 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Neural Low-latency Directional Speech Extraction
Paper and Code
Jul 05, 2024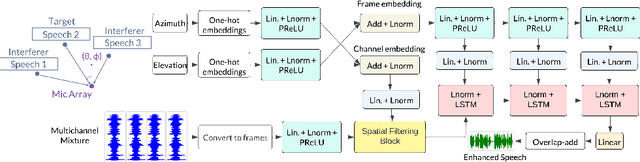
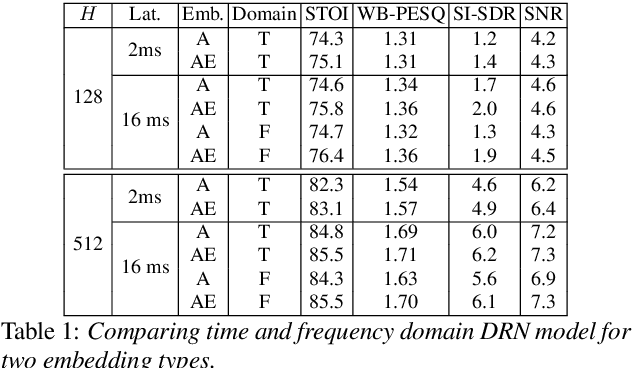
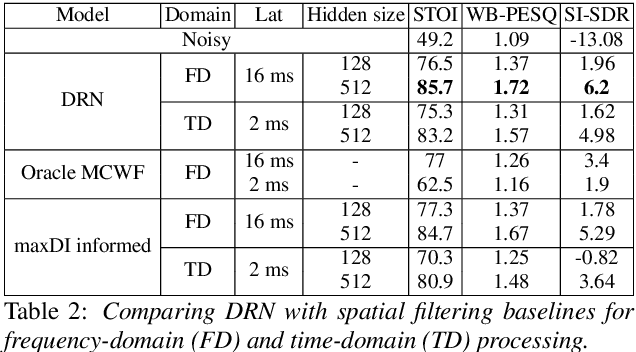
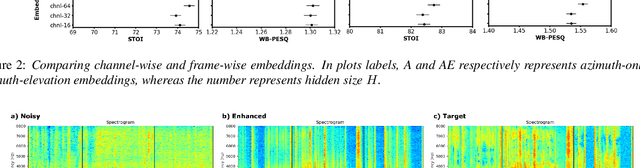
We introduce a novel all neural model for low-latency directional speech extraction. The model uses direction of arrival (DOA) embeddings from a predefined spatial grid, which are transformed and fused into a recurrent neural network based speech extraction model. This process enables the model to effectively extract speech from a specified DOA. Unlike previous methods that relied on hand-crafted directional features, the proposed model trains DOA embeddings from scratch using speech enhancement loss, making it suitable for low-latency scenarios. Additionally, it operates at a high frame rate, taking in DOA with each input frame, which brings in the capability of quickly adapting to changing scene in highly dynamic real-world scenarios. We provide extensive evaluation to demonstrate the model's efficacy in directional speech extraction, robustness to DOA mismatch, and its capability to quickly adapt to abrupt changes in DOA.