 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Diffusion Refinement for Multi-Channel Speech Enhancement and Separation
Mar 25, 2026We propose Uni-ArrayDPS, a novel diffusion-based refinement framework for unified multi-channel speech enhancement and separation. Existing methods for multi-channel speech enhancement/separation are mostly discriminative and are highly effective at producing high-SNR outputs. However, they can still generate unnatural speech with non-linear distortions caused by the neural network and regression-based objectives. To address this issue, we propose Uni-ArrayDPS, which refines the outputs of any strong discriminative model using a speech diffusion prior. Uni-ArrayDPS is generative, array-agnostic, and training-free, and supports both enhancement and separation. Given a discriminative model's enhanced/separated speech, we use it, together with the noisy mixtures, to estimate the noise spatial covariance matrix (SCM). We then use this SCM to compute the likelihood required for diffusion posterior sampling of the clean speech source(s). Uni-ArrayDPS requires only a pre-trained clean-speech diffusion model as a prior and does not require additional training or fine-tuning, allowing it to generalize directly across tasks (enhancement/separation), microphone array geometries, and discriminative model backbones. Extensive experiments show that Uni-ArrayDPS consistently improves a wide range of discriminative models for both enhancement and separation tasks. We also report strong results on a real-world dataset. Audio demos are provided at \href{https://xzwy.github.io/Uni-ArrayDPS/}{https://xzwy.github.io/Uni-ArrayDPS/}.
Personalized Image Generation via Human-in-the-loop Bayesian Optimization
Feb 02, 2026Imagine Alice has a specific image $x^\ast$ in her mind, say, the view of the street in which she grew up during her childhood. To generate that exact image, she guides a generative model with multiple rounds of prompting and arrives at an image $x^{p*}$. Although $x^{p*}$ is reasonably close to $x^\ast$, Alice finds it difficult to close that gap using language prompts. This paper aims to narrow this gap by observing that even after language has reached its limits, humans can still tell when a new image $x^+$ is closer to $x^\ast$ than $x^{p*}$. Leveraging this observation, we develop MultiBO (Multi-Choice Preferential Bayesian Optimization) that carefully generates $K$ new images as a function of $x^{p*}$, gets preferential feedback from the user, uses the feedback to guide the diffusion model, and ultimately generates a new set of $K$ images. We show that within $B$ rounds of user feedback, it is possible to arrive much closer to $x^\ast$, even though the generative model has no information about $x^\ast$. Qualitative scores from $30$ users, combined with quantitative metrics compared across $5$ baselines, show promising results, suggesting that multi-choice feedback from humans can be effectively harnessed for personalized image generation.
AVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
Zero-shot Human Pose Estimation using Diffusion-based Inverse solvers
Oct 02, 2025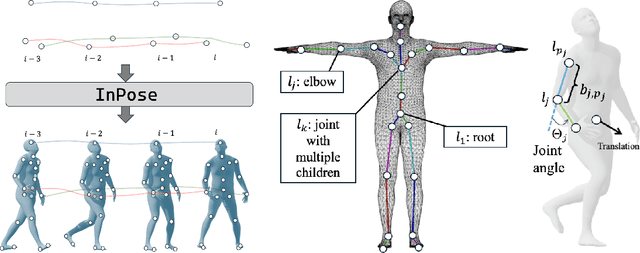
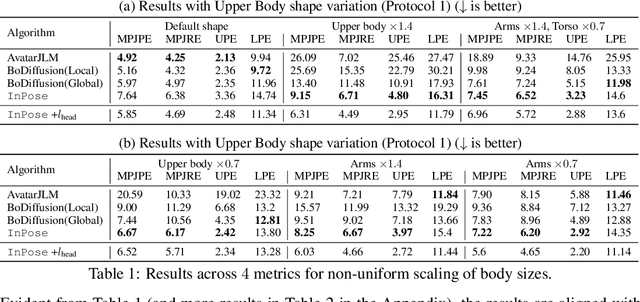
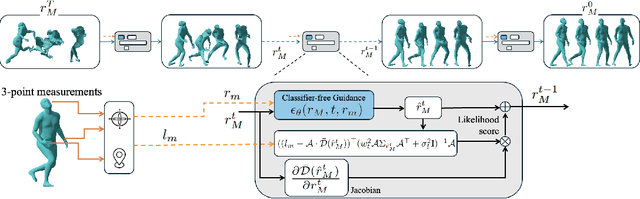
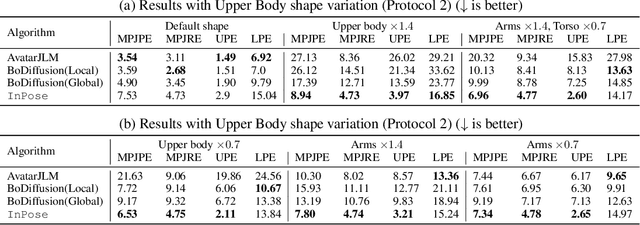
Pose estimation refers to tracking a human's full body posture, including their head, torso, arms, and legs. The problem is challenging in practical settings where the number of body sensors are limited. Past work has shown promising results using conditional diffusion models, where the pose prediction is conditioned on both <location, rotation> measurements from the sensors. Unfortunately, nearly all these approaches generalize poorly across users, primarly because location measurements are highly influenced by the body size of the user. In this paper, we formulate pose estimation as an inverse problem and design an algorithm capable of zero-shot generalization. Our idea utilizes a pre-trained diffusion model and conditions it on rotational measurements alone; the priors from this model are then guided by a likelihood term, derived from the measured locations. Thus, given any user, our proposed InPose method generatively estimates the highly likely sequence of poses that best explains the sparse on-body measurements.
Contrastive Diffusion Guidance for Spatial Inverse Problems
Sep 30, 2025

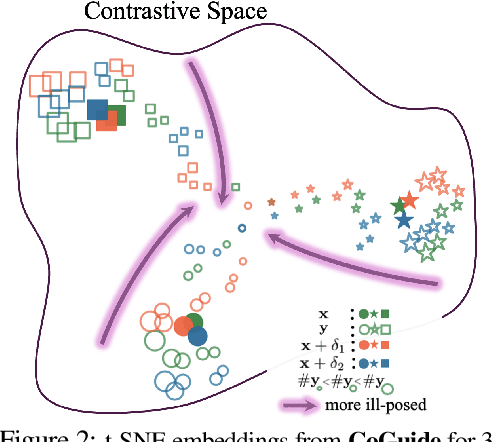

We consider the inverse problem of reconstructing the spatial layout of a place, a home floorplan for example, from a user`s movements inside that layout. Direct inversion is ill-posed since many floorplans can explain the same movement trajectories. We adopt a diffusion-based posterior sampler to generate layouts consistent with the measurements. While active research is in progress on generative inverse solvers, we find that the forward operator in our problem poses new challenges. The path-planning process inside a floorplan is a non-invertible, non-differentiable function, and causes instability while optimizing using the likelihood score. We break-away from existing approaches and reformulate the likelihood score in a smoother embedding space. The embedding space is trained with a contrastive loss which brings compatible floorplans and trajectories close to each other, while pushing mismatched pairs far apart. We show that a surrogate form of the likelihood score in this embedding space is a valid approximation of the true likelihood score, making it possible to steer the denoising process towards the posterior. Across extensive experiments, our model CoGuide produces more consistent floorplans from trajectories, and is more robust than differentiable-planner baselines and guided-diffusion methods.
Explicit Context-Driven Neural Acoustic Modeling for High-Fidelity RIR Generation
Sep 18, 2025Realistic sound simulation plays a critical role in many applications. A key element in sound simulation is the room impulse response (RIR), which characterizes how sound propagates from a source to a listener within a given space. Recent studies have applied neural implicit methods to learn RIR using context information collected from the environment, such as scene images. However, these approaches do not effectively leverage explicit geometric information from the environment. To further exploit the potential of neural implicit models with direct geometric features, we present Mesh-infused Neural Acoustic Field (MiNAF), which queries a rough room mesh at given locations and extracts distance distributions as an explicit representation of local context. Our approach demonstrates that incorporating explicit local geometric features can better guide the neural network in generating more accurate RIR predictions. Through comparisons with conventional and state-of-the-art baseline methods, we show that MiNAF performs competitively across various evaluation metrics. Furthermore, we verify the robustness of MiNAF in datasets with limited training samples, demonstrating an advance in high-fidelity sound simulation.
Kernel Learning for Sample Constrained Black-Box Optimization
Jul 28, 2025Black box optimization (BBO) focuses on optimizing unknown functions in high-dimensional spaces. In many applications, sampling the unknown function is expensive, imposing a tight sample budget. Ongoing work is making progress on reducing the sample budget by learning the shape/structure of the function, known as kernel learning. We propose a new method to learn the kernel of a Gaussian Process. Our idea is to create a continuous kernel space in the latent space of a variational autoencoder, and run an auxiliary optimization to identify the best kernel. Results show that the proposed method, Kernel Optimized Blackbox Optimization (KOBO), outperforms state of the art by estimating the optimal at considerably lower sample budgets. Results hold not only across synthetic benchmark functions but also in real applications. We show that a hearing aid may be personalized with fewer audio queries to the user, or a generative model could converge to desirable images from limited user ratings.
Can NeRFs See without Cameras?
May 28, 2025Neural Radiance Fields (NeRFs) have been remarkably successful at synthesizing novel views of 3D scenes by optimizing a volumetric scene function. This scene function models how optical rays bring color information from a 3D object to the camera pixels. Radio frequency (RF) or audio signals can also be viewed as a vehicle for delivering information about the environment to a sensor. However, unlike camera pixels, an RF/audio sensor receives a mixture of signals that contain many environmental reflections (also called "multipath"). Is it still possible to infer the environment using such multipath signals? We show that with redesign, NeRFs can be taught to learn from multipath signals, and thereby "see" the environment. As a grounding application, we aim to infer the indoor floorplan of a home from sparse WiFi measurements made at multiple locations inside the home. Although a difficult inverse problem, our implicitly learnt floorplans look promising, and enables forward applications, such as indoor signal prediction and basic ray tracing.
ArrayDPS: Unsupervised Blind Speech Separation with a Diffusion Prior
May 17, 2025



Blind Speech Separation (BSS) aims to separate multiple speech sources from audio mixtures recorded by a microphone array. The problem is challenging because it is a blind inverse problem, i.e., the microphone array geometry, the room impulse response (RIR), and the speech sources, are all unknown. We propose ArrayDPS to solve the BSS problem in an unsupervised, array-agnostic, and generative manner. The core idea builds on diffusion posterior sampling (DPS), but unlike DPS where the likelihood is tractable, ArrayDPS must approximate the likelihood by formulating a separate optimization problem. The solution to the optimization approximates room acoustics and the relative transfer functions between microphones. These approximations, along with the diffusion priors, iterate through the ArrayDPS sampling process and ultimately yield separated voice sources. We only need a simple single-speaker speech diffusion model as a prior along with the mixtures recorded at the microphones; no microphone array information is necessary. Evaluation results show that ArrayDPS outperforms all baseline unsupervised methods while being comparable to supervised methods in terms of SDR. Audio demos are provided at: https://arraydps.github.io/ArrayDPSDemo/.
Unsupervised Blind Speech Separation with a Diffusion Prior
May 08, 2025Blind Speech Separation (BSS) aims to separate multiple speech sources from audio mixtures recorded by a microphone array. The problem is challenging because it is a blind inverse problem, i.e., the microphone array geometry, the room impulse response (RIR), and the speech sources, are all unknown. We propose ArrayDPS to solve the BSS problem in an unsupervised, array-agnostic, and generative manner. The core idea builds on diffusion posterior sampling (DPS), but unlike DPS where the likelihood is tractable, ArrayDPS must approximate the likelihood by formulating a separate optimization problem. The solution to the optimization approximates room acoustics and the relative transfer functions between microphones. These approximations, along with the diffusion priors, iterate through the ArrayDPS sampling process and ultimately yield separated voice sources. We only need a simple single-speaker speech diffusion model as a prior along with the mixtures recorded at the microphones; no microphone array information is necessary. Evaluation results show that ArrayDPS outperforms all baseline unsupervised methods while being comparable to supervised methods in terms of SDR. Audio demos are provided at: https://arraydps.github.io/ArrayDPSDemo/.