 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Flow Matching for Visually-Guided Acoustic Highlighting
Feb 03, 2026Visually-guided acoustic highlighting seeks to rebalance audio in alignment with the accompanying video, creating a coherent audio-visual experience. While visual saliency and enhancement have been widely studied, acoustic highlighting remains underexplored, often leading to misalignment between visual and auditory focus. Existing approaches use discriminative models, which struggle with the inherent ambiguity in audio remixing, where no natural one-to-one mapping exists between poorly-balanced and well-balanced audio mixes. To address this limitation, we reframe this task as a generative problem and introduce a Conditional Flow Matching (CFM) framework. A key challenge in iterative flow-based generation is that early prediction errors -- in selecting the correct source to enhance -- compound over steps and push trajectories off-manifold. To address this, we introduce a rollout loss that penalizes drift at the final step, encouraging self-correcting trajectories and stabilizing long-range flow integration. We further propose a conditioning module that fuses audio and visual cues before vector field regression, enabling explicit cross-modal source selection. Extensive quantitative and qualitative evaluations show that our method consistently surpasses the previous state-of-the-art discriminative approach, establishing that visually-guided audio remixing is best addressed through generative modeling.
DuetServe: Harmonizing Prefill and Decode for LLM Serving via Adaptive GPU Multiplexing
Nov 06, 2025Modern LLM serving systems must sustain high throughput while meeting strict latency SLOs across two distinct inference phases: compute-intensive prefill and memory-bound decode phases. Existing approaches either (1) aggregate both phases on shared GPUs, leading to interference between prefill and decode phases, which degrades time-between-tokens (TBT); or (2) disaggregate the two phases across GPUs, improving latency but wasting resources through duplicated models and KV cache transfers. We present DuetServe, a unified LLM serving framework that achieves disaggregation-level isolation within a single GPU. DuetServe operates in aggregated mode by default and dynamically activates SM-level GPU spatial multiplexing when TBT degradation is predicted. Its key idea is to decouple prefill and decode execution only when needed through fine-grained, adaptive SM partitioning that provides phase isolation only when contention threatens latency service level objectives (SLOs). DuetServe integrates (1) an attention-aware roofline model to forecast iteration latency, (2) a partitioning optimizer that selects the optimal SM split to maximize throughput under TBT constraints, and (3) an interruption-free execution engine that eliminates CPU-GPU synchronization overhead. Evaluations show that DuetServe improves total throughput by up to 1.3x while maintaining low generation latency compared to state-of-the-art frameworks.
Explainable DNN-based Beamformer with Postfilter
Nov 16, 2024This paper introduces an explainable DNN-based beamformer with a postfilter (ExNet-BF+PF) for multichannel signal processing. Our approach combines the U-Net network with a beamformer structure to address this problem. The method involves a two-stage processing pipeline. In the first stage, time-invariant weights are applied to construct a multichannel spatial filter, namely a beamformer. In the second stage, a time-varying single-channel post-filter is applied at the beamformer output. Additionally, we incorporate an attention mechanism inspired by its successful application in noisy and reverberant environments to improve speech enhancement further. Furthermore, our study fills a gap in the existing literature by conducting a thorough spatial analysis of the network's performance. Specifically, we examine how the network utilizes spatial information during processing. This analysis yields valuable insights into the network's functionality, thereby enhancing our understanding of its overall performance. Experimental results demonstrate that our approach is not only straightforward to train but also yields superior results, obviating the necessity for prior knowledge of the speaker's activity.
All Neural Low-latency Directional Speech Extraction
Jul 05, 2024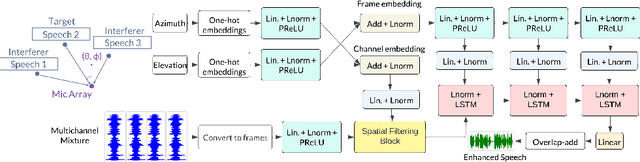
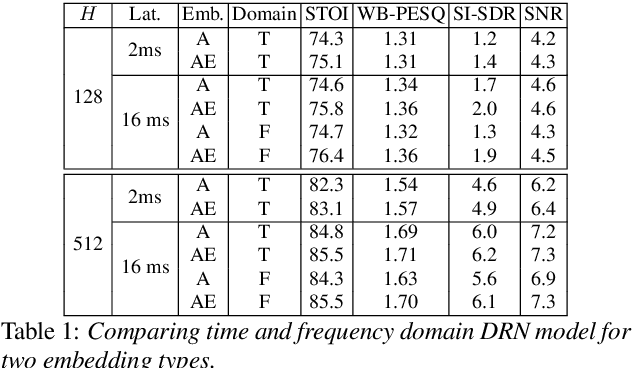
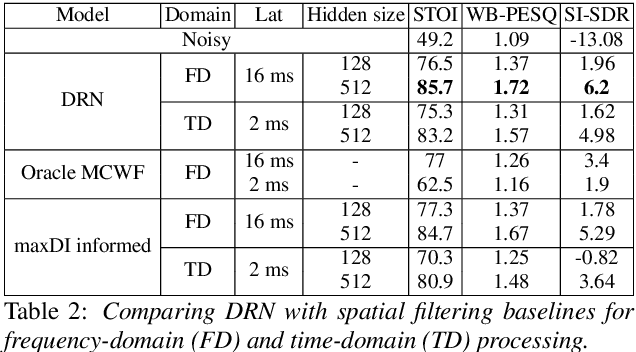
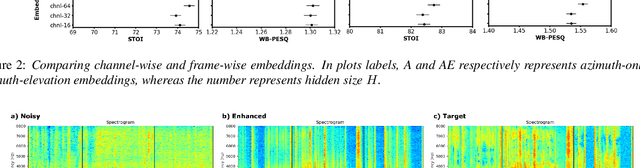
We introduce a novel all neural model for low-latency directional speech extraction. The model uses direction of arrival (DOA) embeddings from a predefined spatial grid, which are transformed and fused into a recurrent neural network based speech extraction model. This process enables the model to effectively extract speech from a specified DOA. Unlike previous methods that relied on hand-crafted directional features, the proposed model trains DOA embeddings from scratch using speech enhancement loss, making it suitable for low-latency scenarios. Additionally, it operates at a high frame rate, taking in DOA with each input frame, which brings in the capability of quickly adapting to changing scene in highly dynamic real-world scenarios. We provide extensive evaluation to demonstrate the model's efficacy in directional speech extraction, robustness to DOA mismatch, and its capability to quickly adapt to abrupt changes in DOA.
On the Importance of Neural Wiener Filter for Resource Efficient Multichannel Speech Enhancement
Jan 15, 2024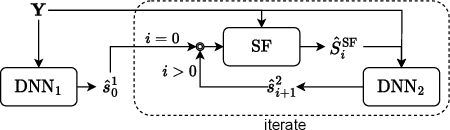
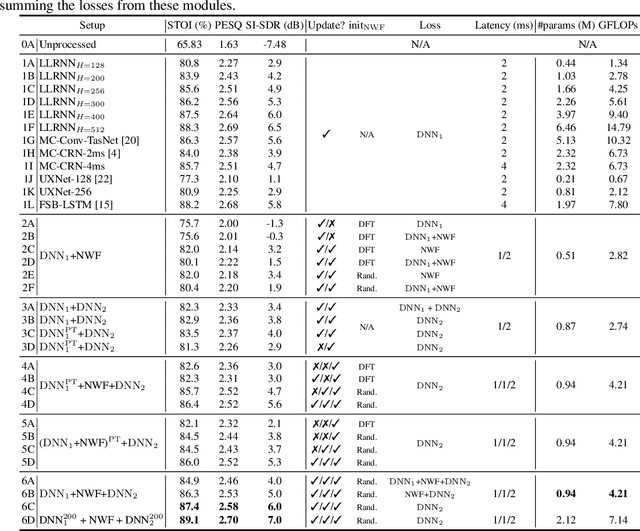
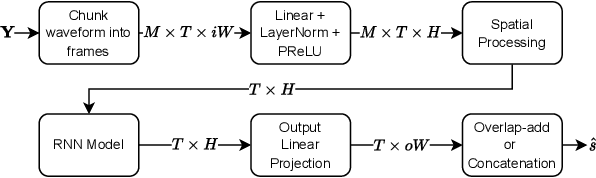
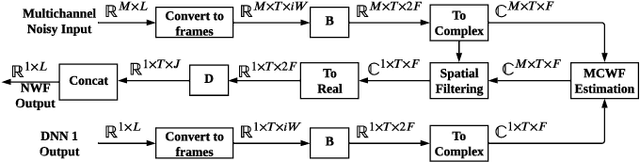
We introduce a time-domain framework for efficient multichannel speech enhancement, emphasizing low latency and computational efficiency. This framework incorporates two compact deep neural networks (DNNs) surrounding a multichannel neural Wiener filter (NWF). The first DNN enhances the speech signal to estimate NWF coefficients, while the second DNN refines the output from the NWF. The NWF, while conceptually similar to the traditional frequency-domain Wiener filter, undergoes a training process optimized for low-latency speech enhancement, involving fine-tuning of both analysis and synthesis transforms. Our research results illustrate that the NWF output, having minimal nonlinear distortions, attains performance levels akin to those of the first DNN, deviating from conventional Wiener filter paradigms. Training all components jointly outperforms sequential training, despite its simplicity. Consequently, this framework achieves superior performance with fewer parameters and reduced computational demands, making it a compelling solution for resource-efficient multichannel speech enhancement.
Rethinking complex-valued deep neural networks for monaural speech enhancement
Jan 11, 2023



Despite multiple efforts made towards adopting complex-valued deep neural networks (DNNs), it remains an open question whether complex-valued DNNs are generally more effective than real-valued DNNs for monaural speech enhancement. This work is devoted to presenting a critical assessment by systematically examining complex-valued DNNs against their real-valued counterparts. Specifically, we investigate complex-valued DNN atomic units, including linear layers, convolutional layers, long short-term memory (LSTM), and gated linear units. By comparing complex- and real-valued versions of fundamental building blocks in the recently developed gated convolutional recurrent network (GCRN), we show how different mechanisms for basic blocks affect the performance. We also find that the use of complex-valued operations hinders the model capacity when the model size is small. In addition, we examine two recent complex-valued DNNs, i.e. deep complex convolutional recurrent network (DCCRN) and deep complex U-Net (DCUNET). Evaluation results show that both DNNs produce identical performance to their real-valued counterparts while requiring much more computation. Based on these comprehensive comparisons, we conclude that complex-valued DNNs do not provide a performance gain over their real-valued counterparts for monaural speech enhancement, and thus are less desirable due to their higher computational costs.
NICE-Beam: Neural Integrated Covariance Estimators for Time-Varying Beamformers
Dec 08, 2021
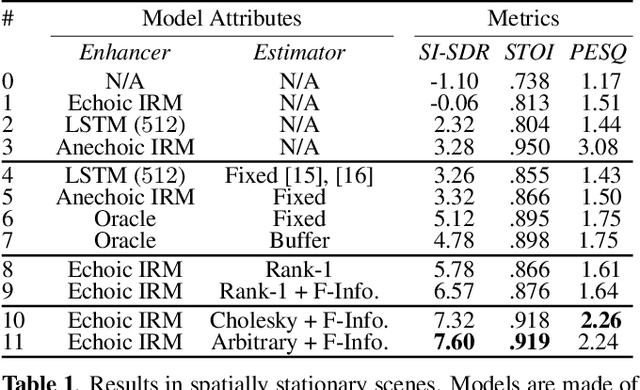
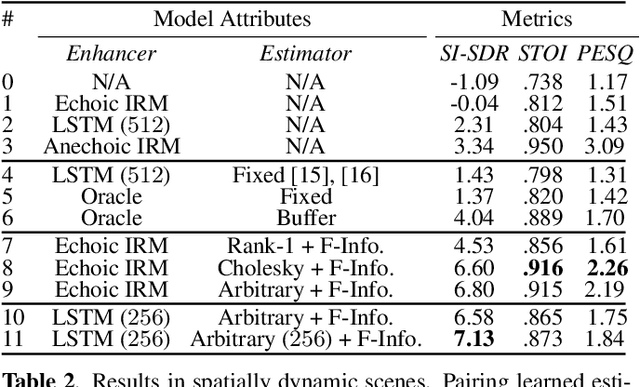
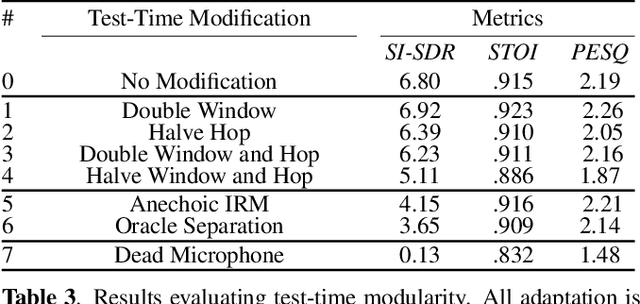
Estimating a time-varying spatial covariance matrix for a beamforming algorithm is a challenging task, especially for wearable devices, as the algorithm must compensate for time-varying signal statistics due to rapid pose-changes. In this paper, we propose Neural Integrated Covariance Estimators for Beamformers, NICE-Beam. NICE-Beam is a general technique for learning how to estimate time-varying spatial covariance matrices, which we apply to joint speech enhancement and dereverberation. It is based on training a neural network module to non-linearly track and leverage scene information across time. We integrate our solution into a beamforming pipeline, which enables simple training, faster than real-time inference, and a variety of test-time adaptation options. We evaluate the proposed model against a suite of baselines in scenes with both stationary and moving microphones. Our results show that the proposed method can outperform a hand-tuned estimator, despite the hand-tuned estimator using oracle source separation knowledge.
Information Decoding and SDR Implementation of DFRC Systems Without Training Signals
Feb 21, 2021
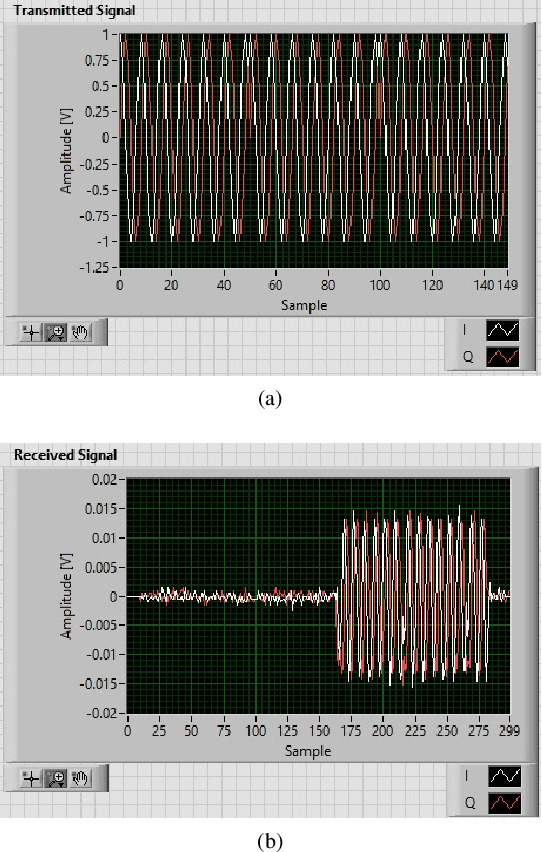
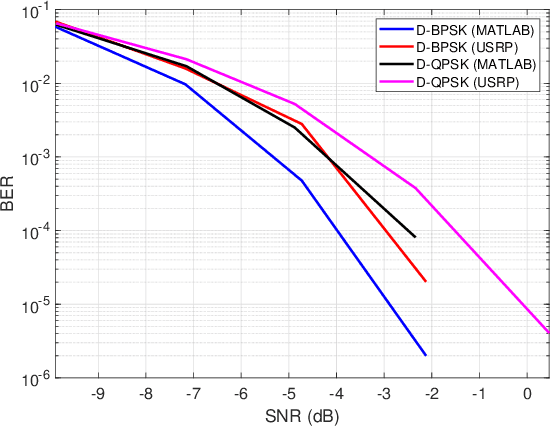
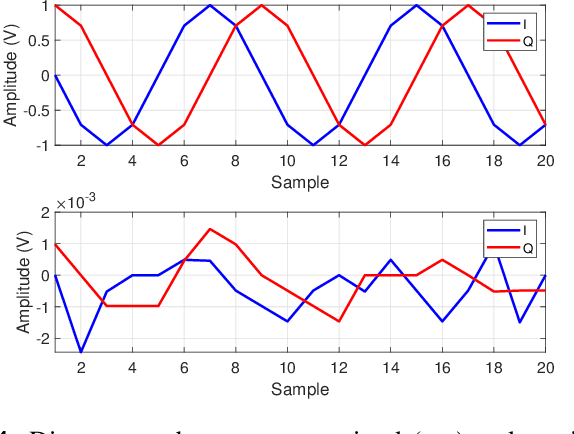
Recent performance analysis of dual-function radar communications (DFRC) systems, which embed information using phase shift keying (PSK) into multiple-input multiple-output (MIMO) frequency hopping (FH) radar pulses, shows promising results for addressing spectrum sharing issues between radar and communications. However, the problem of decoding information at the communication receiver remains challenging, since the DFRC transmitter is typically assumed to transmit only information embedded radar waveforms and not the training sequence. We propose a novel method for decoding information at the communication receiver without using training data, which is implemented using a software-defined radio (SDR). The performance of the SDR implementation is examined in terms of bit error rate (BER) as a function of signal-to-noise ratio (SNR) for differential binary and quadrature phase shift keying modulation schemes and compared with the BER versus SNR obtained with numerical simulations.
Transferable Graph Optimizers for ML Compilers
Oct 21, 2020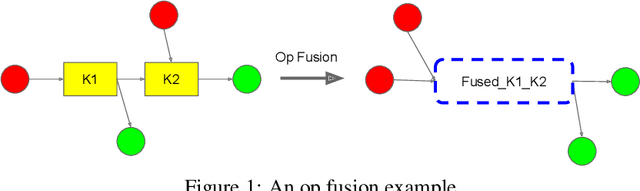

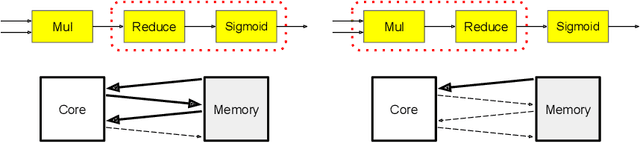
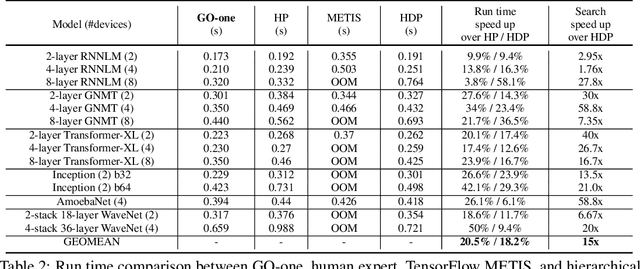
Most compilers for machine learning (ML) frameworks need to solve many correlated optimization problems to generate efficient machine code. Current ML compilers rely on heuristics based algorithms to solve these optimization problems one at a time. However, this approach is not only hard to maintain but often leads to sub-optimal solutions especially for newer model architectures. Existing learning based approaches in the literature are sample inefficient, tackle a single optimization problem, and do not generalize to unseen graphs making them infeasible to be deployed in practice. To address these limitations, we propose an end-to-end, transferable deep reinforcement learning method for computational graph optimization (GO), based on a scalable sequential attention mechanism over an inductive graph neural network. GO generates decisions on the entire graph rather than on each individual node autoregressively, drastically speeding up the search compared to prior methods. Moreover, we propose recurrent attention layers to jointly optimize dependent graph optimization tasks and demonstrate 33%-60% speedup on three graph optimization tasks compared to TensorFlow default optimization. On a diverse set of representative graphs consisting of up to 80,000 nodes, including Inception-v3, Transformer-XL, and WaveNet, GO achieves on average 21% improvement over human experts and 18% improvement over the prior state of the art with 15x faster convergence, on a device placement task evaluated in real systems.
* arXiv admin note: text overlap with arXiv:1910.01578
GDP: Generalized Device Placement for Dataflow Graphs
Sep 28, 2019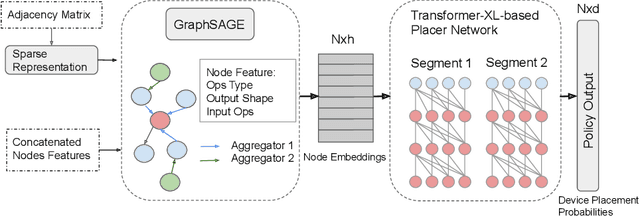
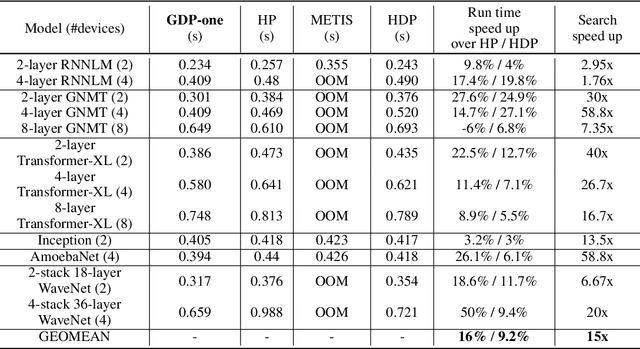
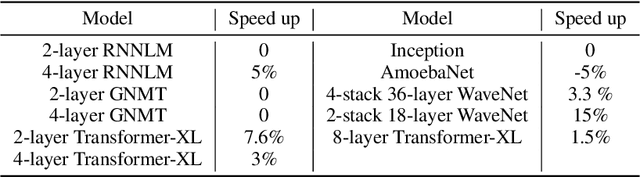
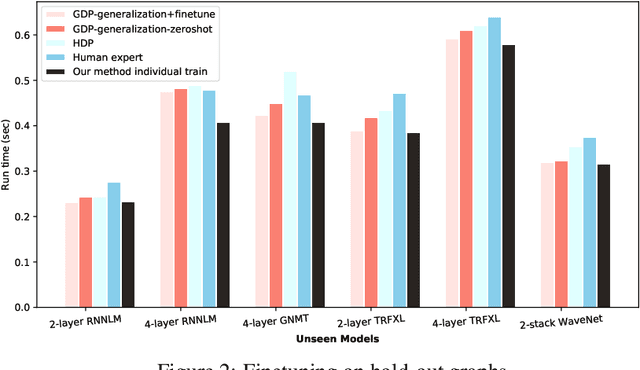
Runtime and scalability of large neural networks can be significantly affected by the placement of operations in their dataflow graphs on suitable devices. With increasingly complex neural network architectures and heterogeneous device characteristics, finding a reasonable placement is extremely challenging even for domain experts. Most existing automated device placement approaches are impractical due to the significant amount of compute required and their inability to generalize to new, previously held-out graphs. To address both limitations, we propose an efficient end-to-end method based on a scalable sequential attention mechanism over a graph neural network that is transferable to new graphs. On a diverse set of representative deep learning models, including Inception-v3, AmoebaNet, Transformer-XL, and WaveNet, our method on average achieves 16% improvement over human experts and 9.2% improvement over the prior art with 15 times faster convergence. To further reduce the computation cost, we pre-train the policy network on a set of dataflow graphs and use a superposition network to fine-tune it on each individual graph, achieving state-of-the-art performance on large hold-out graphs with over 50k nodes, such as an 8-layer GNMT.