 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Deep Learning Framework for Efficient Multichannel Acoustic Feedback Control
May 21, 2025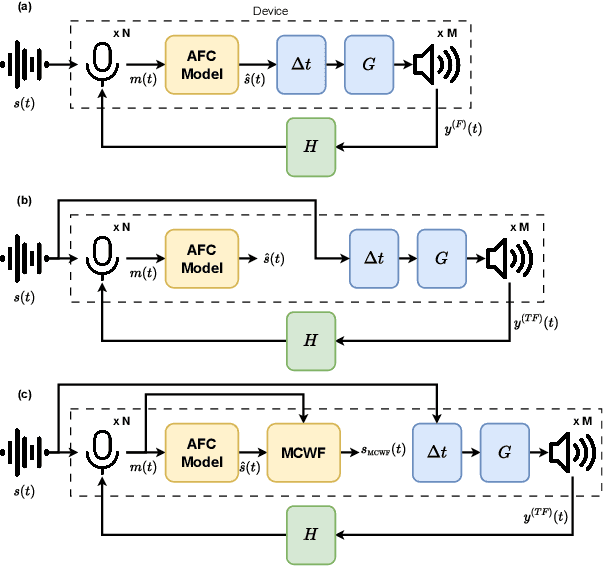
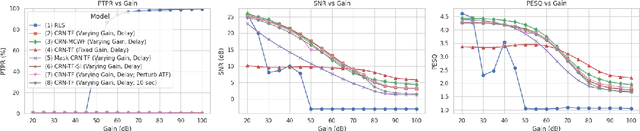
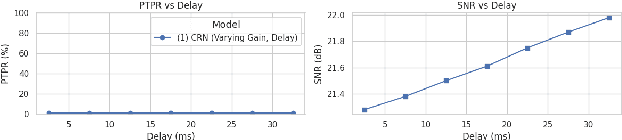
This study presents a deep-learning framework for controlling multichannel acoustic feedback in audio devices. Traditional digital signal processing methods struggle with convergence when dealing with highly correlated noise such as feedback. We introduce a Convolutional Recurrent Network that efficiently combines spatial and temporal processing, significantly enhancing speech enhancement capabilities with lower computational demands. Our approach utilizes three training methods: In-a-Loop Training, Teacher Forcing, and a Hybrid strategy with a Multichannel Wiener Filter, optimizing performance in complex acoustic environments. This scalable framework offers a robust solution for real-world applications, making significant advances in Acoustic Feedback Control technology.
Explainable DNN-based Beamformer with Postfilter
Nov 16, 2024This paper introduces an explainable DNN-based beamformer with a postfilter (ExNet-BF+PF) for multichannel signal processing. Our approach combines the U-Net network with a beamformer structure to address this problem. The method involves a two-stage processing pipeline. In the first stage, time-invariant weights are applied to construct a multichannel spatial filter, namely a beamformer. In the second stage, a time-varying single-channel post-filter is applied at the beamformer output. Additionally, we incorporate an attention mechanism inspired by its successful application in noisy and reverberant environments to improve speech enhancement further. Furthermore, our study fills a gap in the existing literature by conducting a thorough spatial analysis of the network's performance. Specifically, we examine how the network utilizes spatial information during processing. This analysis yields valuable insights into the network's functionality, thereby enhancing our understanding of its overall performance. Experimental results demonstrate that our approach is not only straightforward to train but also yields superior results, obviating the necessity for prior knowledge of the speaker's activity.
FoVNet: Configurable Field-of-View Speech Enhancement with Low Computation and Distortion for Smart Glasses
Aug 12, 2024


This paper presents a novel multi-channel speech enhancement approach, FoVNet, that enables highly efficient speech enhancement within a configurable field of view (FoV) of a smart-glasses user without needing specific target-talker(s) directions. It advances over prior works by enhancing all speakers within any given FoV, with a hybrid signal processing and deep learning approach designed with high computational efficiency. The neural network component is designed with ultra-low computation (about 50 MMACS). A multi-channel Wiener filter and a post-processing module are further used to improve perceptual quality. We evaluate our algorithm with a microphone array on smart glasses, providing a configurable, efficient solution for augmented hearing on energy-constrained devices. FoVNet excels in both computational efficiency and speech quality across multiple scenarios, making it a promising solution for smart glasses applications.
EasyCom: An Augmented Reality Dataset to Support Algorithms for Easy Communication in Noisy Environments
Jul 09, 2021

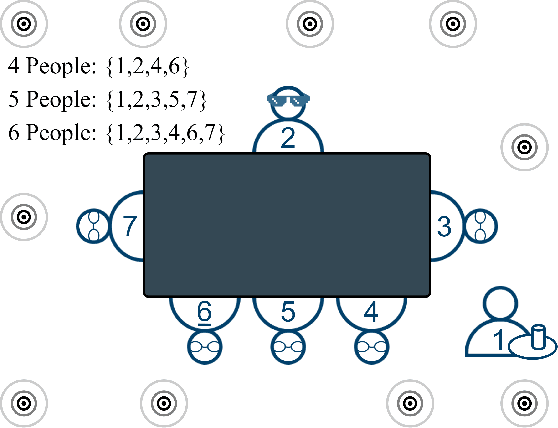
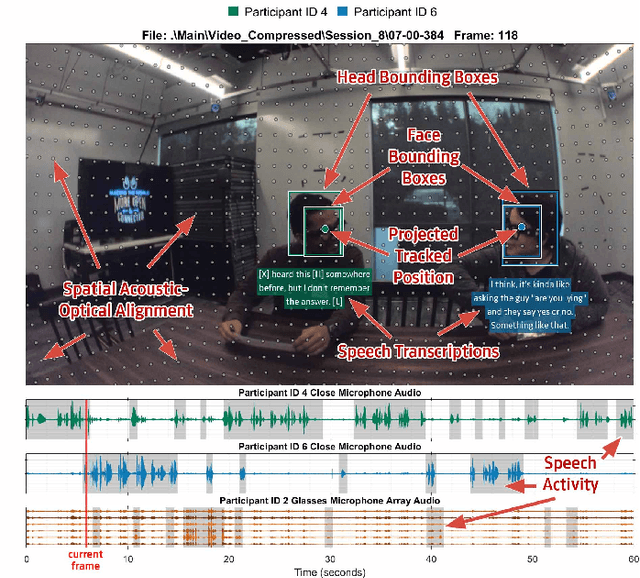
Augmented Reality (AR) as a platform has the potential to facilitate the reduction of the cocktail party effect. Future AR headsets could potentially leverage information from an array of sensors spanning many different modalities. Training and testing signal processing and machine learning algorithms on tasks such as beam-forming and speech enhancement require high quality representative data. To the best of the author's knowledge, as of publication there are no available datasets that contain synchronized egocentric multi-channel audio and video with dynamic movement and conversations in a noisy environment. In this work, we describe, evaluate and release a dataset that contains over 5 hours of multi-modal data useful for training and testing algorithms for the application of improving conversations for an AR glasses wearer. We provide speech intelligibility, quality and signal-to-noise ratio improvement results for a baseline method and show improvements across all tested metrics. The dataset we are releasing contains AR glasses egocentric multi-channel microphone array audio, wide field-of-view RGB video, speech source pose, headset microphone audio, annotated voice activity, speech transcriptions, head bounding boxes, target of speech and source identification labels. We have created and are releasing this dataset to facilitate research in multi-modal AR solutions to the cocktail party problem.