when the input modalities are missing or noisy.
* 5 pages, 3 figures
Spatial-temporal Transformer-guided Diffusion based Data Augmentation for Efficient Skeleton-based Action Recognition
Feb 26, 2023Recently, skeleton-based human action has become a hot research topic because the compact representation of human skeletons brings new blood to this research domain. As a result, researchers began to notice the importance of using RGB or other sensors to analyze human action by extracting skeleton information. Leveraging the rapid development of deep learning (DL), a significant number of skeleton-based human action approaches have been presented with fine-designed DL structures recently. However, a well-trained DL model always demands high-quality and sufficient data, which is hard to obtain without costing high expenses and human labor. In this paper, we introduce a novel data augmentation method for skeleton-based action recognition tasks, which can effectively generate high-quality and diverse sequential actions. In order to obtain natural and realistic action sequences, we propose denoising diffusion probabilistic models (DDPMs) that can generate a series of synthetic action sequences, and their generation process is precisely guided by a spatial-temporal transformer (ST-Trans). Experimental results show that our method outperforms the state-of-the-art (SOTA) motion generation approaches on different naturality and diversity metrics. It proves that its high-quality synthetic data can also be effectively deployed to existing action recognition models with significant performance improvement.
DIFAI: Diverse Facial Inpainting using StyleGAN Inversion
Jan 20, 2023Image inpainting is an old problem in computer vision that restores occluded regions and completes damaged images. In the case of facial image inpainting, most of the methods generate only one result for each masked image, even though there are other reasonable possibilities. To prevent any potential biases and unnatural constraints stemming from generating only one image, we propose a novel framework for diverse facial inpainting exploiting the embedding space of StyleGAN. Our framework employs pSp encoder and SeFa algorithm to identify semantic components of the StyleGAN embeddings and feed them into our proposed SPARN decoder that adopts region normalization for plausible inpainting. We demonstrate that our proposed method outperforms several state-of-the-art methods.
Reference Guided Image Inpainting using Facial Attributes
Jan 19, 2023



Image inpainting is a technique of completing missing pixels such as occluded region restoration, distracting objects removal, and facial completion. Among these inpainting tasks, facial completion algorithm performs face inpainting according to the user direction. Existing approaches require delicate and well controlled input by the user, thus it is difficult for an average user to provide the guidance sufficiently accurate for the algorithm to generate desired results. To overcome this limitation, we propose an alternative user-guided inpainting architecture that manipulates facial attributes using a single reference image as the guide. Our end-to-end model consists of attribute extractors for accurate reference image attribute transfer and an inpainting model to map the attributes realistically and accurately to generated images. We customize MS-SSIM loss and learnable bidirectional attention maps in which importance structures remain intact even with irregular shaped masks. Based on our evaluation using the publicly available dataset CelebA-HQ, we demonstrate that the proposed method delivers superior performance compared to some state-of-the-art methods specialized in inpainting tasks.
Single Cell Training on Architecture Search for Image Denoising
Dec 13, 2022Neural Architecture Search (NAS) for automatically finding the optimal network architecture has shown some success with competitive performances in various computer vision tasks. However, NAS in general requires a tremendous amount of computations. Thus reducing computational cost has emerged as an important issue. Most of the attempts so far has been based on manual approaches, and often the architectures developed from such efforts dwell in the balance of the network optimality and the search cost. Additionally, recent NAS methods for image restoration generally do not consider dynamic operations that may transform dimensions of feature maps because of the dimensionality mismatch in tensor calculations. This can greatly limit NAS in its search for optimal network structure. To address these issues, we re-frame the optimal search problem by focusing at component block level. From previous work, it's been shown that an effective denoising block can be connected in series to further improve the network performance. By focusing at block level, the search space of reinforcement learning becomes significantly smaller and evaluation process can be conducted more rapidly. In addition, we integrate an innovative dimension matching modules for dealing with spatial and channel-wise mismatch that may occur in the optimal design search. This allows much flexibility in optimal network search within the cell block. With these modules, then we employ reinforcement learning in search of an optimal image denoising network at a module level. Computational efficiency of our proposed Denoising Prior Neural Architecture Search (DPNAS) was demonstrated by having it complete an optimal architecture search for an image restoration task by just one day with a single GPU.
3d human motion generation from the text via gesture action classification and the autoregressive model
Nov 18, 2022



In this paper, a deep learning-based model for 3D human motion generation from the text is proposed via gesture action classification and an autoregressive model. The model focuses on generating special gestures that express human thinking, such as waving and nodding. To achieve the goal, the proposed method predicts expression from the sentences using a text classification model based on a pretrained language model and generates gestures using the gate recurrent unit-based autoregressive model. Especially, we proposed the loss for the embedding space for restoring raw motions and generating intermediate motions well. Moreover, the novel data augmentation method and stop token are proposed to generate variable length motions. To evaluate the text classification model and 3D human motion generation model, a gesture action classification dataset and action-based gesture dataset are collected. With several experiments, the proposed method successfully generates perceptually natural and realistic 3D human motion from the text. Moreover, we verified the effectiveness of the proposed method using a public-available action recognition dataset to evaluate cross-dataset generalization performance.
Pose-Guided Graph Convolutional Networks for Skeleton-Based Action Recognition
Oct 10, 2022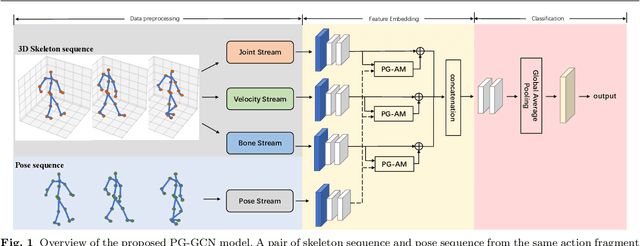
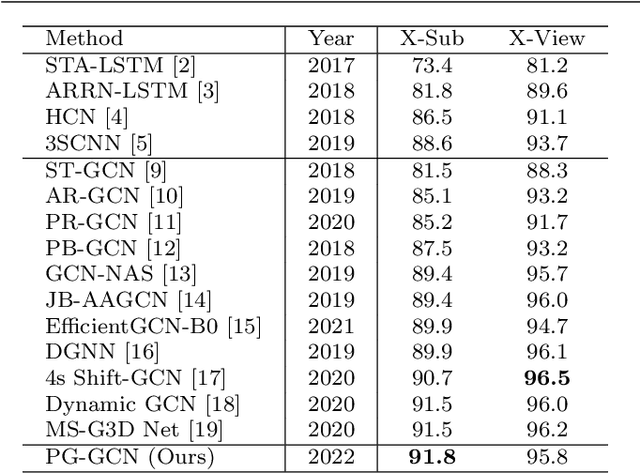
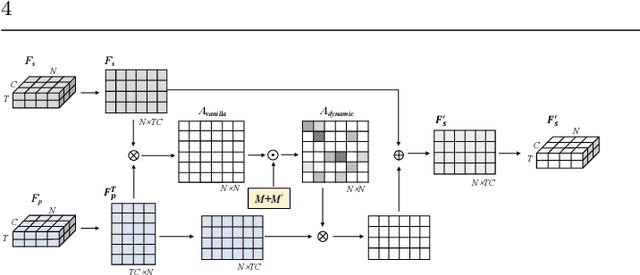
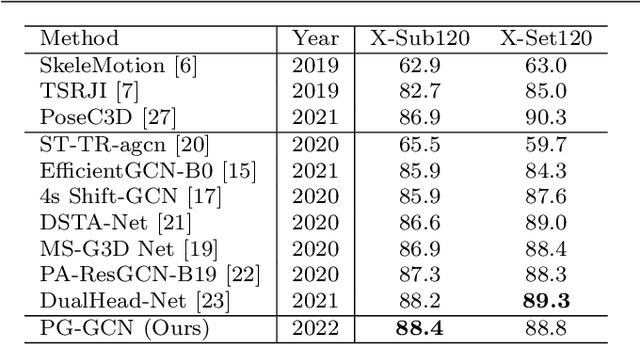
Graph convolutional networks (GCNs), which can model the human body skeletons as spatial and temporal graphs, have shown remarkable potential in skeleton-based action recognition. However, in the existing GCN-based methods, graph-structured representation of the human skeleton makes it difficult to be fused with other modalities, especially in the early stages. This may limit their scalability and performance in action recognition tasks. In addition, the pose information, which naturally contains informative and discriminative clues for action recognition, is rarely explored together with skeleton data in existing methods. In this work, we propose pose-guided GCN (PG-GCN), a multi-modal framework for high-performance human action recognition. In particular, a multi-stream network is constructed to simultaneously explore the robust features from both the pose and skeleton data, while a dynamic attention module is designed for early-stage feature fusion. The core idea of this module is to utilize a trainable graph to aggregate features from the skeleton stream with that of the pose stream, which leads to a network with more robust feature representation ability. Extensive experiments show that the proposed PG-GCN can achieve state-of-the-art performance on the NTU RGB+D 60 and NTU RGB+D 120 datasets.
Controllable Face Manipulation and UV Map Generation by Self-supervised Learning
Sep 24, 2022

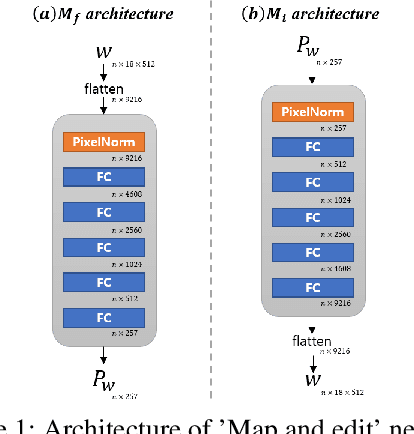
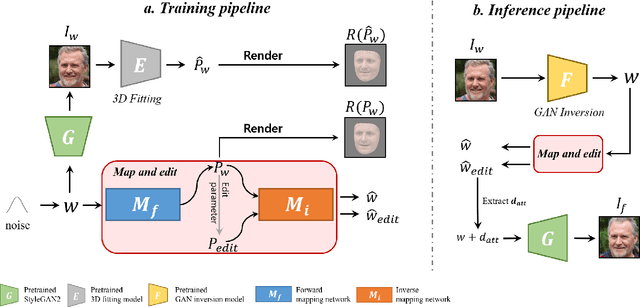
Although manipulating facial attributes by Generative Adversarial Networks (GANs) has been remarkably successful recently, there are still some challenges in explicit control of features such as pose, expression, lighting, etc. Recent methods achieve explicit control over 2D images by combining 2D generative model and 3DMM. However, due to the lack of realism and clarity in texture reconstruction by 3DMM, there is a domain gap between the synthetic image and the rendered image of 3DMM. Since rendered 3DMM images contain facial region only without the background, directly computing the loss between these two domains is not ideal and the resultant trained model will be biased. In this study, we propose to explicitly edit the latent space of the pretrained StyleGAN by controlling the parameters of the 3DMM. To address the domain gap problem, we propose a noval network called 'Map and edit' and a simple but effective attribute editing method to avoid direct loss computation between rendered and synthesized images. Furthermore, since our model can accurately generate multi-view face images while the identity remains unchanged. As a by-product, combined with visibility masks, our proposed model can also generate texture-rich and high-resolution UV facial textures. Our model relies on pretrained StyleGAN, and the proposed model is trained in a self-supervised manner without any manual annotations or datasets.