 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Diffusion Refinement for Multi-Channel Speech Enhancement and Separation
Mar 25, 2026We propose Uni-ArrayDPS, a novel diffusion-based refinement framework for unified multi-channel speech enhancement and separation. Existing methods for multi-channel speech enhancement/separation are mostly discriminative and are highly effective at producing high-SNR outputs. However, they can still generate unnatural speech with non-linear distortions caused by the neural network and regression-based objectives. To address this issue, we propose Uni-ArrayDPS, which refines the outputs of any strong discriminative model using a speech diffusion prior. Uni-ArrayDPS is generative, array-agnostic, and training-free, and supports both enhancement and separation. Given a discriminative model's enhanced/separated speech, we use it, together with the noisy mixtures, to estimate the noise spatial covariance matrix (SCM). We then use this SCM to compute the likelihood required for diffusion posterior sampling of the clean speech source(s). Uni-ArrayDPS requires only a pre-trained clean-speech diffusion model as a prior and does not require additional training or fine-tuning, allowing it to generalize directly across tasks (enhancement/separation), microphone array geometries, and discriminative model backbones. Extensive experiments show that Uni-ArrayDPS consistently improves a wide range of discriminative models for both enhancement and separation tasks. We also report strong results on a real-world dataset. Audio demos are provided at \href{https://xzwy.github.io/Uni-ArrayDPS/}{https://xzwy.github.io/Uni-ArrayDPS/}.
ArrayDPS-Refine: Generative Refinement of Discriminative Multi-Channel Speech Enhancement
Mar 25, 2026Multi-channel speech enhancement aims to recover clean speech from noisy multi-channel recordings. Most deep learning methods employ discriminative training, which can lead to non-linear distortions from regression-based objectives, especially under challenging environmental noise conditions. Inspired by ArrayDPS for unsupervised multi-channel source separation, we introduce ArrayDPS-Refine, a method designed to enhance the outputs of discriminative models using a clean speech diffusion prior. ArrayDPS-Refine is training-free, generative, and array-agnostic. It first estimates the noise spatial covariance matrix (SCM) from the enhanced speech produced by a discriminative model, then uses this estimated noise SCM for diffusion posterior sampling. This approach allows direct refinement of any discriminative model's output without retraining. Our results show that ArrayDPS-Refine consistently improves the performance of various discriminative models, including state-of-the-art waveform and STFT domain models. Audio demos are provided at https://xzwy.github.io/ArrayDPSRefineDemo/.
AVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
Contrastive Diffusion Guidance for Spatial Inverse Problems
Sep 30, 2025

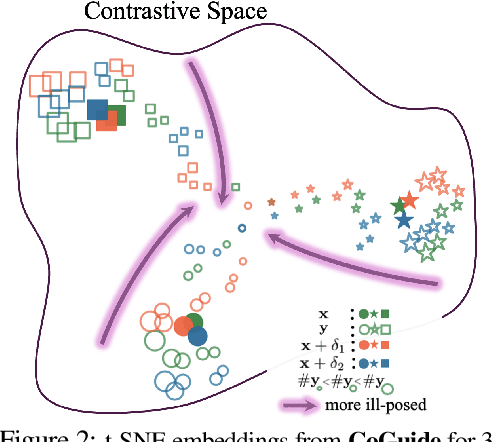

We consider the inverse problem of reconstructing the spatial layout of a place, a home floorplan for example, from a user`s movements inside that layout. Direct inversion is ill-posed since many floorplans can explain the same movement trajectories. We adopt a diffusion-based posterior sampler to generate layouts consistent with the measurements. While active research is in progress on generative inverse solvers, we find that the forward operator in our problem poses new challenges. The path-planning process inside a floorplan is a non-invertible, non-differentiable function, and causes instability while optimizing using the likelihood score. We break-away from existing approaches and reformulate the likelihood score in a smoother embedding space. The embedding space is trained with a contrastive loss which brings compatible floorplans and trajectories close to each other, while pushing mismatched pairs far apart. We show that a surrogate form of the likelihood score in this embedding space is a valid approximation of the true likelihood score, making it possible to steer the denoising process towards the posterior. Across extensive experiments, our model CoGuide produces more consistent floorplans from trajectories, and is more robust than differentiable-planner baselines and guided-diffusion methods.
ArrayDPS: Unsupervised Blind Speech Separation with a Diffusion Prior
May 17, 2025



Blind Speech Separation (BSS) aims to separate multiple speech sources from audio mixtures recorded by a microphone array. The problem is challenging because it is a blind inverse problem, i.e., the microphone array geometry, the room impulse response (RIR), and the speech sources, are all unknown. We propose ArrayDPS to solve the BSS problem in an unsupervised, array-agnostic, and generative manner. The core idea builds on diffusion posterior sampling (DPS), but unlike DPS where the likelihood is tractable, ArrayDPS must approximate the likelihood by formulating a separate optimization problem. The solution to the optimization approximates room acoustics and the relative transfer functions between microphones. These approximations, along with the diffusion priors, iterate through the ArrayDPS sampling process and ultimately yield separated voice sources. We only need a simple single-speaker speech diffusion model as a prior along with the mixtures recorded at the microphones; no microphone array information is necessary. Evaluation results show that ArrayDPS outperforms all baseline unsupervised methods while being comparable to supervised methods in terms of SDR. Audio demos are provided at: https://arraydps.github.io/ArrayDPSDemo/.
Unsupervised Blind Speech Separation with a Diffusion Prior
May 08, 2025Blind Speech Separation (BSS) aims to separate multiple speech sources from audio mixtures recorded by a microphone array. The problem is challenging because it is a blind inverse problem, i.e., the microphone array geometry, the room impulse response (RIR), and the speech sources, are all unknown. We propose ArrayDPS to solve the BSS problem in an unsupervised, array-agnostic, and generative manner. The core idea builds on diffusion posterior sampling (DPS), but unlike DPS where the likelihood is tractable, ArrayDPS must approximate the likelihood by formulating a separate optimization problem. The solution to the optimization approximates room acoustics and the relative transfer functions between microphones. These approximations, along with the diffusion priors, iterate through the ArrayDPS sampling process and ultimately yield separated voice sources. We only need a simple single-speaker speech diffusion model as a prior along with the mixtures recorded at the microphones; no microphone array information is necessary. Evaluation results show that ArrayDPS outperforms all baseline unsupervised methods while being comparable to supervised methods in terms of SDR. Audio demos are provided at: https://arraydps.github.io/ArrayDPSDemo/.
Multi-Source Music Generation with Latent Diffusion
Sep 10, 2024
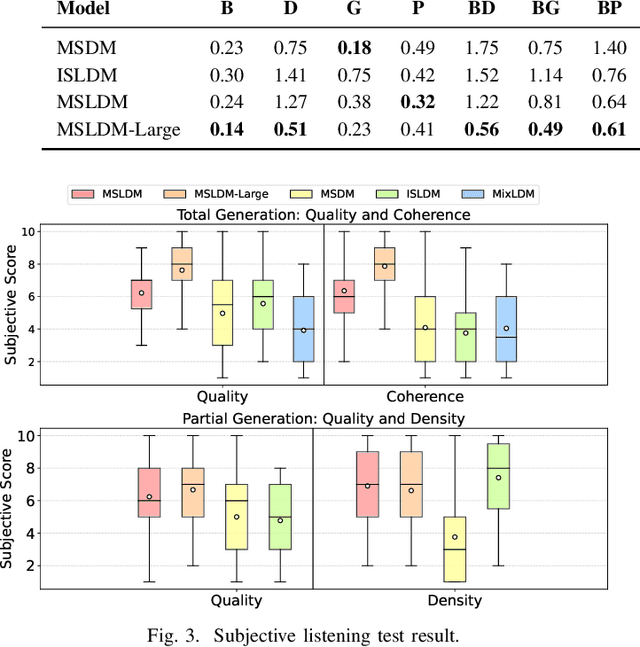


Most music generation models directly generate a single music mixture. To allow for more flexible and controllable generation, the Multi-Source Diffusion Model (MSDM) has been proposed to model music as a mixture of multiple instrumental sources (e.g., piano, drums, bass, and guitar). Its goal is to use one single diffusion model to generate consistent music sources, which are further mixed to form the music. Despite its capabilities, MSDM is unable to generate songs with rich melodies and often generates empty sounds. Also, its waveform diffusion introduces significant Gaussian noise artifacts, which compromises audio quality. In response, we introduce a multi-source latent diffusion model (MSLDM) that employs Variational Autoencoders (VAEs) to encode each instrumental source into a distinct latent representation. By training a VAE on all music sources, we efficiently capture each source's unique characteristics in a source latent that our diffusion model models jointly. This approach significantly enhances the total and partial generation of music by leveraging the VAE's latent compression and noise-robustness. The compressed source latent also facilitates more efficient generation. Subjective listening tests and Frechet Audio Distance (FAD) scores confirm that our model outperforms MSDM, showcasing its practical and enhanced applicability in music generation systems. We also emphasize that modeling sources is more effective than direct music mixture modeling. Codes and models are available at https://github.com/XZWY/MSLDM. Demos are available at https://xzwy.github.io/MSLDMDemo.
FoVNet: Configurable Field-of-View Speech Enhancement with Low Computation and Distortion for Smart Glasses
Aug 12, 2024


This paper presents a novel multi-channel speech enhancement approach, FoVNet, that enables highly efficient speech enhancement within a configurable field of view (FoV) of a smart-glasses user without needing specific target-talker(s) directions. It advances over prior works by enhancing all speakers within any given FoV, with a hybrid signal processing and deep learning approach designed with high computational efficiency. The neural network component is designed with ultra-low computation (about 50 MMACS). A multi-channel Wiener filter and a post-processing module are further used to improve perceptual quality. We evaluate our algorithm with a microphone array on smart glasses, providing a configurable, efficient solution for augmented hearing on energy-constrained devices. FoVNet excels in both computational efficiency and speech quality across multiple scenarios, making it a promising solution for smart glasses applications.
uSee: Unified Speech Enhancement and Editing with Conditional Diffusion Models
Oct 02, 2023Speech enhancement aims to improve the quality of speech signals in terms of quality and intelligibility, and speech editing refers to the process of editing the speech according to specific user needs. In this paper, we propose a Unified Speech Enhancement and Editing (uSee) model with conditional diffusion models to handle various tasks at the same time in a generative manner. Specifically, by providing multiple types of conditions including self-supervised learning embeddings and proper text prompts to the score-based diffusion model, we can enable controllable generation of the unified speech enhancement and editing model to perform corresponding actions on the source speech. Our experiments show that our proposed uSee model can achieve superior performance in both speech denoising and dereverberation compared to other related generative speech enhancement models, and can perform speech editing given desired environmental sound text description, signal-to-noise ratios (SNR), and room impulse responses (RIR). Demos of the generated speech are available at https://muqiaoy.github.io/usee.
Unifying Robustness and Fidelity: A Comprehensive Study of Pretrained Generative Methods for Speech Enhancement in Adverse Conditions
Sep 16, 2023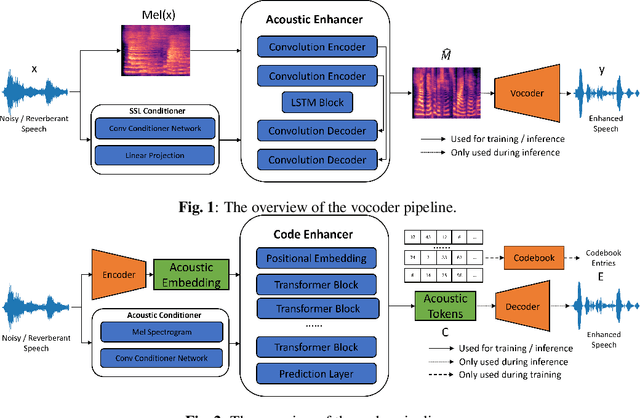

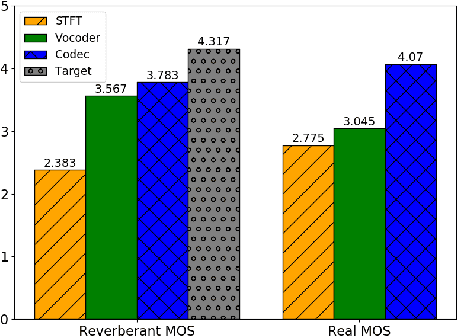
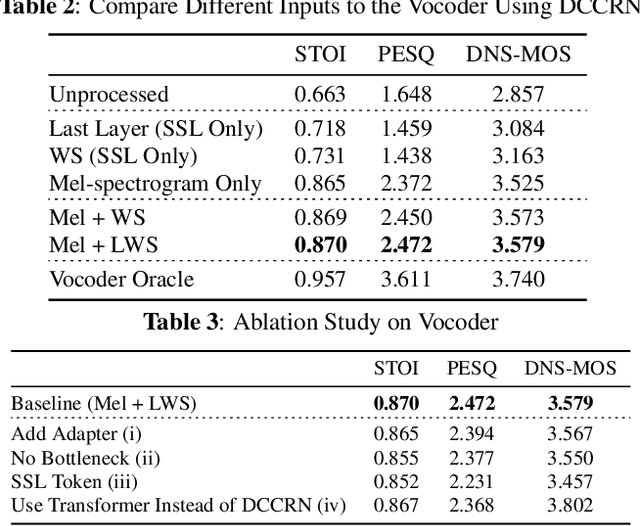
Enhancing speech signal quality in adverse acoustic environments is a persistent challenge in speech processing. Existing deep learning based enhancement methods often struggle to effectively remove background noise and reverberation in real-world scenarios, hampering listening experiences. To address these challenges, we propose a novel approach that uses pre-trained generative methods to resynthesize clean, anechoic speech from degraded inputs. This study leverages pre-trained vocoder or codec models to synthesize high-quality speech while enhancing robustness in challenging scenarios. Generative methods effectively handle information loss in speech signals, resulting in regenerated speech that has improved fidelity and reduced artifacts. By harnessing the capabilities of pre-trained models, we achieve faithful reproduction of the original speech in adverse conditions. Experimental evaluations on both simulated datasets and realistic samples demonstrate the effectiveness and robustness of our proposed methods. Especially by leveraging codec, we achieve superior subjective scores for both simulated and realistic recordings. The generated speech exhibits enhanced audio quality, reduced background noise, and reverberation. Our findings highlight the potential of pre-trained generative techniques in speech processing, particularly in scenarios where traditional methods falter. Demos are available at https://whmrtm.github.io/SoundResynthesis.