 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViVid-1-to-3: Novel View Synthesis with Video Diffusion Models
Dec 03, 2023Generating novel views of an object from a single image is a challenging task. It requires an understanding of the underlying 3D structure of the object from an image and rendering high-quality, spatially consistent new views. While recent methods for view synthesis based on diffusion have shown great progress, achieving consistency among various view estimates and at the same time abiding by the desired camera pose remains a critical problem yet to be solved. In this work, we demonstrate a strikingly simple method, where we utilize a pre-trained video diffusion model to solve this problem. Our key idea is that synthesizing a novel view could be reformulated as synthesizing a video of a camera going around the object of interest -- a scanning video -- which then allows us to leverage the powerful priors that a video diffusion model would have learned. Thus, to perform novel-view synthesis, we create a smooth camera trajectory to the target view that we wish to render, and denoise using both a view-conditioned diffusion model and a video diffusion model. By doing so, we obtain a highly consistent novel view synthesis, outperforming the state of the art.
Neural Fourier Filter Bank
Dec 04, 2022We present a novel method to provide efficient and highly detailed reconstructions. Inspired by wavelets, our main idea is to learn a neural field that decompose the signal both spatially and frequency-wise. We follow the recent grid-based paradigm for spatial decomposition, but unlike existing work, encourage specific frequencies to be stored in each grid via Fourier features encodings. We then apply a multi-layer perceptron with sine activations, taking these Fourier encoded features in at appropriate layers so that higher-frequency components are accumulated on top of lower-frequency components sequentially, which we sum up to form the final output. We demonstrate that our method outperforms the state of the art regarding model compactness and efficiency on multiple tasks: 2D image fitting, 3D shape reconstruction, and neural radiance fields.
TUSK: Task-Agnostic Unsupervised Keypoints
Jun 16, 2022
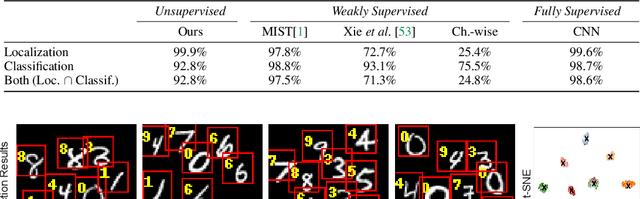
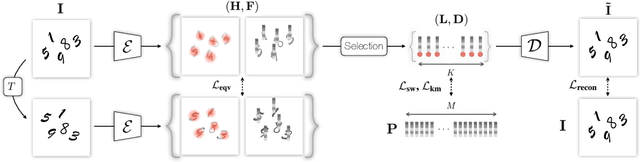

Existing unsupervised methods for keypoint learning rely heavily on the assumption that a specific keypoint type (e.g. elbow, digit, abstract geometric shape) appears only once in an image. This greatly limits their applicability, as each instance must be isolated before applying the method-an issue that is never discussed or evaluated. We thus propose a novel method to learn Task-agnostic, UnSupervised Keypoints (TUSK) which can deal with multiple instances. To achieve this, instead of the commonly-used strategy of detecting multiple heatmaps, each dedicated to a specific keypoint type, we use a single heatmap for detection, and enable unsupervised learning of keypoint types through clustering. Specifically, we encode semantics into the keypoints by teaching them to reconstruct images from a sparse set of keypoints and their descriptors, where the descriptors are forced to form distinct clusters in feature space around learned prototypes. This makes our approach amenable to a wider range of tasks than any previous unsupervised keypoint method: we show experiments on multiple-instance detection and classification, object discovery, and landmark detection-all unsupervised-with performance on par with the state of the art, while also being able to deal with multiple instances.
Layered Controllable Video Generation
Nov 24, 2021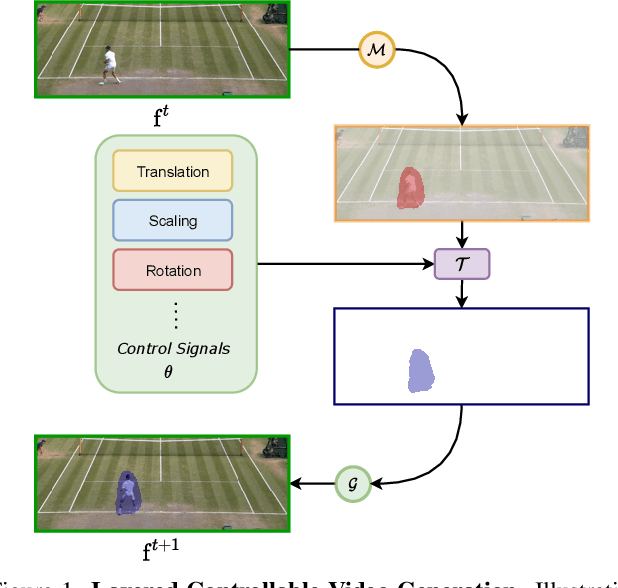
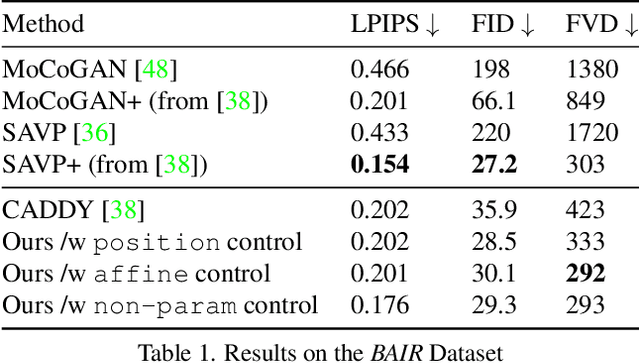

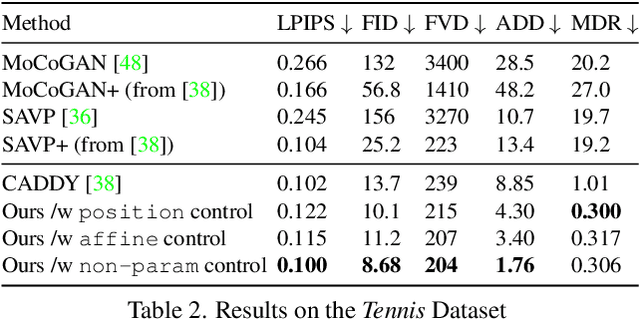
We introduce layered controllable video generation, where we, without any supervision, decompose the initial frame of a video into foreground and background layers, with which the user can control the video generation process by simply manipulating the foreground mask. The key challenges are the unsupervised foreground-background separation, which is ambiguous, and ability to anticipate user manipulations with access to only raw video sequences. We address these challenges by proposing a two-stage learning procedure. In the first stage, with the rich set of losses and dynamic foreground size prior, we learn how to separate the frame into foreground and background layers and, conditioned on these layers, how to generate the next frame using VQ-VAE generator. In the second stage, we fine-tune this network to anticipate edits to the mask, by fitting (parameterized) control to the mask from future frame. We demonstrate the effectiveness of this learning and the more granular control mechanism, while illustrating state-of-the-art performance on two benchmark datasets. We provide a video abstract as well as some video results on https://gabriel-huang.github.io/layered_controllable_video_generation
Image Matching across Wide Baselines: From Paper to Practice
Mar 03, 2020
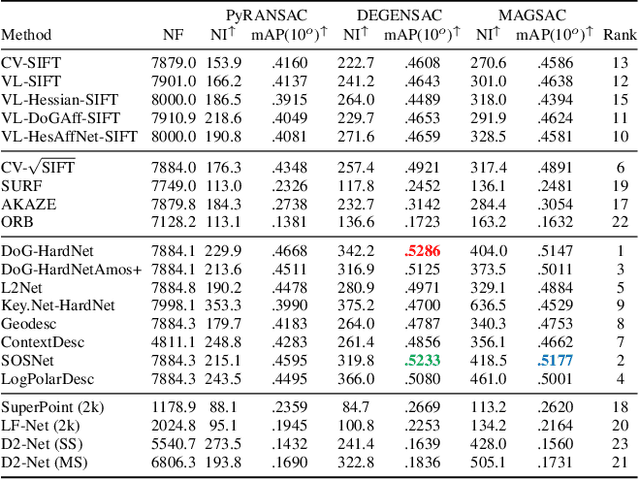

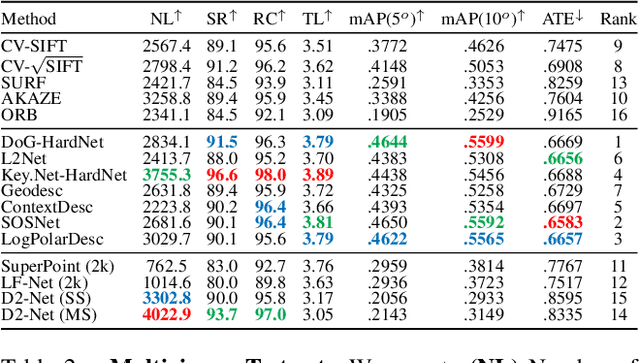
We introduce a comprehensive benchmark for local features and robust estimation algorithms, focusing on the downstream task -- the accuracy of the reconstructed camera pose -- as our primary metric. Our pipeline's modular structure allows us to easily integrate, configure, and combine methods and heuristics. We demonstrate this by embedding dozens of popular algorithms and evaluating them, from seminal works to the cutting edge of machine learning research. We show that with proper settings, classical solutions may still outperform the perceived state of the art. Besides establishing the actual state of the art, the experiments conducted in this paper reveal unexpected properties of SfM pipelines that can be exploited to help improve their performance, for both algorithmic and learned methods. Data and code are online https://github.com/vcg-uvic/image-matching-benchmark, providing an easy-to-use and flexible framework for the benchmarking of local feature and robust estimation methods, both alongside and against top-performing methods. This work provides the basis for an open challenge on wide-baseline image matching https://vision.uvic.ca/image-matching-challenge .