 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance the Motion Cues for Face Anti-Spoofing using CNN-LSTM Architecture
Jan 17, 2019

Spatio-temporal information is very important to capture the discriminative cues between genuine and fake faces from video sequences. To explore such a temporal feature, the fine-grained motions (e.g., eye blinking, mouth movements and head swing) across video frames are very critical. In this paper, we propose a joint CNN-LSTM network for face anti-spoofing, focusing on the motion cues across video frames. We first extract the high discriminative features of video frames using the conventional Convolutional Neural Network (CNN). Then we leverage Long Short-Term Memory (LSTM) with the extracted features as inputs to capture the temporal dynamics in videos. To ensure the fine-grained motions more easily to be perceived in the training process, the eulerian motion magnification is used as the preprocessing to enhance the facial expressions exhibited by individuals, and the attention mechanism is embedded in LSTM to ensure the model learn to focus selectively on the dynamic frames across the video clips. Experiments on Replay Attack and MSU-MFSD databases show that the proposed method yields state-of-the-art performance with better generalization ability compared with several other popular algorithms.
Deep Transfer Across Domains for Face Anti-spoofing
Jan 17, 2019

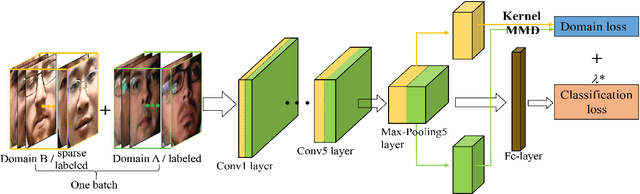
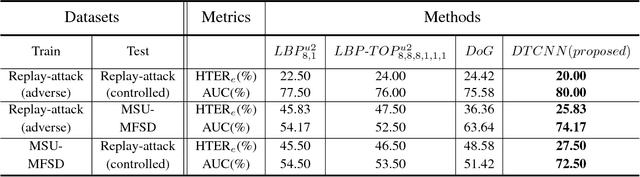
A practical face recognition system demands not only high recognition performance, but also the capability of detecting spoofing attacks. While emerging approaches of face anti-spoofing have been proposed in recent years, most of them do not generalize well to new database. The generalization ability of face anti-spoofing needs to be significantly improved before they can be adopted by practical application systems. The main reason for the poor generalization of current approaches is the variety of materials among the spoofing devices. As the attacks are produced by putting a spoofing display (e.t., paper, electronic screen, forged mask) in front of a camera, the variety of spoofing materials can make the spoofing attacks quite different. Furthermore, the background/lighting condition of a new environment can make both the real accesses and spoofing attacks different. Another reason for the poor generalization is that limited labeled data is available for training in face anti-spoofing. In this paper, we focus on improving the generalization ability across different kinds of datasets. We propose a CNN framework using sparsely labeled data from the target domain to learn features that are invariant across domains for face anti-spoofing. Experiments on public-domain face spoofing databases show that the proposed method significantly improve the cross-dataset testing performance only with a small number of labeled samples from the target domain.