 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAM: Autonomous Discovery and Annotation Model using LLMs for Context-Aware Annotations
Jun 10, 2025Object detection models typically rely on predefined categories, limiting their ability to identify novel objects in open-world scenarios. To overcome this constraint, we introduce ADAM: Autonomous Discovery and Annotation Model, a training-free, self-refining framework for open-world object labeling. ADAM leverages large language models (LLMs) to generate candidate labels for unknown objects based on contextual information from known entities within a scene. These labels are paired with visual embeddings from CLIP to construct an Embedding-Label Repository (ELR) that enables inference without category supervision. For a newly encountered unknown object, ADAM retrieves visually similar instances from the ELR and applies frequency-based voting and cross-modal re-ranking to assign a robust label. To further enhance consistency, we introduce a self-refinement loop that re-evaluates repository labels using visual cohesion analysis and k-nearest-neighbor-based majority re-labeling. Experimental results on the COCO and PASCAL datasets demonstrate that ADAM effectively annotates novel categories using only visual and contextual signals, without requiring any fine-tuning or retraining.
3d human motion generation from the text via gesture action classification and the autoregressive model
Nov 18, 2022



In this paper, a deep learning-based model for 3D human motion generation from the text is proposed via gesture action classification and an autoregressive model. The model focuses on generating special gestures that express human thinking, such as waving and nodding. To achieve the goal, the proposed method predicts expression from the sentences using a text classification model based on a pretrained language model and generates gestures using the gate recurrent unit-based autoregressive model. Especially, we proposed the loss for the embedding space for restoring raw motions and generating intermediate motions well. Moreover, the novel data augmentation method and stop token are proposed to generate variable length motions. To evaluate the text classification model and 3D human motion generation model, a gesture action classification dataset and action-based gesture dataset are collected. With several experiments, the proposed method successfully generates perceptually natural and realistic 3D human motion from the text. Moreover, we verified the effectiveness of the proposed method using a public-available action recognition dataset to evaluate cross-dataset generalization performance.
Efficient dynamic filter for robust and low computational feature extraction
May 03, 2022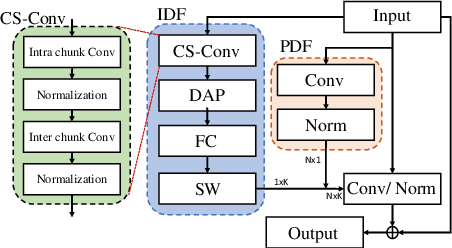
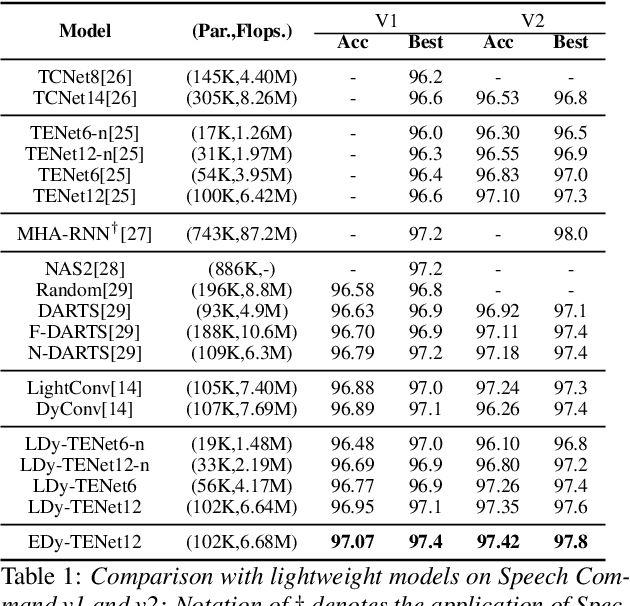
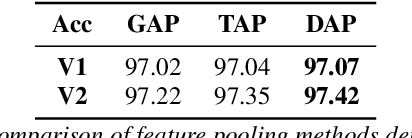
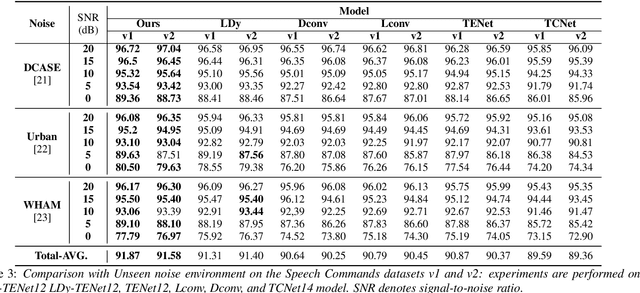
Unseen noise signal which is not considered in a model training process is difficult to anticipate and would lead to performance degradation. Various methods have been investigated to mitigate unseen noise. In our previous work, an Instance-level Dynamic Filter (IDF) and a Pixel Dynamic Filter (PDF) were proposed to extract noise-robust features. However, the performance of the dynamic filter might be degraded since simple feature pooling is used to reduce the computational resource in the IDF part. In this paper, we propose an efficient dynamic filter to enhance the performance of the dynamic filter. Instead of utilizing the simple feature mean, we separate Time-Frequency (T-F) features as non-overlapping chunks, and separable convolutions are carried out for each feature direction (inter chunks and intra chunks). Additionally, we propose Dynamic Attention Pooling that maps high dimensional features as low dimensional feature embeddings. These methods are applied to the IDF for keyword spotting and speaker verification tasks. We confirm that our proposed method performs better in unseen environments (unseen noise and unseen speakers) than state-of-the-art models.
Lightweight dynamic filter for keyword spotting
Sep 27, 2021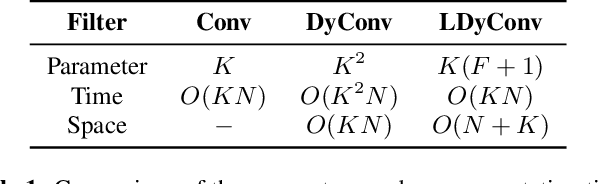
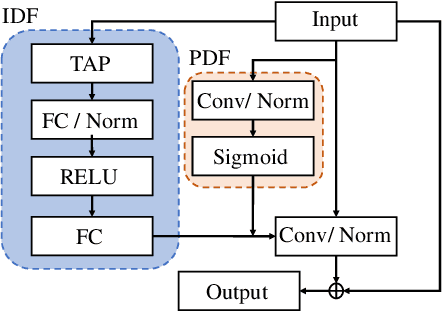
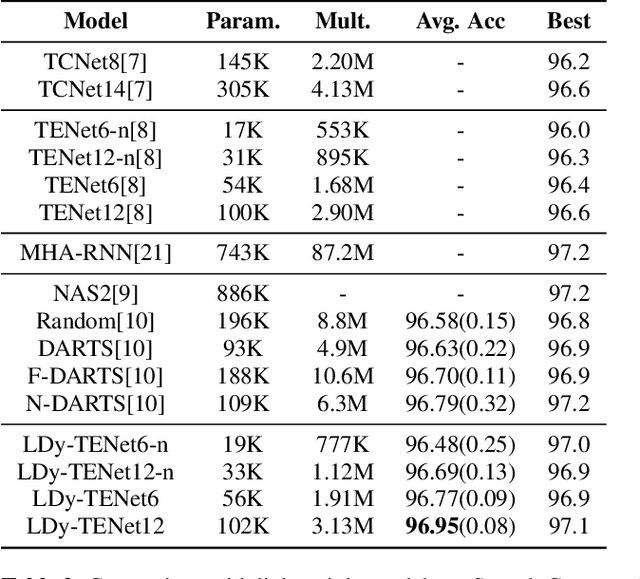
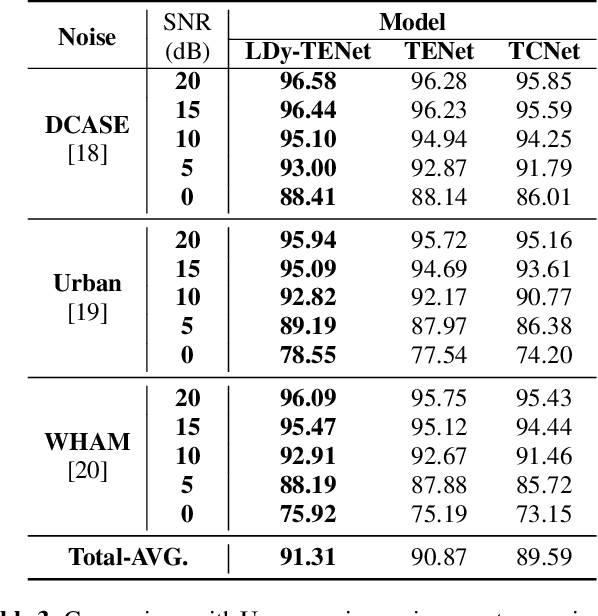
Keyword Spotting (KWS) from speech signal is widely applied for being fully hands free speech recognition. The KWS network is designed as a small footprint model to be constantly monitored. Recently, dynamic filter based models are applied in deep learning applications to enhance a system's robustness or accuracy. However, as a dynamic filter framework requires high computational cost, the usage is limited to the condition of the device. In this paper, we proposed a lightweight dynamic filter to improve the performance of KWS. Our proposed model divides dynamic filter as two branches to reduce the computational complexity. This lightweight dynamic filter is applied to the front-end of KWS to enhance the separability of the input data. The experiments show that our model is robustly working on unseen noise and small training data environment by using small computational resource.
Memory-based Semantic Segmentation for Off-road Unstructured Natural Environments
Aug 18, 2021

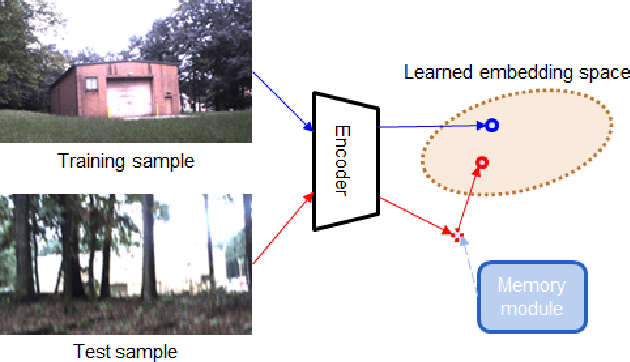
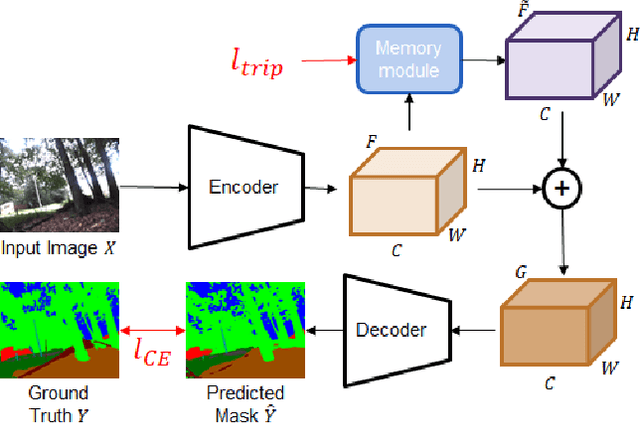
With the availability of many datasets tailored for autonomous driving in real-world urban scenes, semantic segmentation for urban driving scenes achieves significant progress. However, semantic segmentation for off-road, unstructured environments is not widely studied. Directly applying existing segmentation networks often results in performance degradation as they cannot overcome intrinsic problems in such environments, such as illumination changes. In this paper, a built-in memory module for semantic segmentation is proposed to overcome these problems. The memory module stores significant representations of training images as memory items. In addition to the encoder embedding like items together, the proposed memory module is specifically designed to cluster together instances of the same class even when there are significant variances in embedded features. Therefore, it makes segmentation networks better deal with unexpected illumination changes. A triplet loss is used in training to minimize redundancy in storing discriminative representations of the memory module. The proposed memory module is general so that it can be adopted in a variety of networks. We conduct experiments on the Robot Unstructured Ground Driving (RUGD) dataset and RELLIS dataset, which are collected from off-road, unstructured natural environments. Experimental results show that the proposed memory module improves the performance of existing segmentation networks and contributes to capturing unclear objects over various off-road, unstructured natural scenes with equivalent computational cost and network parameters. As the proposed method can be integrated into compact networks, it presents a viable approach for resource-limited small autonomous platforms.
Cross-Referencing Self-Training Network for Sound Event Detection in Audio Mixtures
May 27, 2021
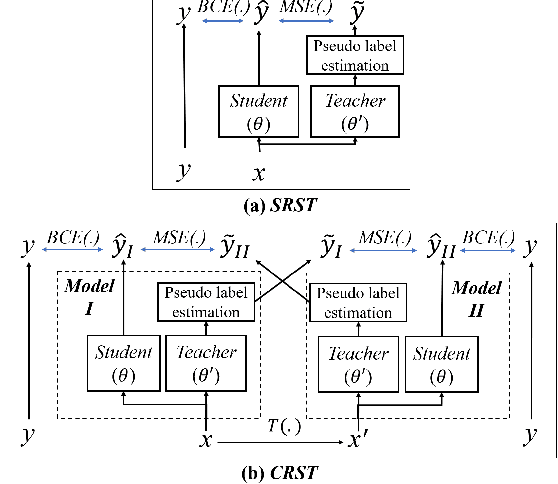
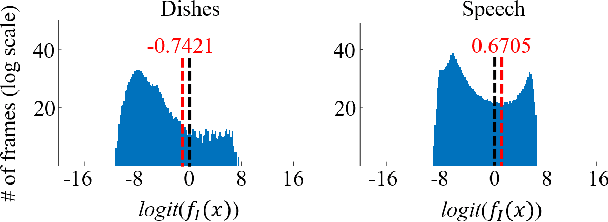
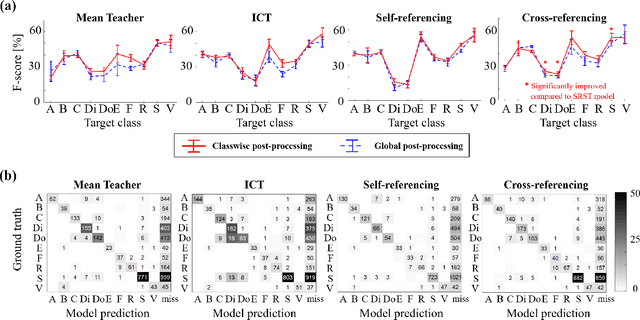
Sound event detection is an important facet of audio tagging that aims to identify sounds of interest and define both the sound category and time boundaries for each sound event in a continuous recording. With advances in deep neural networks, there has been tremendous improvement in the performance of sound event detection systems, although at the expense of costly data collection and labeling efforts. In fact, current state-of-the-art methods employ supervised training methods that leverage large amounts of data samples and corresponding labels in order to facilitate identification of sound category and time stamps of events. As an alternative, the current study proposes a semi-supervised method for generating pseudo-labels from unsupervised data using a student-teacher scheme that balances self-training and cross-training. Additionally, this paper explores post-processing which extracts sound intervals from network prediction, for further improvement in sound event detection performance. The proposed approach is evaluated on sound event detection task for the DCASE2020 challenge. The results of these methods on both "validation" and "public evaluation" sets of DESED database show significant improvement compared to the state-of-the art systems in semi-supervised learning.
Few-shot Learning for CT Scan based COVID-19 Diagnosis
Feb 01, 2021
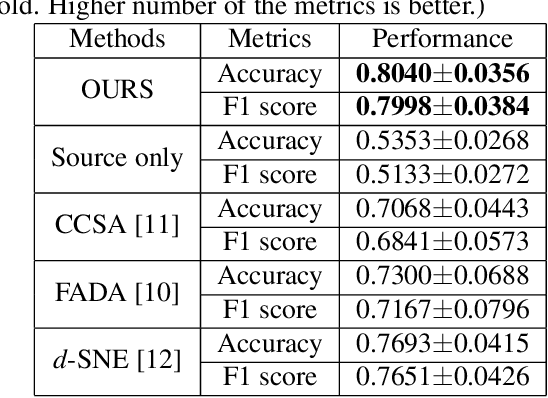

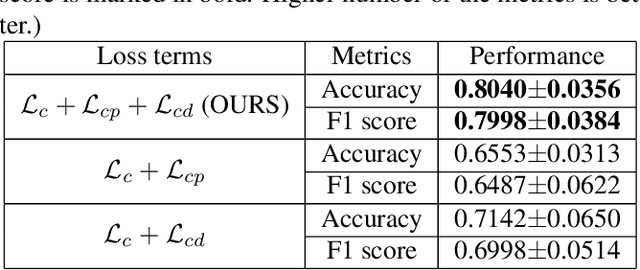
Coronavirus disease 2019 (COVID-19) is a Public Health Emergency of International Concern infecting more than 40 million people across 188 countries and territories. Chest computed tomography (CT) imaging technique benefits from its high diagnostic accuracy and robustness, it has become an indispensable way for COVID-19 mass testing. Recently, deep learning approaches have become an effective tool for automatic screening of medical images, and it is also being considered for COVID-19 diagnosis. However, the high infection risk involved with COVID-19 leads to relative sparseness of collected labeled data limiting the performance of such methodologies. Moreover, accurately labeling CT images require expertise of radiologists making the process expensive and time-consuming. In order to tackle the above issues, we propose a supervised domain adaption based COVID-19 CT diagnostic method which can perform effectively when only a small samples of labeled CT scans are available. To compensate for the sparseness of labeled data, the proposed method utilizes a large amount of synthetic COVID-19 CT images and adjusts the networks from the source domain (synthetic data) to the target domain (real data) with a cross-domain training mechanism. Experimental results show that the proposed method achieves state-of-the-art performance on few-shot COVID-19 CT imaging based diagnostic tasks.
CAFE-GAN: Arbitrary Face Attribute Editing with Complementary Attention Feature
Nov 24, 2020


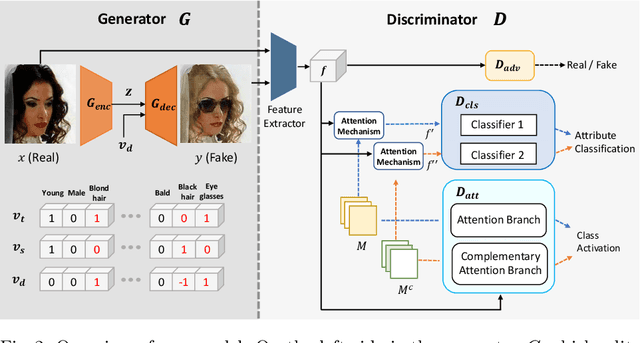
The goal of face attribute editing is altering a facial image according to given target attributes such as hair color, mustache, gender, etc. It belongs to the image-to-image domain transfer problem with a set of attributes considered as a distinctive domain. There have been some works in multi-domain transfer problem focusing on facial attribute editing employing Generative Adversarial Network (GAN). These methods have reported some successes but they also result in unintended changes in facial regions - meaning the generator alters regions unrelated to the specified attributes. To address this unintended altering problem, we propose a novel GAN model which is designed to edit only the parts of a face pertinent to the target attributes by the concept of Complementary Attention Feature (CAFE). CAFE identifies the facial regions to be transformed by considering both target attributes as well as complementary attributes, which we define as those attributes absent in the input facial image. In addition, we introduce a complementary feature matching to help in training the generator for utilizing the spatial information of attributes. Effectiveness of the proposed method is demonstrated by analysis and comparison study with state-of-the-art methods.
Correlation Distance Skip Connection Denoising Autoencoder (CDSK-DAE) for Speech Feature Enhancement
Jul 26, 2019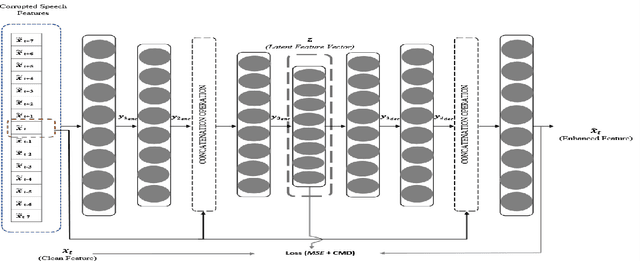

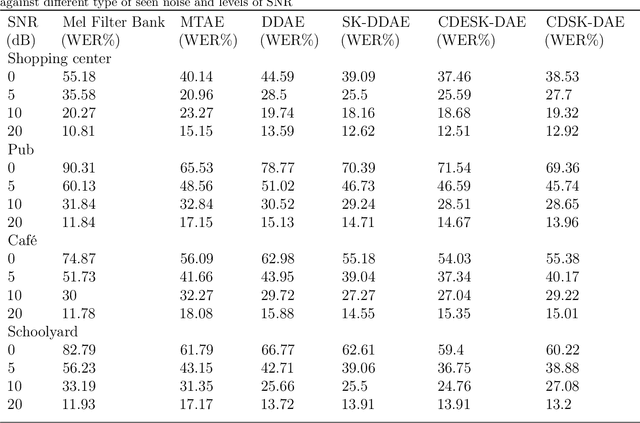
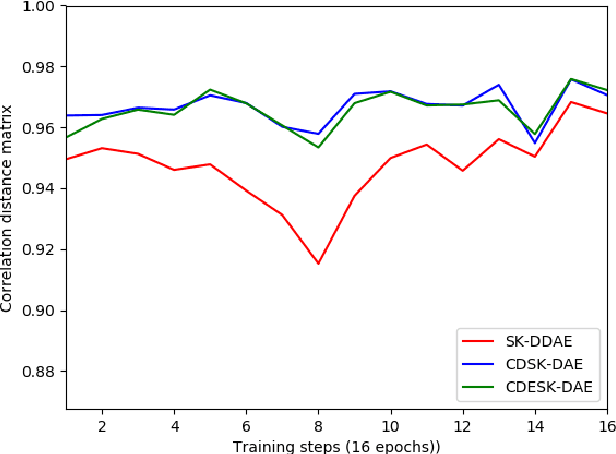
Performance of learning based Automatic Speech Recognition (ASR) is susceptible to noise, especially when it is introduced in the testing data while not presented in the training data. This work focuses on a feature enhancement for noise robust end-to-end ASR system by introducing a novel variant of denoising autoencoder (DAE). The proposed method uses skip connections in both encoder and decoder sides by passing speech information of the target frame from input to the model. It also uses a new objective function in training model that uses a correlation distance measure in penalty terms by measuring dependency of the latent target features and the model (latent features and enhanced features obtained from the DAE). Performance of the proposed method was compared against a conventional model and a state of the art model under both seen and unseen noisy environments of 7 different types of background noise with different SNR levels (0, 5, 10 and 20 dB). The proposed method also is tested using linear and non-linear penalty terms as well, where, they both show an improvement on the overall average WER under noisy conditions both seen and unseen in comparison to the state-of-the-art model.
Sinusoidal wave generating network based on adversarial learning and its application: synthesizing frog sounds for data augmentation
Jan 07, 2019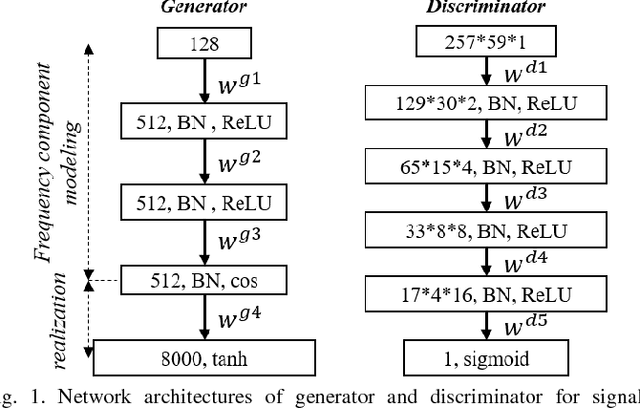
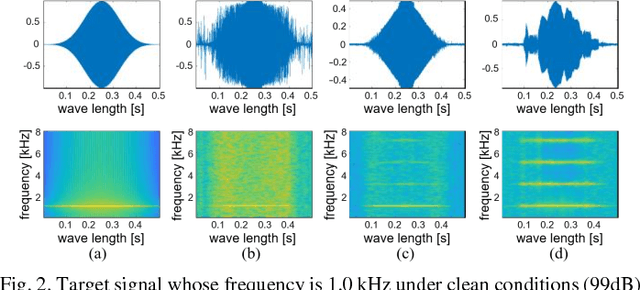
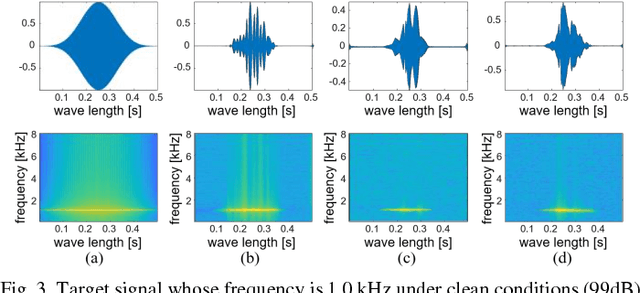
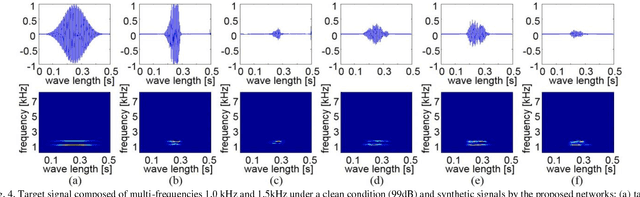
Simulators that generate observations based on theoretical models can be important tools for development, prediction, and assessment of signal processing algorithms. In order to design these simulators, painstaking effort is required to construct mathematical models according to their application. Complex models are sometimes necessary to represent a variety of real phenomena. In contrast, obtaining synthetic observations from generative models developed from real observations often require much less effort. This paper proposes a generative model based on adversarial learning. Given that observations are typically signals composed of a linear combination of sinusoidal waves and random noises, sinusoidal wave generating networks are first designed based on an adversarial network. Audio waveform generation can then be performed using the proposed network. Several approaches to designing the objective function of the proposed network using adversarial learning are investigated experimentally. In addition, amphibian sound classification is performed using a convolutional neural network trained with real and synthetic sounds. Both qualitative and quantitative results show that the proposed generative model makes realistic signals and is very helpful for data augmentation and data analysis.