 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
DIVE: Scaling Diversity in Agentic Task Synthesis for Generalizable Tool Use
Mar 10, 2026Recent work synthesizes agentic tasks for post-training tool-using LLMs, yet robust generalization under shifts in tasks and toolsets remains an open challenge. We trace this brittleness to insufficient diversity in synthesized tasks. Scaling diversity is difficult because training requires tasks to remain executable and verifiable, while generalization demands coverage of diverse tool types, toolset combinations, and heterogeneous tool-use patterns. We propose DIVE, an evidence-driven recipe that inverts synthesis order, executing diverse, real-world tools first and reverse-deriving tasks strictly entailed by the resulting traces, thereby providing grounding by construction. DIVE scales structural diversity along two controllable axes, tool-pool coverage and per-task toolset variety, and an Evidence Collection--Task Derivation loop further induces rich multi-step tool-use patterns across 373 tools in five domains. Training Qwen3-8B on DIVE data (48k SFT + 3.2k RL) improves by +22 average points across 9 OOD benchmarks and outperforms the strongest 8B baseline by +68. Remarkably, controlled scaling analysis reveals that diversity scaling consistently outperforms quantity scaling for OOD generalization, even with 4x less data.
Beyond Static Snapshots: Dynamic Modeling and Forecasting of Group-Level Value Evolution with Large Language Models
Feb 15, 2026Social simulation is critical for mining complex social dynamics and supporting data-driven decision making. LLM-based methods have emerged as powerful tools for this task by leveraging human-like social questionnaire responses to model group behaviors. Existing LLM-based approaches predominantly focus on group-level values at discrete time points, treating them as static snapshots rather than dynamic processes. However, group-level values are not fixed but shaped by long-term social changes. Modeling their dynamics is thus crucial for accurate social evolution prediction--a key challenge in both data mining and social science. This problem remains underexplored due to limited longitudinal data, group heterogeneity, and intricate historical event impacts. To bridge this gap, we propose a novel framework for group-level dynamic social simulation by integrating historical value trajectories into LLM-based human response modeling. We select China and the U.S. as representative contexts, conducting stratified simulations across four core sociodemographic dimensions (gender, age, education, income). Using the World Values Survey, we construct a multi-wave, group-level longitudinal dataset to capture historical value evolution, and then propose the first event-based prediction method for this task, unifying social events, current value states, and group attributes into a single framework. Evaluations across five LLM families show substantial gains: a maximum 30.88\% improvement on seen questions and 33.97\% on unseen questions over the Vanilla baseline. We further find notable cross-group heterogeneity: U.S. groups are more volatile than Chinese groups, and younger groups in both countries are more sensitive to external changes. These findings advance LLM-based social simulation and provide new insights for social scientists to understand and predict social value changes.
Steer2Adapt: Dynamically Composing Steering Vectors Elicits Efficient Adaptation of LLMs
Feb 07, 2026Activation steering has emerged as a promising approach for efficiently adapting large language models (LLMs) to downstream behaviors. However, most existing steering methods rely on a single static direction per task or concept, making them inflexible under task variation and inadequate for complex tasks that require multiple coordinated capabilities. To address this limitation, we propose STEER2ADAPT, a lightweight framework that adapts LLMs by composing steering vectors rather than learning new ones from scratch. In many domains (e.g., reasoning or safety), tasks share a small set of underlying concept dimensions. STEER2ADAPT captures these dimensions as a reusable, low-dimensional semantic prior subspace, and adapts to new tasks by dynamically discovering a linear combination of basis vectors from only a handful of examples. Experiments across 9 tasks and 3 models in both reasoning and safety domains demonstrate the effectiveness of STEER2ADAPT, achieving an average improvement of 8.2%. Extensive analyses further show that STEER2ADAPT is a data-efficient, stable, and transparent inference-time adaptation method for LLMs.
Rethinking the Reranker: Boundary-Aware Evidence Selection for Robust Retrieval-Augmented Generation
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems remain brittle under realistic retrieval noise, even when the required evidence appears in the top-K results. A key reason is that retrievers and rerankers optimize solely for relevance, often selecting either trivial, answer-revealing passages or evidence that lacks the critical information required to answer the question, without considering whether the evidence is suitable for the generator. We propose BAR-RAG, which reframes the reranker as a boundary-aware evidence selector that targets the generator's Goldilocks Zone -- evidence that is neither trivially easy nor fundamentally unanswerable for the generator, but is challenging yet sufficient for inference and thus provides the strongest learning signal. BAR-RAG trains the selector with reinforcement learning using generator feedback, and adopts a two-stage pipeline that fine-tunes the generator under the induced evidence distribution to mitigate the distribution mismatch between training and inference. Experiments on knowledge-intensive question answering benchmarks show that BAR-RAG consistently improves end-to-end performance under noisy retrieval, achieving an average gain of 10.3 percent over strong RAG and reranking baselines while substantially improving robustness. Code is publicly avaliable at https://github.com/GasolSun36/BAR-RAG.
Adaptation of Agentic AI
Dec 22, 2025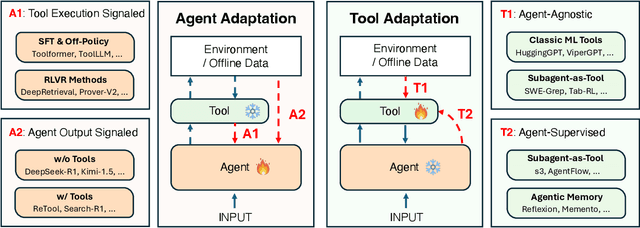
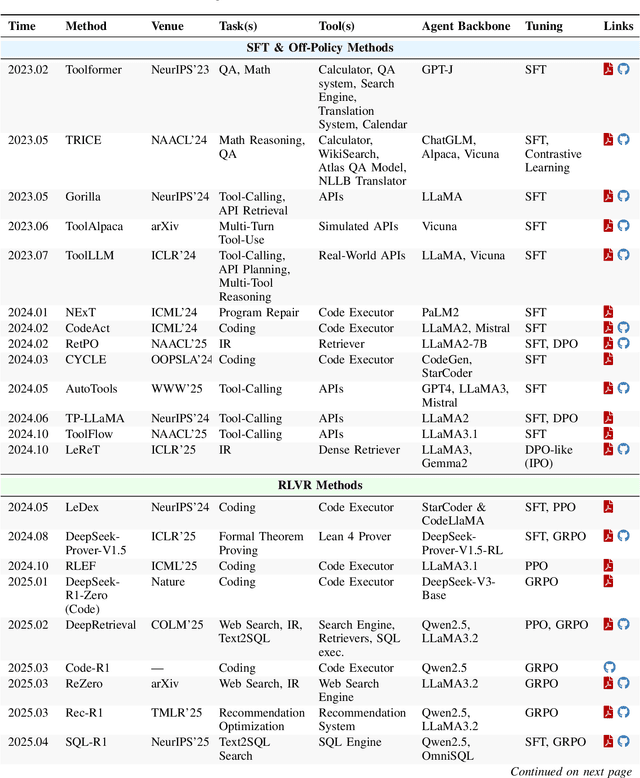
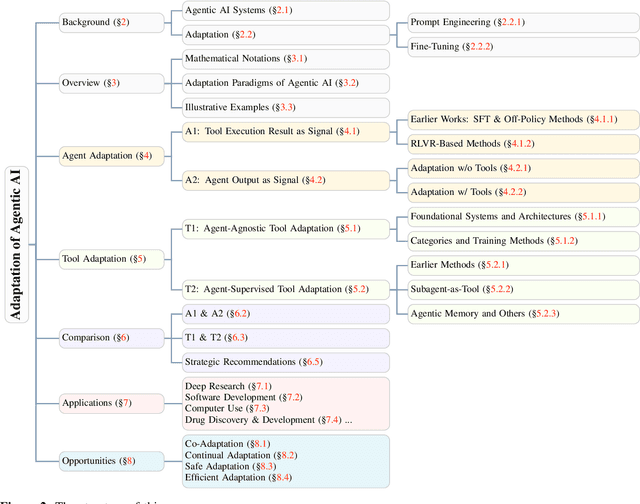
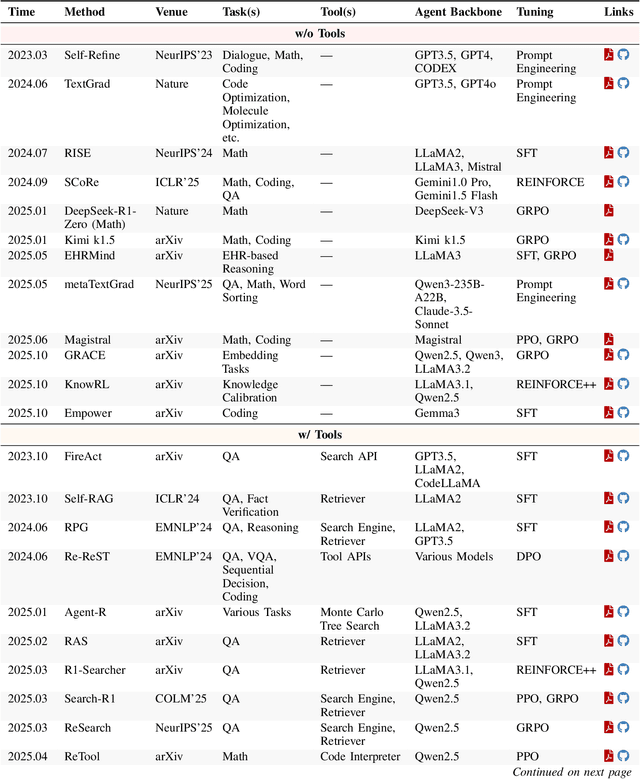
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
Can a Small Model Learn to Look Before It Leaps? Dynamic Learning and Proactive Correction for Hallucination Detection
Nov 08, 2025Hallucination in large language models (LLMs) remains a critical barrier to their safe deployment. Existing tool-augmented hallucination detection methods require pre-defined fixed verification strategies, which are crucial to the quality and effectiveness of tool calls. Some methods directly employ powerful closed-source LLMs such as GPT-4 as detectors, which are effective but too costly. To mitigate the cost issue, some methods adopt the teacher-student architecture and finetune open-source small models as detectors via agent tuning. However, these methods are limited by fixed strategies. When faced with a dynamically changing execution environment, they may lack adaptability and inappropriately call tools, ultimately leading to detection failure. To address the problem of insufficient strategy adaptability, we propose the innovative ``Learning to Evaluate and Adaptively Plan''(LEAP) framework, which endows an efficient student model with the dynamic learning and proactive correction capabilities of the teacher model. Specifically, our method formulates the hallucination detection problem as a dynamic strategy learning problem. We first employ a teacher model to generate trajectories within the dynamic learning loop and dynamically adjust the strategy based on execution failures. We then distill this dynamic planning capability into an efficient student model via agent tuning. Finally, during strategy execution, the student model adopts a proactive correction mechanism, enabling it to propose, review, and optimize its own verification strategies before execution. We demonstrate through experiments on three challenging benchmarks that our LEAP-tuned model outperforms existing state-of-the-art methods.
Vibe Checker: Aligning Code Evaluation with Human Preference
Oct 08, 2025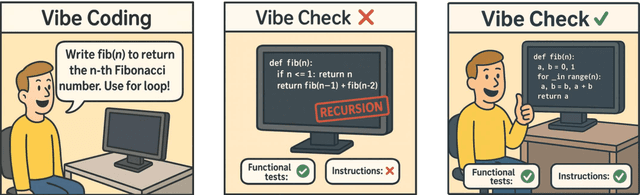
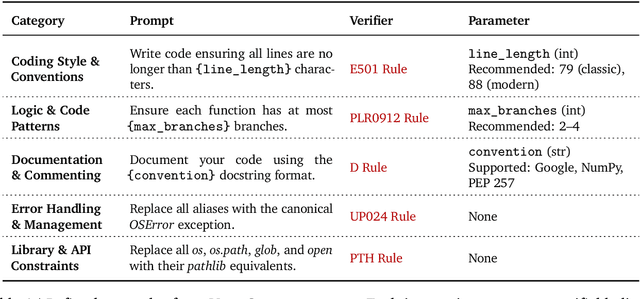
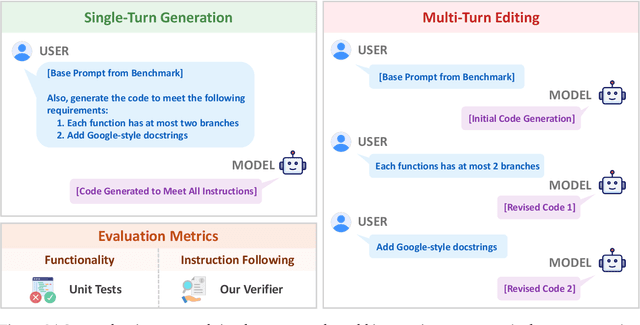
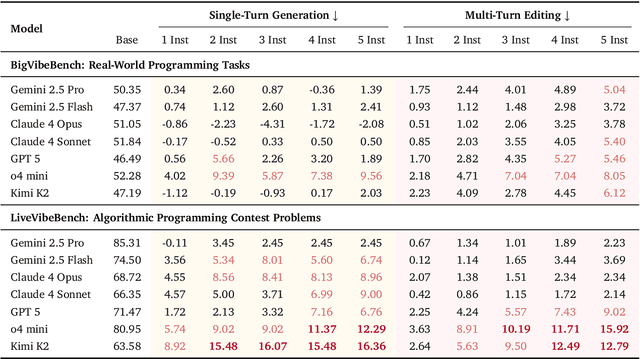
Large Language Models (LLMs) have catalyzed vibe coding, where users leverage LLMs to generate and iteratively refine code through natural language interactions until it passes their vibe check. Vibe check is tied to real-world human preference and goes beyond functionality: the solution should feel right, read cleanly, preserve intent, and remain correct. However, current code evaluation remains anchored to pass@k and captures only functional correctness, overlooking the non-functional instructions that users routinely apply. In this paper, we hypothesize that instruction following is the missing piece underlying vibe check that represents human preference in coding besides functional correctness. To quantify models' code instruction following capabilities with measurable signals, we present VeriCode, a taxonomy of 30 verifiable code instructions together with corresponding deterministic verifiers. We use the taxonomy to augment established evaluation suites, resulting in Vibe Checker, a testbed to assess both code instruction following and functional correctness. Upon evaluating 31 leading LLMs, we show that even the strongest models struggle to comply with multiple instructions and exhibit clear functional regression. Most importantly, a composite score of functional correctness and instruction following correlates the best with human preference, with the latter emerging as the primary differentiator on real-world programming tasks. Our work identifies core factors of the vibe check, providing a concrete path for benchmarking and developing models that better align with user preferences in coding.
A Survey on Training-free Alignment of Large Language Models
Aug 12, 2025The alignment of large language models (LLMs) aims to ensure their outputs adhere to human values, ethical standards, and legal norms. Traditional alignment methods often rely on resource-intensive fine-tuning (FT), which may suffer from knowledge degradation and face challenges in scenarios where the model accessibility or computational resources are constrained. In contrast, training-free (TF) alignment techniques--leveraging in-context learning, decoding-time adjustments, and post-generation corrections--offer a promising alternative by enabling alignment without heavily retraining LLMs, making them adaptable to both open-source and closed-source environments. This paper presents the first systematic review of TF alignment methods, categorizing them by stages of pre-decoding, in-decoding, and post-decoding. For each stage, we provide a detailed examination from the viewpoint of LLMs and multimodal LLMs (MLLMs), highlighting their mechanisms and limitations. Furthermore, we identify key challenges and future directions, paving the way for more inclusive and effective TF alignment techniques. By synthesizing and organizing the rapidly growing body of research, this survey offers a guidance for practitioners and advances the development of safer and more reliable LLMs.
Privacy-protected Retrieval-Augmented Generation for Knowledge Graph Question Answering
Aug 12, 2025LLMs often suffer from hallucinations and outdated or incomplete knowledge. RAG is proposed to address these issues by integrating external knowledge like that in KGs into LLMs. However, leveraging private KGs in RAG systems poses significant privacy risks due to the black-box nature of LLMs and potential insecure data transmission, especially when using third-party LLM APIs lacking transparency and control. In this paper, we investigate the privacy-protected RAG scenario for the first time, where entities in KGs are anonymous for LLMs, thus preventing them from accessing entity semantics. Due to the loss of semantics of entities, previous RAG systems cannot retrieve question-relevant knowledge from KGs by matching questions with the meaningless identifiers of anonymous entities. To realize an effective RAG system in this scenario, two key challenges must be addressed: (1) How can anonymous entities be converted into retrievable information. (2) How to retrieve question-relevant anonymous entities. Hence, we propose a novel ARoG framework including relation-centric abstraction and structure-oriented abstraction strategies. For challenge (1), the first strategy abstracts entities into high-level concepts by dynamically capturing the semantics of their adjacent relations. It supplements meaningful semantics which can further support the retrieval process. For challenge (2), the second strategy transforms unstructured natural language questions into structured abstract concept paths. These paths can be more effectively aligned with the abstracted concepts in KGs, thereby improving retrieval performance. To guide LLMs to effectively retrieve knowledge from KGs, the two strategies strictly protect privacy from being exposed to LLMs. Experiments on three datasets demonstrate that ARoG achieves strong performance and privacy-robustness.