 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamOn: Diffusion Language Models For Code Infilling Beyond Fixed-size Canvas
Feb 01, 2026Diffusion Language Models (DLMs) present a compelling alternative to autoregressive models, offering flexible, any-order infilling without specialized prompting design. However, their practical utility is blocked by a critical limitation: the requirement of a fixed-length masked sequence for generation. This constraint severely degrades code infilling performance when the predefined mask size mismatches the ideal completion length. To address this, we propose DreamOn, a novel diffusion framework that enables dynamic, variable-length generation. DreamOn augments the diffusion process with two length control states, allowing the model to autonomously expand or contract the output length based solely on its own predictions. We integrate this mechanism into existing DLMs with minimal modifications to the training objective and no architectural changes. Built upon Dream-Coder-7B and DiffuCoder-7B, DreamOn achieves infilling performance on par with state-of-the-art autoregressive models on HumanEval-Infilling and SantaCoder-FIM and matches oracle performance achieved with ground-truth length. Our work removes a fundamental barrier to the practical deployment of DLMs, significantly advancing their flexibility and applicability for variable-length generation. Our code is available at https://github.com/DreamLM/DreamOn.
OVD: On-policy Verbal Distillation
Jan 29, 2026Knowledge distillation offers a promising path to transfer reasoning capabilities from large teacher models to efficient student models; however, existing token-level on-policy distillation methods require token-level alignment between the student and teacher models, which restricts the student model's exploration ability, prevent effective use of interactive environment feedback, and suffer from severe memory bottlenecks in reinforcement learning. We introduce On-policy Verbal Distillation (OVD), a memory-efficient framework that replaces token-level probability matching with trajectory matching using discrete verbal scores (0--9) from teacher models. OVD dramatically reduces memory consumption while enabling on-policy distillation from teacher models with verbal feedback, and avoids token-level alignment, allowing the student model to freely explore the output space. Extensive experiments on Web question answering and mathematical reasoning tasks show that OVD substantially outperforms existing methods, delivering up to +12.9% absolute improvement in average EM on Web Q&A tasks and a up to +25.7% gain on math benchmarks (when trained with only one random samples), while also exhibiting superior training efficiency. Our project page is available at https://OVD.github.io
Dream-VL & Dream-VLA: Open Vision-Language and Vision-Language-Action Models with Diffusion Language Model Backbone
Dec 27, 2025While autoregressive Large Vision-Language Models (VLMs) have achieved remarkable success, their sequential generation often limits their efficacy in complex visual planning and dynamic robotic control. In this work, we investigate the potential of constructing Vision-Language Models upon diffusion-based large language models (dLLMs) to overcome these limitations. We introduce Dream-VL, an open diffusion-based VLM (dVLM) that achieves state-of-the-art performance among previous dVLMs. Dream-VL is comparable to top-tier AR-based VLMs trained on open data on various benchmarks but exhibits superior potential when applied to visual planning tasks. Building upon Dream-VL, we introduce Dream-VLA, a dLLM-based Vision-Language-Action model (dVLA) developed through continuous pre-training on open robotic datasets. We demonstrate that the natively bidirectional nature of this diffusion backbone serves as a superior foundation for VLA tasks, inherently suited for action chunking and parallel generation, leading to significantly faster convergence in downstream fine-tuning. Dream-VLA achieves top-tier performance of 97.2% average success rate on LIBERO, 71.4% overall average on SimplerEnv-Bridge, and 60.5% overall average on SimplerEnv-Fractal, surpassing leading models such as $π_0$ and GR00T-N1. We also validate that dVLMs surpass AR baselines on downstream tasks across different training objectives. We release both Dream-VL and Dream-VLA to facilitate further research in the community.
EconProver: Towards More Economical Test-Time Scaling for Automated Theorem Proving
Sep 16, 2025Large Language Models (LLMs) have recently advanced the field of Automated Theorem Proving (ATP), attaining substantial performance gains through widely adopted test-time scaling strategies, notably reflective Chain-of-Thought (CoT) reasoning and increased sampling passes. However, they both introduce significant computational overhead for inference. Moreover, existing cost analyses typically regulate only the number of sampling passes, while neglecting the substantial disparities in sampling costs introduced by different scaling strategies. In this paper, we systematically compare the efficiency of different test-time scaling strategies for ATP models and demonstrate the inefficiency of the current state-of-the-art (SOTA) open-source approaches. We then investigate approaches to significantly reduce token usage and sample passes while maintaining the original performance. Specifically, we propose two complementary methods that can be integrated into a unified EconRL pipeline for amplified benefits: (1) a dynamic Chain-of-Thought (CoT) switching mechanism designed to mitigate unnecessary token consumption, and (2) Diverse parallel-scaled reinforcement learning (RL) with trainable prefixes to enhance pass rates under constrained sampling passes. Experiments on miniF2F and ProofNet demonstrate that our EconProver achieves comparable performance to baseline methods with only 12% of the computational cost. This work provides actionable insights for deploying lightweight ATP models without sacrificing performance.
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
Jun 26, 2025Diffusion large language models (dLLMs) are compelling alternatives to autoregressive (AR) models because their denoising models operate over the entire sequence. The global planning and iterative refinement features of dLLMs are particularly useful for code generation. However, current training and inference mechanisms for dLLMs in coding are still under-explored. To demystify the decoding behavior of dLLMs and unlock their potential for coding, we systematically investigate their denoising processes and reinforcement learning (RL) methods. We train a 7B dLLM, \textbf{DiffuCoder}, on 130B tokens of code. Using this model as a testbed, we analyze its decoding behavior, revealing how it differs from that of AR models: (1) dLLMs can decide how causal their generation should be without relying on semi-AR decoding, and (2) increasing the sampling temperature diversifies not only token choices but also their generation order. This diversity creates a rich search space for RL rollouts. For RL training, to reduce the variance of token log-likelihood estimates and maintain training efficiency, we propose \textbf{coupled-GRPO}, a novel sampling scheme that constructs complementary mask noise for completions used in training. In our experiments, coupled-GRPO significantly improves DiffuCoder's performance on code generation benchmarks (+4.4\% on EvalPlus) and reduces reliance on AR bias during decoding. Our work provides deeper insight into the machinery of dLLM generation and offers an effective, diffusion-native RL training framework. https://github.com/apple/ml-diffucoder.
GIRAFFE: Design Choices for Extending the Context Length of Visual Language Models
Dec 17, 2024
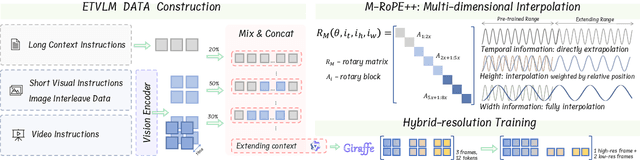
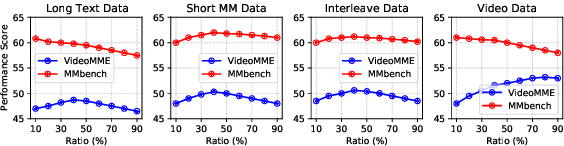
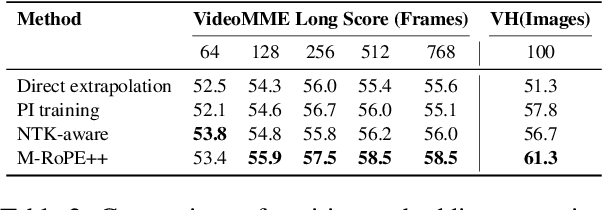
Visual Language Models (VLMs) demonstrate impressive capabilities in processing multimodal inputs, yet applications such as visual agents, which require handling multiple images and high-resolution videos, demand enhanced long-range modeling. Moreover, existing open-source VLMs lack systematic exploration into extending their context length, and commercial models often provide limited details. To tackle this, we aim to establish an effective solution that enhances long context performance of VLMs while preserving their capacities in short context scenarios. Towards this goal, we make the best design choice through extensive experiment settings from data curation to context window extending and utilizing: (1) we analyze data sources and length distributions to construct ETVLM - a data recipe to balance the performance across scenarios; (2) we examine existing position extending methods, identify their limitations and propose M-RoPE++ as an enhanced approach; we also choose to solely instruction-tune the backbone with mixed-source data; (3) we discuss how to better utilize extended context windows and propose hybrid-resolution training. Built on the Qwen-VL series model, we propose Giraffe, which is effectively extended to 128K lengths. Evaluated on extensive long context VLM benchmarks such as VideoMME and Viusal Haystacks, our Giraffe achieves state-of-the-art performance among similarly sized open-source long VLMs and is competitive with commercial model GPT-4V. We will open-source the code, data, and models.
Why Does the Effective Context Length of LLMs Fall Short?
Oct 24, 2024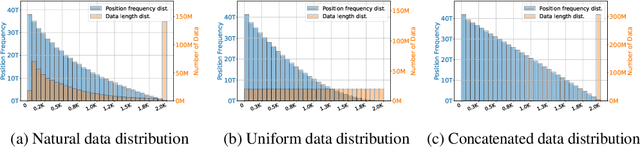
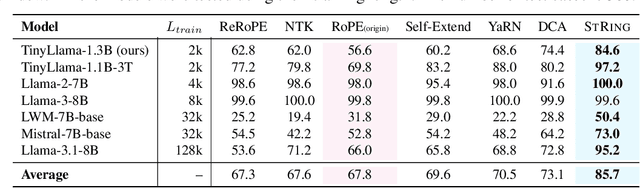
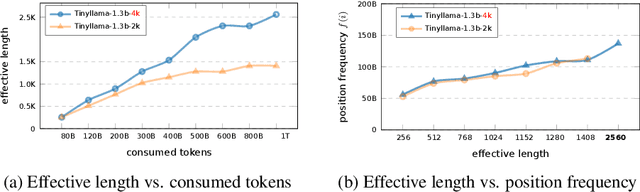
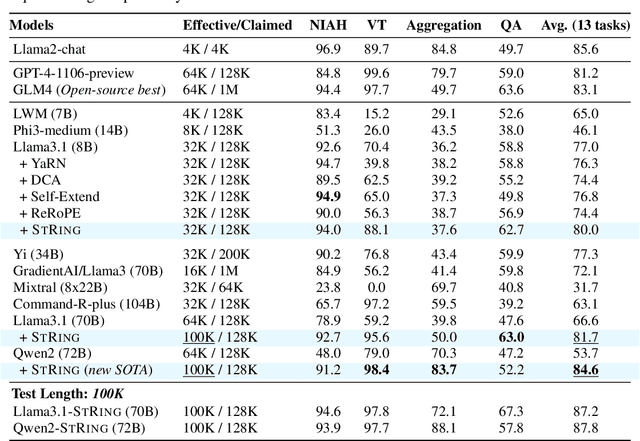
Advancements in distributed training and efficient attention mechanisms have significantly expanded the context window sizes of large language models (LLMs). However, recent work reveals that the effective context lengths of open-source LLMs often fall short, typically not exceeding half of their training lengths. In this work, we attribute this limitation to the left-skewed frequency distribution of relative positions formed in LLMs pretraining and post-training stages, which impedes their ability to effectively gather distant information. To address this challenge, we introduce ShifTed Rotray position embeddING (STRING). STRING shifts well-trained positions to overwrite the original ineffective positions during inference, enhancing performance within their existing training lengths. Experimental results show that without additional training, STRING dramatically improves the performance of the latest large-scale models, such as Llama3.1 70B and Qwen2 72B, by over 10 points on popular long-context benchmarks RULER and InfiniteBench, establishing new state-of-the-art results for open-source LLMs. Compared to commercial models, Llama 3.1 70B with \method even achieves better performance than GPT-4-128K and clearly surpasses Claude 2 and Kimi-chat.
Scaling Diffusion Language Models via Adaptation from Autoregressive Models
Oct 23, 2024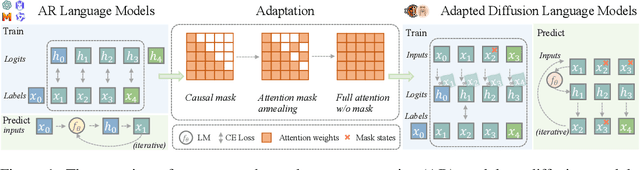
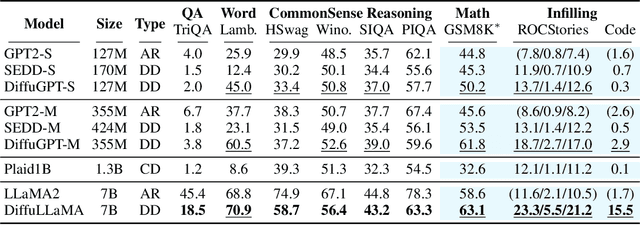
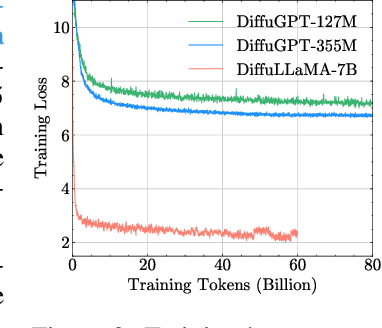
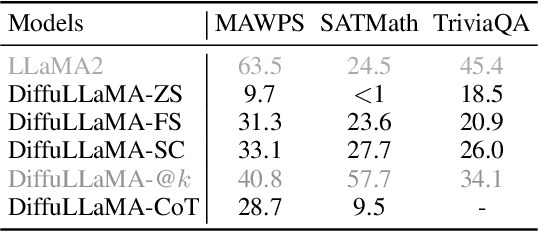
Diffusion Language Models (DLMs) have emerged as a promising new paradigm for text generative modeling, potentially addressing limitations of autoregressive (AR) models. However, current DLMs have been studied at a smaller scale compared to their AR counterparts and lack fair comparison on language modeling benchmarks. Additionally, training diffusion models from scratch at scale remains challenging. Given the prevalence of open-source AR language models, we propose adapting these models to build text diffusion models. We demonstrate connections between AR and diffusion modeling objectives and introduce a simple continual pre-training approach for training diffusion models. Through systematic evaluation on language modeling, reasoning, and commonsense benchmarks, we show that we can convert AR models ranging from 127M to 7B parameters (GPT2 and LLaMA) into diffusion models DiffuGPT and DiffuLLaMA, using less than 200B tokens for training. Our experimental results reveal that these models outperform earlier DLMs and are competitive with their AR counterparts. We release a suite of DLMs (with 127M, 355M, and 7B parameters) capable of generating fluent text, performing in-context learning, filling in the middle without prompt re-ordering, and following instructions \url{https://github.com/HKUNLP/DiffuLLaMA}.
Beyond Autoregression: Discrete Diffusion for Complex Reasoning and Planning
Oct 18, 2024



Autoregressive language models, despite their impressive capabilities, struggle with complex reasoning and long-term planning tasks. We introduce discrete diffusion models as a novel solution to these challenges. Through the lens of subgoal imbalance, we demonstrate how diffusion models effectively learn difficult subgoals that elude autoregressive approaches. We propose Multi-granularity Diffusion Modeling (MDM), which prioritizes subgoals based on difficulty during learning. On complex tasks like Countdown, Sudoku, and Boolean Satisfiability Problems, MDM significantly outperforms autoregressive models without using search techniques. For instance, MDM achieves 91.5\% and 100\% accuracy on Countdown and Sudoku, respectively, compared to 45.8\% and 20.7\% for autoregressive models. Our work highlights the potential of diffusion-based approaches in advancing AI capabilities for sophisticated language understanding and problem-solving tasks.
Training-Free Long-Context Scaling of Large Language Models
Feb 27, 2024The ability of Large Language Models (LLMs) to process and generate coherent text is markedly weakened when the number of input tokens exceeds their pretraining length. Given the expensive overhead of finetuning large-scale models with longer sequences, we propose Dual Chunk Attention (DCA), which enables Llama2 70B to support context windows of more than 100k tokens without continual training. By decomposing the attention computation for long sequences into chunk-based modules, DCA manages to effectively capture the relative positional information of tokens within the same chunk (Intra-Chunk) and across distinct chunks (Inter-Chunk), as well as integrates seamlessly with Flash Attention. In addition to its impressive extrapolation capability, DCA achieves performance on practical long-context tasks that is comparable to or even better than that of finetuned models. When compared with proprietary models, our training-free 70B model attains 94% of the performance of gpt-3.5-16k, indicating it is a viable open-source alternative. All code and data used in this work are released at \url{https://github.com/HKUNLP/ChunkLlama}.