 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Merging in Pre-training of Large Language Models
May 17, 2025Model merging has emerged as a promising technique for enhancing large language models, though its application in large-scale pre-training remains relatively unexplored. In this paper, we present a comprehensive investigation of model merging techniques during the pre-training process. Through extensive experiments with both dense and Mixture-of-Experts (MoE) architectures ranging from millions to over 100 billion parameters, we demonstrate that merging checkpoints trained with constant learning rates not only achieves significant performance improvements but also enables accurate prediction of annealing behavior. These improvements lead to both more efficient model development and significantly lower training costs. Our detailed ablation studies on merging strategies and hyperparameters provide new insights into the underlying mechanisms while uncovering novel applications. Through comprehensive experimental analysis, we offer the open-source community practical pre-training guidelines for effective model merging.
FlexPrefill: A Context-Aware Sparse Attention Mechanism for Efficient Long-Sequence Inference
Feb 28, 2025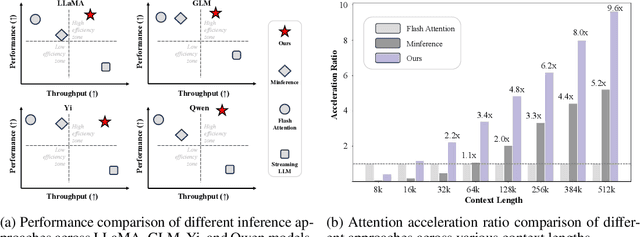



Large language models (LLMs) encounter computational challenges during long-sequence inference, especially in the attention pre-filling phase, where the complexity grows quadratically with the prompt length. Previous efforts to mitigate these challenges have relied on fixed sparse attention patterns or identifying sparse attention patterns based on limited cases. However, these methods lacked the flexibility to efficiently adapt to varying input demands. In this paper, we introduce FlexPrefill, a Flexible sparse Pre-filling mechanism that dynamically adjusts sparse attention patterns and computational budget in real-time to meet the specific requirements of each input and attention head. The flexibility of our method is demonstrated through two key innovations: 1) Query-Aware Sparse Pattern Determination: By measuring Jensen-Shannon divergence, this component adaptively switches between query-specific diverse attention patterns and predefined attention patterns. 2) Cumulative-Attention Based Index Selection: This component dynamically selects query-key indexes to be computed based on different attention patterns, ensuring the sum of attention scores meets a predefined threshold. FlexPrefill adaptively optimizes the sparse pattern and sparse ratio of each attention head based on the prompt, enhancing efficiency in long-sequence inference tasks. Experimental results show significant improvements in both speed and accuracy over prior methods, providing a more flexible and efficient solution for LLM inference.
Why Does the Effective Context Length of LLMs Fall Short?
Oct 24, 2024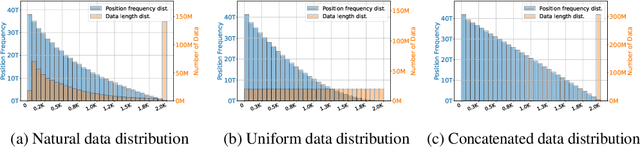
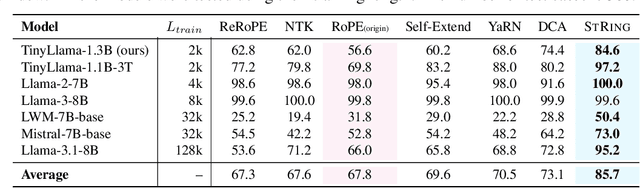
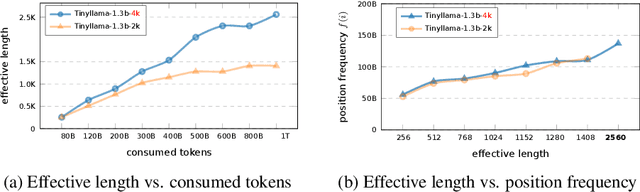
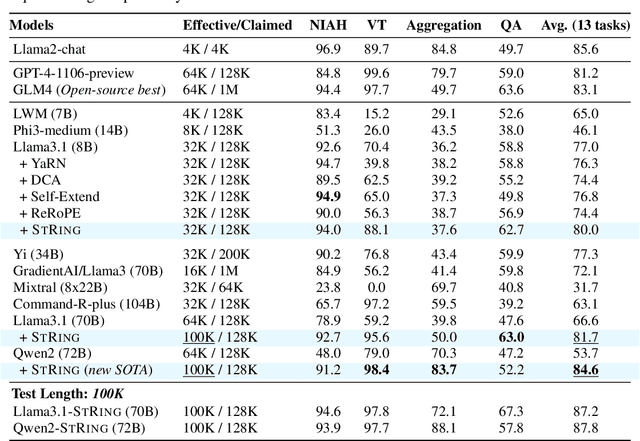
Advancements in distributed training and efficient attention mechanisms have significantly expanded the context window sizes of large language models (LLMs). However, recent work reveals that the effective context lengths of open-source LLMs often fall short, typically not exceeding half of their training lengths. In this work, we attribute this limitation to the left-skewed frequency distribution of relative positions formed in LLMs pretraining and post-training stages, which impedes their ability to effectively gather distant information. To address this challenge, we introduce ShifTed Rotray position embeddING (STRING). STRING shifts well-trained positions to overwrite the original ineffective positions during inference, enhancing performance within their existing training lengths. Experimental results show that without additional training, STRING dramatically improves the performance of the latest large-scale models, such as Llama3.1 70B and Qwen2 72B, by over 10 points on popular long-context benchmarks RULER and InfiniteBench, establishing new state-of-the-art results for open-source LLMs. Compared to commercial models, Llama 3.1 70B with \method even achieves better performance than GPT-4-128K and clearly surpasses Claude 2 and Kimi-chat.
Learning Robust 3D Face Reconstruction and Discriminative Identity Representation
May 16, 2019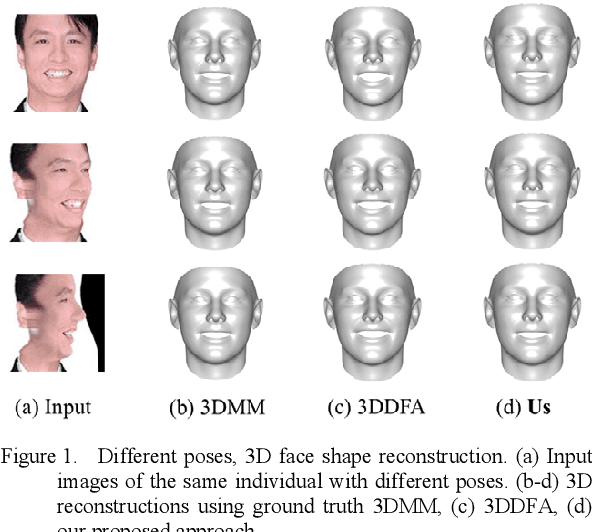
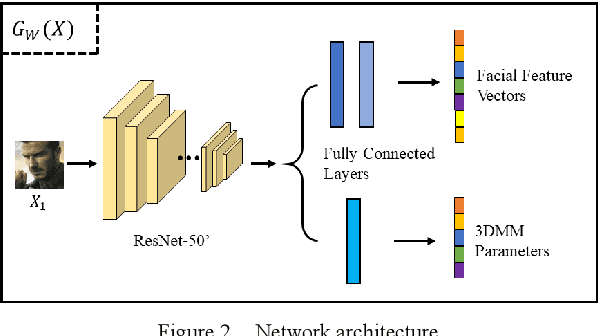
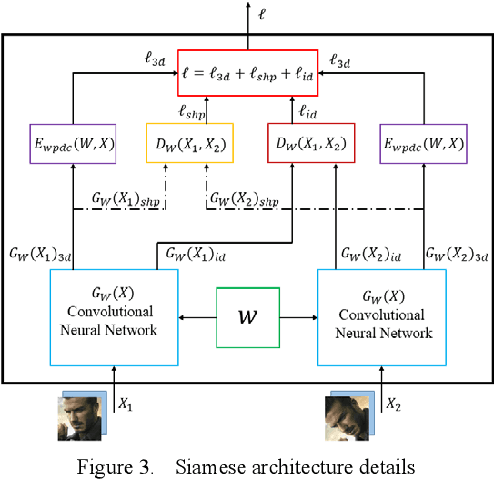
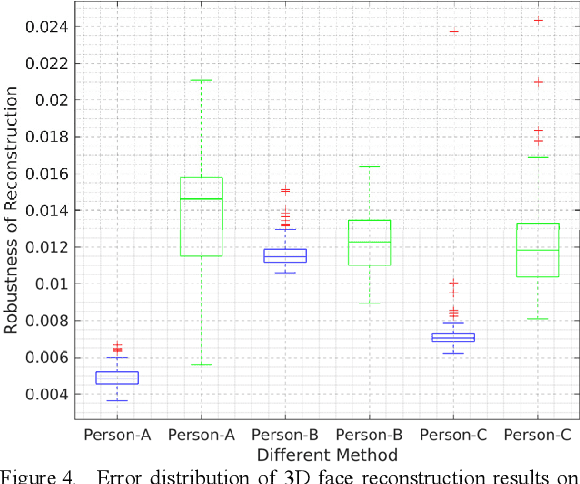
3D face reconstruction from a single 2D image is a very important topic in computer vision. However, the current reconstruction methods are usually non-sensitive to face identities and over-sensitive to facial poses, which may result in similar 3D geometries for faces of different identities, or obtain different shapes for the same identity with different poses. When such methods are applied practically, their 3D estimates are either changeable for different photos of the same subject or over-regularized and generic to distinguish face identities. In this paper, we propose a robust solution to solve this problem by carefully designing a novel Siamese Convolutional Neural Network (SCNN). Specifically, regarding the 3D Morphable face Model (3DMM) parameters of the same individual as the same class, we employ the contrastive loss to enlarge the inter-class distance and meanwhile reduce the intra-class distance for the output 3DMM parameters. We also propose an identity loss to preserve the identity information for the same individual in the feature space. Training with these two losses, our SCNN could learn representations that are more discriminative for face identity and generalizable for pose variants. Experiments on the challenging database 300W-LP and AFLW2000-3D have shown the effectiveness of our method by comparing with state-of-the-arts.
Joint 3D Face Reconstruction and Dense Face Alignment from A Single Image with 2D-Assisted Self-Supervised Learning
Mar 22, 2019
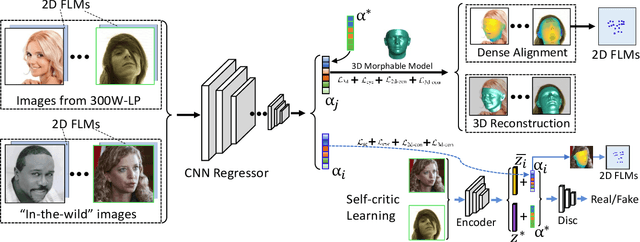

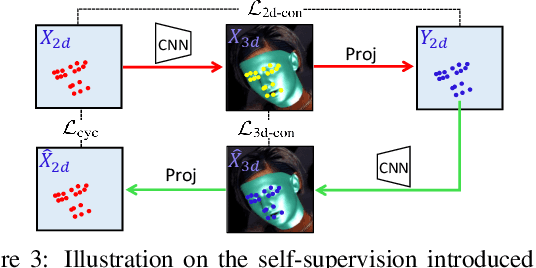
3D face reconstruction from a single 2D image is a challenging problem with broad applications. Recent methods typically aim to learn a CNN-based 3D face model that regresses coefficients of 3D Morphable Model (3DMM) from 2D images to render 3D face reconstruction or dense face alignment. However, the shortage of training data with 3D annotations considerably limits performance of those methods. To alleviate this issue, we propose a novel 2D-assisted self-supervised learning (2DASL) method that can effectively use "in-the-wild" 2D face images with noisy landmark information to substantially improve 3D face model learning. Specifically, taking the sparse 2D facial landmarks as additional information, 2DSAL introduces four novel self-supervision schemes that view the 2D landmark and 3D landmark prediction as a self-mapping process, including the 2D and 3D landmark self-prediction consistency, cycle-consistency over the 2D landmark prediction and self-critic over the predicted 3DMM coefficients based on landmark predictions. Using these four self-supervision schemes, the 2DASL method significantly relieves demands on the the conventional paired 2D-to-3D annotations and gives much higher-quality 3D face models without requiring any additional 3D annotations. Experiments on multiple challenging datasets show that our method outperforms state-of-the-arts for both 3D face reconstruction and dense face alignment by a large margin.
Enhance the Motion Cues for Face Anti-Spoofing using CNN-LSTM Architecture
Jan 17, 2019

Spatio-temporal information is very important to capture the discriminative cues between genuine and fake faces from video sequences. To explore such a temporal feature, the fine-grained motions (e.g., eye blinking, mouth movements and head swing) across video frames are very critical. In this paper, we propose a joint CNN-LSTM network for face anti-spoofing, focusing on the motion cues across video frames. We first extract the high discriminative features of video frames using the conventional Convolutional Neural Network (CNN). Then we leverage Long Short-Term Memory (LSTM) with the extracted features as inputs to capture the temporal dynamics in videos. To ensure the fine-grained motions more easily to be perceived in the training process, the eulerian motion magnification is used as the preprocessing to enhance the facial expressions exhibited by individuals, and the attention mechanism is embedded in LSTM to ensure the model learn to focus selectively on the dynamic frames across the video clips. Experiments on Replay Attack and MSU-MFSD databases show that the proposed method yields state-of-the-art performance with better generalization ability compared with several other popular algorithms.
Deep Transfer Across Domains for Face Anti-spoofing
Jan 17, 2019

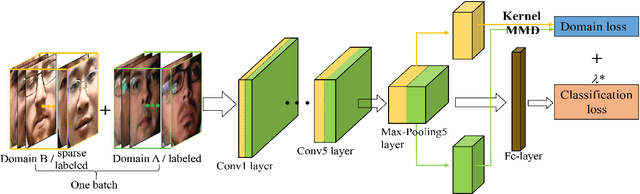
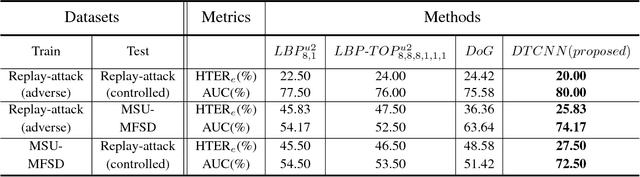
A practical face recognition system demands not only high recognition performance, but also the capability of detecting spoofing attacks. While emerging approaches of face anti-spoofing have been proposed in recent years, most of them do not generalize well to new database. The generalization ability of face anti-spoofing needs to be significantly improved before they can be adopted by practical application systems. The main reason for the poor generalization of current approaches is the variety of materials among the spoofing devices. As the attacks are produced by putting a spoofing display (e.t., paper, electronic screen, forged mask) in front of a camera, the variety of spoofing materials can make the spoofing attacks quite different. Furthermore, the background/lighting condition of a new environment can make both the real accesses and spoofing attacks different. Another reason for the poor generalization is that limited labeled data is available for training in face anti-spoofing. In this paper, we focus on improving the generalization ability across different kinds of datasets. We propose a CNN framework using sparsely labeled data from the target domain to learn features that are invariant across domains for face anti-spoofing. Experiments on public-domain face spoofing databases show that the proposed method significantly improve the cross-dataset testing performance only with a small number of labeled samples from the target domain.