 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer
Sep 17, 2024Latent diffusion models have shown promising results in text-to-audio (T2A) generation tasks, yet previous models have encountered difficulties in generation quality, computational cost, diffusion sampling, and data preparation. In this paper, we introduce EzAudio, a transformer-based T2A diffusion model, to handle these challenges. Our approach includes several key innovations: (1) We build the T2A model on the latent space of a 1D waveform Variational Autoencoder (VAE), avoiding the complexities of handling 2D spectrogram representations and using an additional neural vocoder. (2) We design an optimized diffusion transformer architecture specifically tailored for audio latent representations and diffusion modeling, which enhances convergence speed, training stability, and memory usage, making the training process easier and more efficient. (3) To tackle data scarcity, we adopt a data-efficient training strategy that leverages unlabeled data for learning acoustic dependencies, audio caption data annotated by audio-language models for text-to-audio alignment learning, and human-labeled data for fine-tuning. (4) We introduce a classifier-free guidance (CFG) rescaling method that simplifies EzAudio by achieving strong prompt alignment while preserving great audio quality when using larger CFG scores, eliminating the need to struggle with finding the optimal CFG score to balance this trade-off. EzAudio surpasses existing open-source models in both objective metrics and subjective evaluations, delivering realistic listening experiences while maintaining a streamlined model structure, low training costs, and an easy-to-follow training pipeline. Code, data, and pre-trained models are released at: https://haidog-yaqub.github.io/EzAudio-Page/.
SoloAudio: Target Sound Extraction with Language-oriented Audio Diffusion Transformer
Sep 12, 2024In this paper, we introduce SoloAudio, a novel diffusion-based generative model for target sound extraction (TSE). Our approach trains latent diffusion models on audio, replacing the previous U-Net backbone with a skip-connected Transformer that operates on latent features. SoloAudio supports both audio-oriented and language-oriented TSE by utilizing a CLAP model as the feature extractor for target sounds. Furthermore, SoloAudio leverages synthetic audio generated by state-of-the-art text-to-audio models for training, demonstrating strong generalization to out-of-domain data and unseen sound events. We evaluate this approach on the FSD Kaggle 2018 mixture dataset and real data from AudioSet, where SoloAudio achieves the state-of-the-art results on both in-domain and out-of-domain data, and exhibits impressive zero-shot and few-shot capabilities. Source code and demos are released.
DreamVoice: Text-Guided Voice Conversion
Jun 24, 2024


Generative voice technologies are rapidly evolving, offering opportunities for more personalized and inclusive experiences. Traditional one-shot voice conversion (VC) requires a target recording during inference, limiting ease of usage in generating desired voice timbres. Text-guided generation offers an intuitive solution to convert voices to desired "DreamVoices" according to the users' needs. Our paper presents two major contributions to VC technology: (1) DreamVoiceDB, a robust dataset of voice timbre annotations for 900 speakers from VCTK and LibriTTS. (2) Two text-guided VC methods: DreamVC, an end-to-end diffusion-based text-guided VC model; and DreamVG, a versatile text-to-voice generation plugin that can be combined with any one-shot VC models. The experimental results demonstrate that our proposed methods trained on the DreamVoiceDB dataset generate voice timbres accurately aligned with the text prompt and achieve high-quality VC.
Investigating Self-Supervised Deep Representations for EEG-based Auditory Attention Decoding
Nov 07, 2023



Auditory Attention Decoding (AAD) algorithms play a crucial role in isolating desired sound sources within challenging acoustic environments directly from brain activity. Although recent research has shown promise in AAD using shallow representations such as auditory envelope and spectrogram, there has been limited exploration of deep Self-Supervised (SS) representations on a larger scale. In this study, we undertake a comprehensive investigation into the performance of linear decoders across 12 deep and 2 shallow representations, applied to EEG data from multiple studies spanning 57 subjects and multiple languages. Our experimental results consistently reveal the superiority of deep features for AAD at decoding background speakers, regardless of the datasets and analysis windows. This result indicates possible nonlinear encoding of unattended signals in the brain that are revealed using deep nonlinear features. Additionally, we analyze the impact of different layers of SS representations and window sizes on AAD performance. These findings underscore the potential for enhancing EEG-based AAD systems through the integration of deep feature representations.
DPM-TSE: A Diffusion Probabilistic Model for Target Sound Extraction
Oct 10, 2023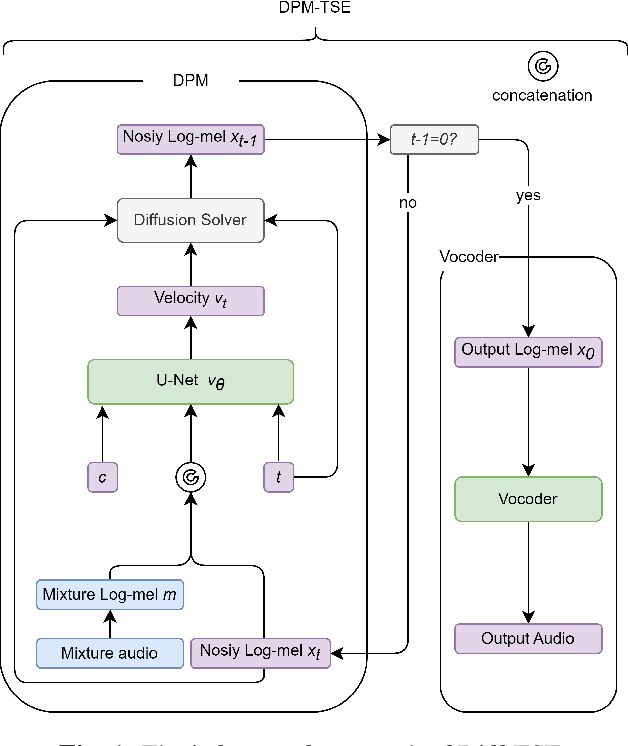
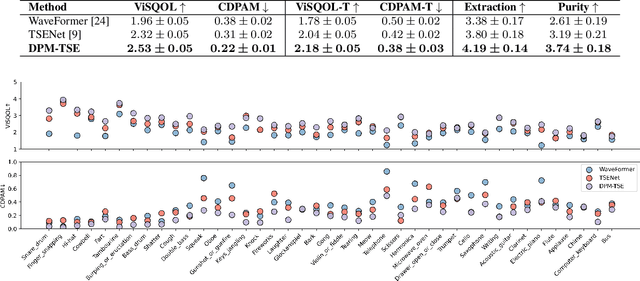

Common target sound extraction (TSE) approaches primarily relied on discriminative approaches in order to separate the target sound while minimizing interference from the unwanted sources, with varying success in separating the target from the background. This study introduces DPM-TSE, a first generative method based on diffusion probabilistic modeling (DPM) for target sound extraction, to achieve both cleaner target renderings as well as improved separability from unwanted sounds. The technique also tackles common background noise issues with DPM by introducing a correction method for noise schedules and sample steps. This approach is evaluated using both objective and subjective quality metrics on the FSD Kaggle 2018 dataset. The results show that DPM-TSE has a significant improvement in perceived quality in terms of target extraction and purity.
Cross-Referencing Self-Training Network for Sound Event Detection in Audio Mixtures
May 27, 2021
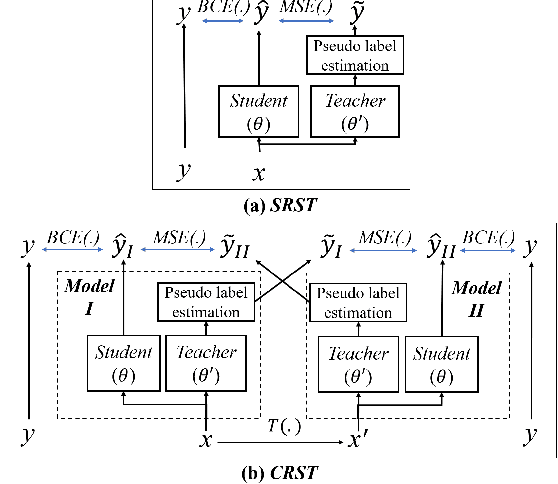
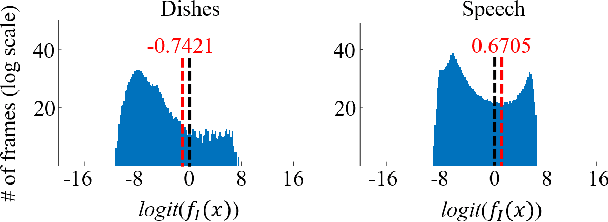
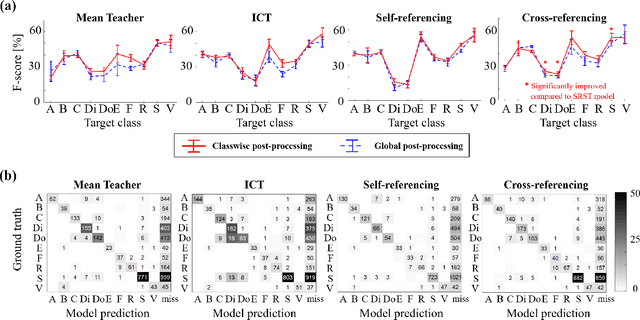
Sound event detection is an important facet of audio tagging that aims to identify sounds of interest and define both the sound category and time boundaries for each sound event in a continuous recording. With advances in deep neural networks, there has been tremendous improvement in the performance of sound event detection systems, although at the expense of costly data collection and labeling efforts. In fact, current state-of-the-art methods employ supervised training methods that leverage large amounts of data samples and corresponding labels in order to facilitate identification of sound category and time stamps of events. As an alternative, the current study proposes a semi-supervised method for generating pseudo-labels from unsupervised data using a student-teacher scheme that balances self-training and cross-training. Additionally, this paper explores post-processing which extracts sound intervals from network prediction, for further improvement in sound event detection performance. The proposed approach is evaluated on sound event detection task for the DCASE2020 challenge. The results of these methods on both "validation" and "public evaluation" sets of DESED database show significant improvement compared to the state-of-the art systems in semi-supervised learning.