 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayered Controllable Video Generation
Paper and Code
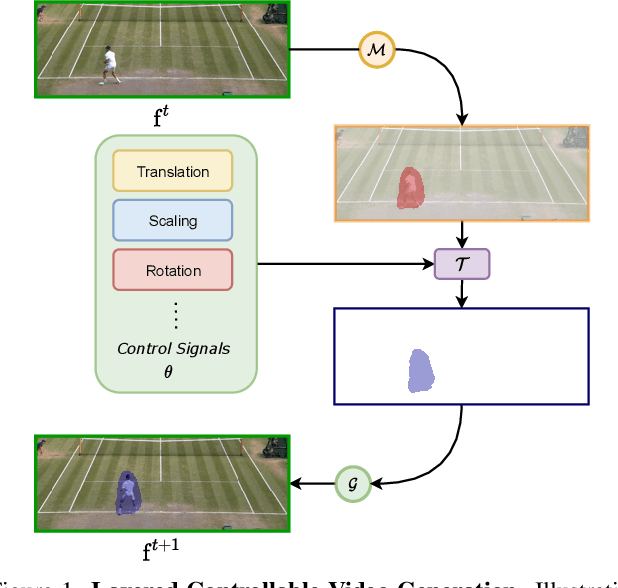
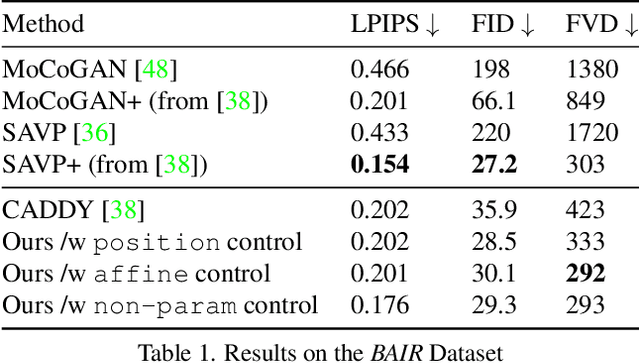

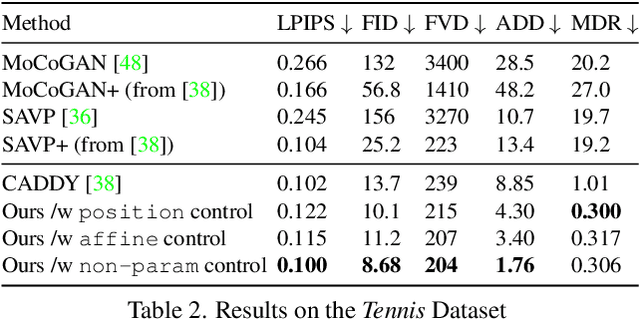
We introduce layered controllable video generation, where we, without any supervision, decompose the initial frame of a video into foreground and background layers, with which the user can control the video generation process by simply manipulating the foreground mask. The key challenges are the unsupervised foreground-background separation, which is ambiguous, and ability to anticipate user manipulations with access to only raw video sequences. We address these challenges by proposing a two-stage learning procedure. In the first stage, with the rich set of losses and dynamic foreground size prior, we learn how to separate the frame into foreground and background layers and, conditioned on these layers, how to generate the next frame using VQ-VAE generator. In the second stage, we fine-tune this network to anticipate edits to the mask, by fitting (parameterized) control to the mask from future frame. We demonstrate the effectiveness of this learning and the more granular control mechanism, while illustrating state-of-the-art performance on two benchmark datasets. We provide a video abstract as well as some video results on https://gabriel-huang.github.io/layered_controllable_video_generation