 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden costs for inference with deep network on embedded system devices
Jan 05, 2026This study evaluates the inference performance of various deep learning models under an embedded system environment. In previous works, Multiply-Accumulate operation is typically used to measure computational load of a deep model. According to this study, however, this metric has a limitation to estimate inference time on embedded devices. This paper poses the question of what aspects are overlooked when expressed in terms of Multiply-Accumulate operations. In experiments, an image classification task is performed on an embedded system device using the CIFAR-100 dataset to compare and analyze the inference times of ten deep models with the theoretically calculated Multiply-Accumulate operations for each model. The results highlight the importance of considering additional computations between tensors when optimizing deep learning models for real-time performing in embedded systems.
Cross-Referencing Self-Training Network for Sound Event Detection in Audio Mixtures
May 27, 2021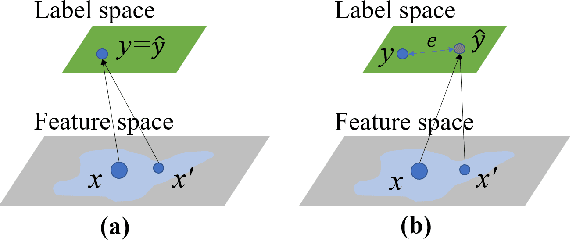
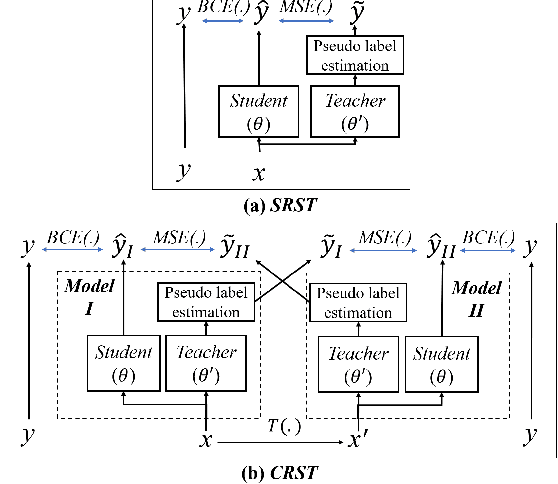
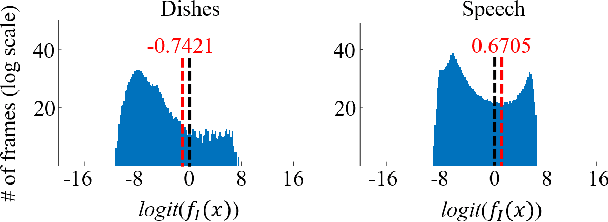
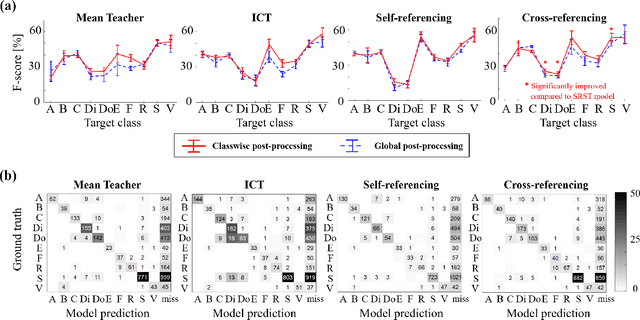
Sound event detection is an important facet of audio tagging that aims to identify sounds of interest and define both the sound category and time boundaries for each sound event in a continuous recording. With advances in deep neural networks, there has been tremendous improvement in the performance of sound event detection systems, although at the expense of costly data collection and labeling efforts. In fact, current state-of-the-art methods employ supervised training methods that leverage large amounts of data samples and corresponding labels in order to facilitate identification of sound category and time stamps of events. As an alternative, the current study proposes a semi-supervised method for generating pseudo-labels from unsupervised data using a student-teacher scheme that balances self-training and cross-training. Additionally, this paper explores post-processing which extracts sound intervals from network prediction, for further improvement in sound event detection performance. The proposed approach is evaluated on sound event detection task for the DCASE2020 challenge. The results of these methods on both "validation" and "public evaluation" sets of DESED database show significant improvement compared to the state-of-the art systems in semi-supervised learning.
Correlation Distance Skip Connection Denoising Autoencoder (CDSK-DAE) for Speech Feature Enhancement
Jul 26, 2019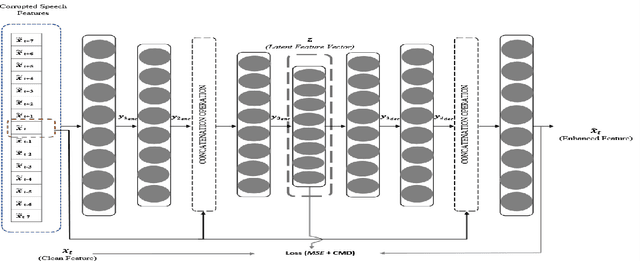

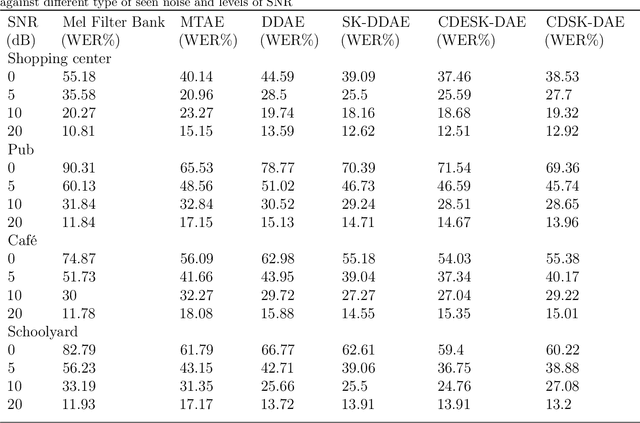
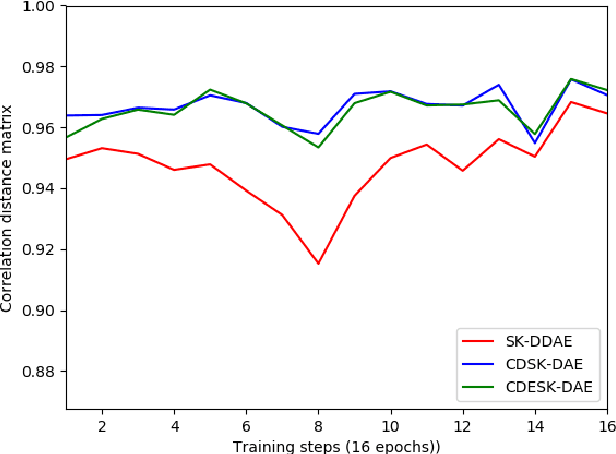
Performance of learning based Automatic Speech Recognition (ASR) is susceptible to noise, especially when it is introduced in the testing data while not presented in the training data. This work focuses on a feature enhancement for noise robust end-to-end ASR system by introducing a novel variant of denoising autoencoder (DAE). The proposed method uses skip connections in both encoder and decoder sides by passing speech information of the target frame from input to the model. It also uses a new objective function in training model that uses a correlation distance measure in penalty terms by measuring dependency of the latent target features and the model (latent features and enhanced features obtained from the DAE). Performance of the proposed method was compared against a conventional model and a state of the art model under both seen and unseen noisy environments of 7 different types of background noise with different SNR levels (0, 5, 10 and 20 dB). The proposed method also is tested using linear and non-linear penalty terms as well, where, they both show an improvement on the overall average WER under noisy conditions both seen and unseen in comparison to the state-of-the-art model.
Sinusoidal wave generating network based on adversarial learning and its application: synthesizing frog sounds for data augmentation
Jan 07, 2019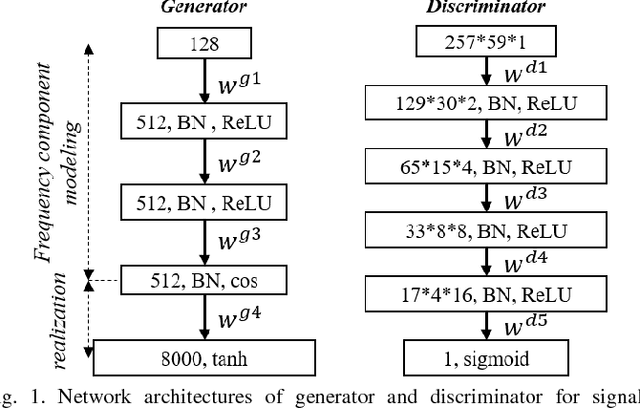
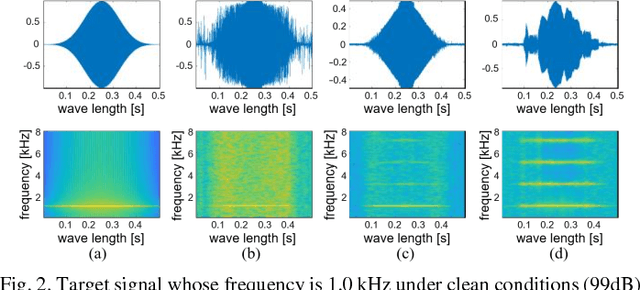
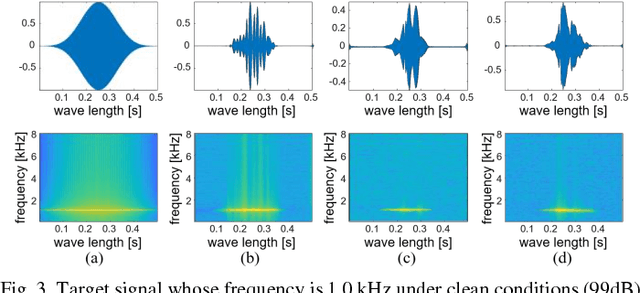
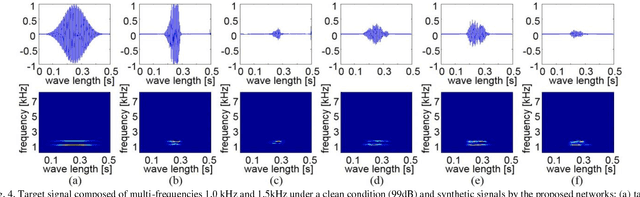
Simulators that generate observations based on theoretical models can be important tools for development, prediction, and assessment of signal processing algorithms. In order to design these simulators, painstaking effort is required to construct mathematical models according to their application. Complex models are sometimes necessary to represent a variety of real phenomena. In contrast, obtaining synthetic observations from generative models developed from real observations often require much less effort. This paper proposes a generative model based on adversarial learning. Given that observations are typically signals composed of a linear combination of sinusoidal waves and random noises, sinusoidal wave generating networks are first designed based on an adversarial network. Audio waveform generation can then be performed using the proposed network. Several approaches to designing the objective function of the proposed network using adversarial learning are investigated experimentally. In addition, amphibian sound classification is performed using a convolutional neural network trained with real and synthetic sounds. Both qualitative and quantitative results show that the proposed generative model makes realistic signals and is very helpful for data augmentation and data analysis.