 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Separate Voices by Spatial Regions
Paper and Code
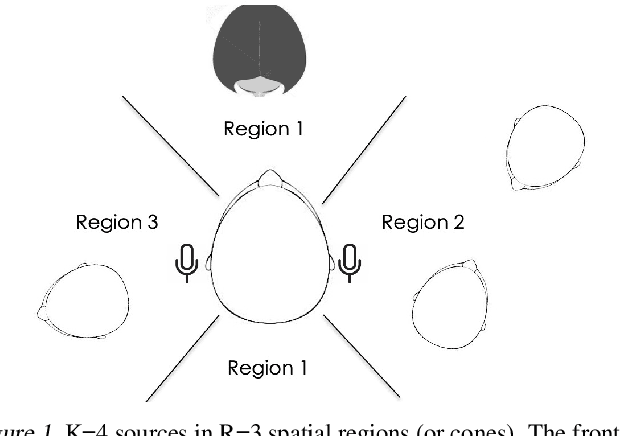


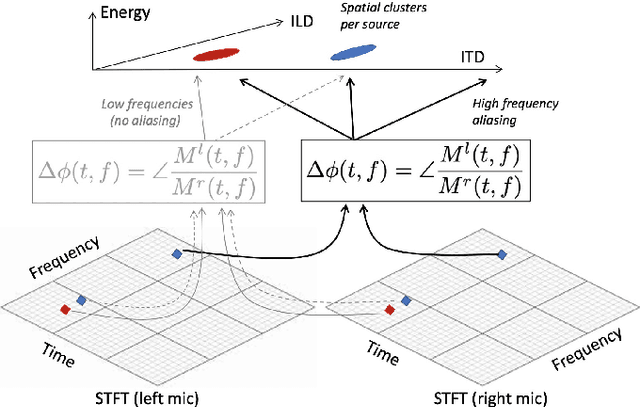
We consider the problem of audio voice separation for binaural applications, such as earphones and hearing aids. While today's neural networks perform remarkably well (separating $4+$ sources with 2 microphones) they assume a known or fixed maximum number of sources, K. Moreover, today's models are trained in a supervised manner, using training data synthesized from generic sources, environments, and human head shapes. This paper intends to relax both these constraints at the expense of a slight alteration in the problem definition. We observe that, when a received mixture contains too many sources, it is still helpful to separate them by region, i.e., isolating signal mixtures from each conical sector around the user's head. This requires learning the fine-grained spatial properties of each region, including the signal distortions imposed by a person's head. We propose a two-stage self-supervised framework in which overheard voices from earphones are pre-processed to extract relatively clean personalized signals, which are then used to train a region-wise separation model. Results show promising performance, underscoring the importance of personalization over a generic supervised approach. (audio samples available at our project website: https://uiuc-earable-computing.github.io/binaural/. We believe this result could help real-world applications in selective hearing, noise cancellation, and audio augmented reality.