 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Resource-Efficient Speech Enhancement via Neural Differentiable DSP Vocoder Refinement
Aug 20, 2025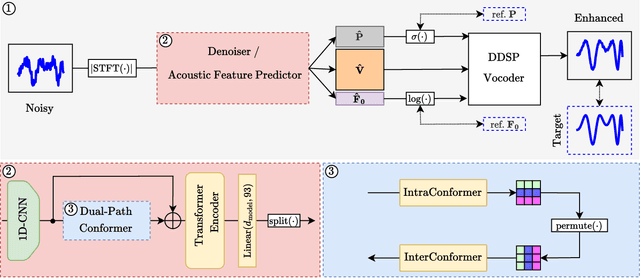
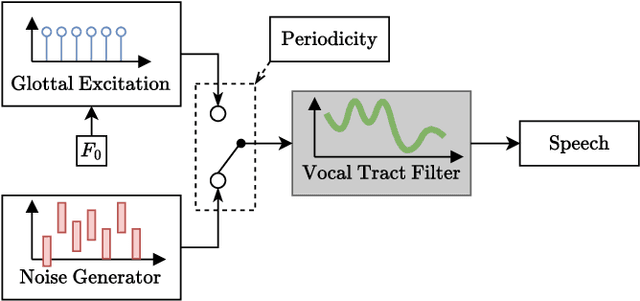
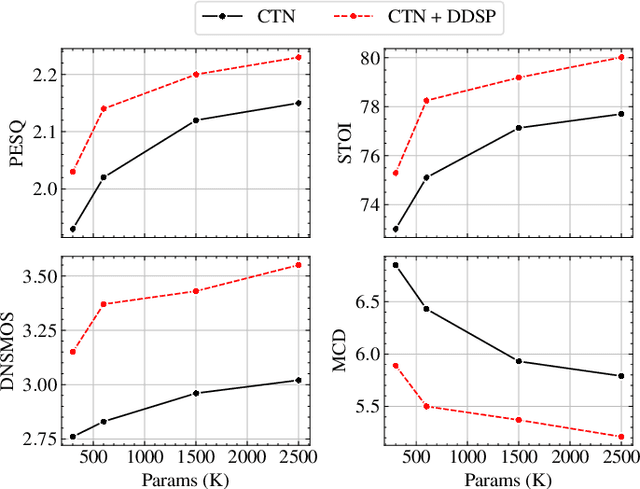
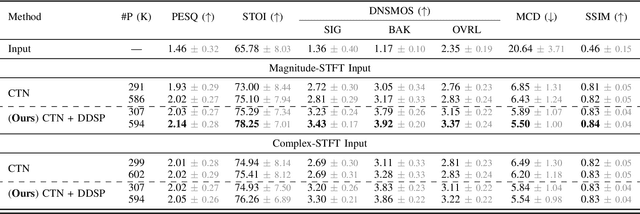
Deploying speech enhancement (SE) systems in wearable devices, such as smart glasses, is challenging due to the limited computational resources on the device. Although deep learning methods have achieved high-quality results, their computational cost limits their feasibility on embedded platforms. This work presents an efficient end-to-end SE framework that leverages a Differentiable Digital Signal Processing (DDSP) vocoder for high-quality speech synthesis. First, a compact neural network predicts enhanced acoustic features from noisy speech: spectral envelope, fundamental frequency (F0), and periodicity. These features are fed into the DDSP vocoder to synthesize the enhanced waveform. The system is trained end-to-end with STFT and adversarial losses, enabling direct optimization at the feature and waveform levels. Experimental results show that our method improves intelligibility and quality by 4% (STOI) and 19% (DNSMOS) over strong baselines without significantly increasing computation, making it well-suited for real-time applications.
Efficient Neural and Numerical Methods for High-Quality Online Speech Spectrogram Inversion via Gradient Theorem
May 30, 2025Recent work in online speech spectrogram inversion effectively combines Deep Learning with the Gradient Theorem to predict phase derivatives directly from magnitudes. Then, phases are estimated from their derivatives via least squares, resulting in a high quality reconstruction. In this work, we introduce three innovations that drastically reduce computational cost, while maintaining high quality: Firstly, we introduce a novel neural network architecture with just 8k parameters, 30 times smaller than previous state of the art. Secondly, increasing latency by 1 hop size allows us to further halve the cost of the neural inference step. Thirdly, we we observe that the least squares problem features a tridiagonal matrix and propose a linear-complexity solver for the least squares step that leverages tridiagonality and positive-semidefiniteness, achieving a speedup of several orders of magnitude. We release samples online.
A Novel Deep Learning Framework for Efficient Multichannel Acoustic Feedback Control
May 21, 2025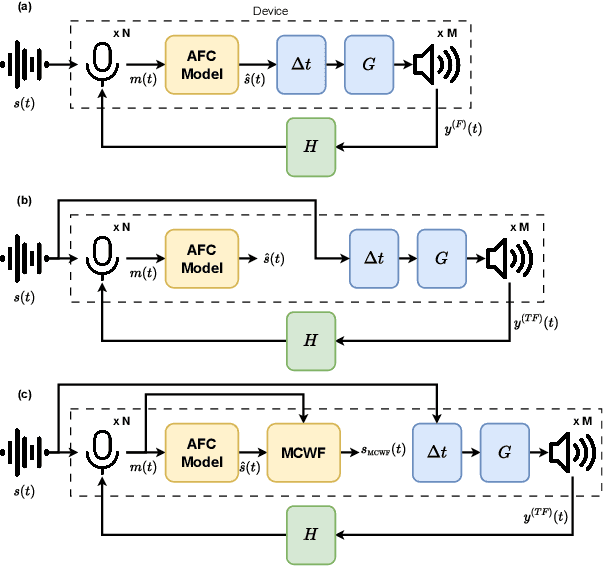
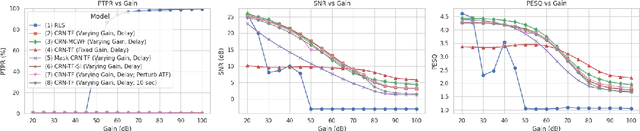
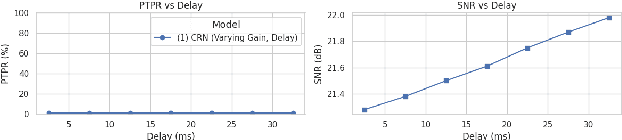
This study presents a deep-learning framework for controlling multichannel acoustic feedback in audio devices. Traditional digital signal processing methods struggle with convergence when dealing with highly correlated noise such as feedback. We introduce a Convolutional Recurrent Network that efficiently combines spatial and temporal processing, significantly enhancing speech enhancement capabilities with lower computational demands. Our approach utilizes three training methods: In-a-Loop Training, Teacher Forcing, and a Hybrid strategy with a Multichannel Wiener Filter, optimizing performance in complex acoustic environments. This scalable framework offers a robust solution for real-world applications, making significant advances in Acoustic Feedback Control technology.
All Neural Low-latency Directional Speech Extraction
Jul 05, 2024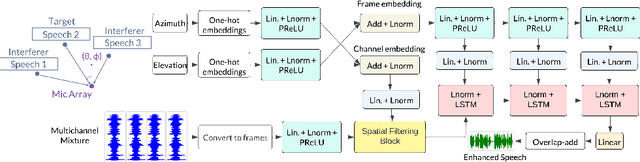
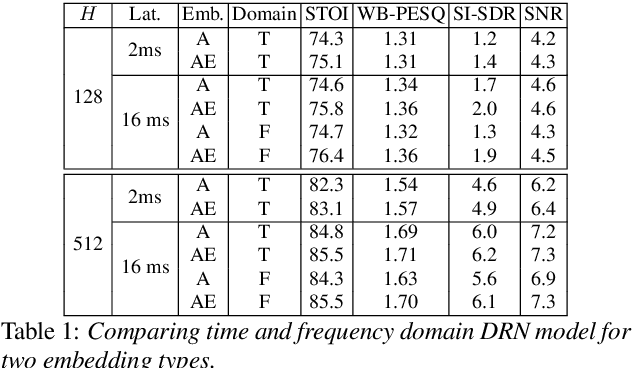
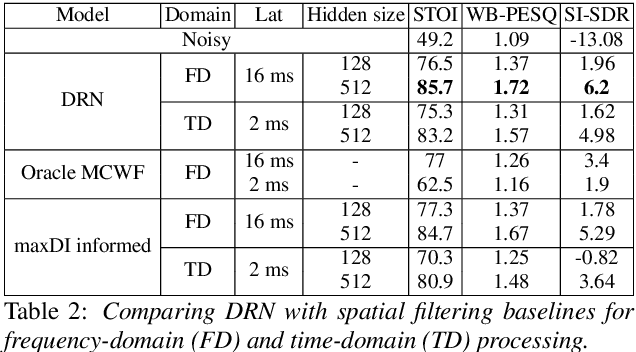
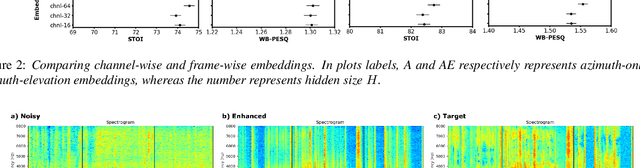
We introduce a novel all neural model for low-latency directional speech extraction. The model uses direction of arrival (DOA) embeddings from a predefined spatial grid, which are transformed and fused into a recurrent neural network based speech extraction model. This process enables the model to effectively extract speech from a specified DOA. Unlike previous methods that relied on hand-crafted directional features, the proposed model trains DOA embeddings from scratch using speech enhancement loss, making it suitable for low-latency scenarios. Additionally, it operates at a high frame rate, taking in DOA with each input frame, which brings in the capability of quickly adapting to changing scene in highly dynamic real-world scenarios. We provide extensive evaluation to demonstrate the model's efficacy in directional speech extraction, robustness to DOA mismatch, and its capability to quickly adapt to abrupt changes in DOA.