 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-Restorer: Unleashing Visual Prompts for Diffusion-based Universal Image Restoration
Jul 04, 2024



Image restoration is a classic low-level problem aimed at recovering high-quality images from low-quality images with various degradations such as blur, noise, rain, haze, etc. However, due to the inherent complexity and non-uniqueness of degradation in real-world images, it is challenging for a model trained for single tasks to handle real-world restoration problems effectively. Moreover, existing methods often suffer from over-smoothing and lack of realism in the restored results. To address these issues, we propose Diff-Restorer, a universal image restoration method based on the diffusion model, aiming to leverage the prior knowledge of Stable Diffusion to remove degradation while generating high perceptual quality restoration results. Specifically, we utilize the pre-trained visual language model to extract visual prompts from degraded images, including semantic and degradation embeddings. The semantic embeddings serve as content prompts to guide the diffusion model for generation. In contrast, the degradation embeddings modulate the Image-guided Control Module to generate spatial priors for controlling the spatial structure of the diffusion process, ensuring faithfulness to the original image. Additionally, we design a Degradation-aware Decoder to perform structural correction and convert the latent code to the pixel domain. We conducted comprehensive qualitative and quantitative analysis on restoration tasks with different degradations, demonstrating the effectiveness and superiority of our approach.
MRIR: Integrating Multimodal Insights for Diffusion-based Realistic Image Restoration
Jul 04, 2024



Realistic image restoration is a crucial task in computer vision, and the use of diffusion-based models for image restoration has garnered significant attention due to their ability to produce realistic results. However, the quality of the generated images is still a significant challenge due to the severity of image degradation and the uncontrollability of the diffusion model. In this work, we delve into the potential of utilizing pre-trained stable diffusion for image restoration and propose MRIR, a diffusion-based restoration method with multimodal insights. Specifically, we explore the problem from two perspectives: textual level and visual level. For the textual level, we harness the power of the pre-trained multimodal large language model to infer meaningful semantic information from low-quality images. Furthermore, we employ the CLIP image encoder with a designed Refine Layer to capture image details as a supplement. For the visual level, we mainly focus on the pixel level control. Thus, we utilize a Pixel-level Processor and ControlNet to control spatial structures. Finally, we integrate the aforementioned control information into the denoising U-Net using multi-level attention mechanisms and realize controllable image restoration with multimodal insights. The qualitative and quantitative results demonstrate our method's superiority over other state-of-the-art methods on both synthetic and real-world datasets.
A Codec Information Assisted Framework for Efficient Compressed Video Super-Resolution
Oct 15, 2022

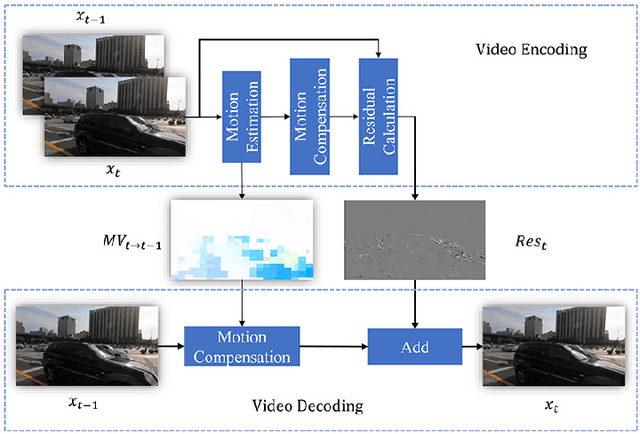
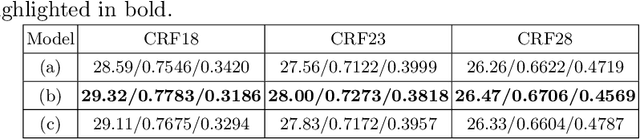
Online processing of compressed videos to increase their resolutions attracts increasing and broad attention. Video Super-Resolution (VSR) using recurrent neural network architecture is a promising solution due to its efficient modeling of long-range temporal dependencies. However, state-of-the-art recurrent VSR models still require significant computation to obtain a good performance, mainly because of the complicated motion estimation for frame/feature alignment and the redundant processing of consecutive video frames. In this paper, considering the characteristics of compressed videos, we propose a Codec Information Assisted Framework (CIAF) to boost and accelerate recurrent VSR models for compressed videos. Firstly, the framework reuses the coded video information of Motion Vectors to model the temporal relationships between adjacent frames. Experiments demonstrate that the models with Motion Vector based alignment can significantly boost the performance with negligible additional computation, even comparable to those using more complex optical flow based alignment. Secondly, by further making use of the coded video information of Residuals, the framework can be informed to skip the computation on redundant pixels. Experiments demonstrate that the proposed framework can save up to 70% of the computation without performance drop on the REDS4 test videos encoded by H.264 when CRF is 23.
Enhance the Motion Cues for Face Anti-Spoofing using CNN-LSTM Architecture
Jan 17, 2019

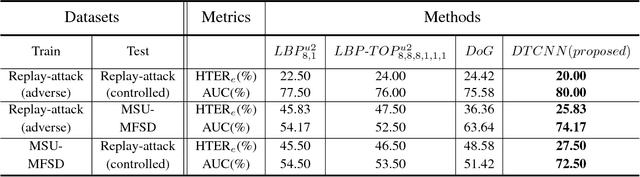
Spatio-temporal information is very important to capture the discriminative cues between genuine and fake faces from video sequences. To explore such a temporal feature, the fine-grained motions (e.g., eye blinking, mouth movements and head swing) across video frames are very critical. In this paper, we propose a joint CNN-LSTM network for face anti-spoofing, focusing on the motion cues across video frames. We first extract the high discriminative features of video frames using the conventional Convolutional Neural Network (CNN). Then we leverage Long Short-Term Memory (LSTM) with the extracted features as inputs to capture the temporal dynamics in videos. To ensure the fine-grained motions more easily to be perceived in the training process, the eulerian motion magnification is used as the preprocessing to enhance the facial expressions exhibited by individuals, and the attention mechanism is embedded in LSTM to ensure the model learn to focus selectively on the dynamic frames across the video clips. Experiments on Replay Attack and MSU-MFSD databases show that the proposed method yields state-of-the-art performance with better generalization ability compared with several other popular algorithms.
Deep Transfer Across Domains for Face Anti-spoofing
Jan 17, 2019

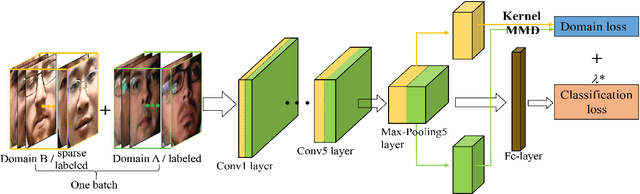
A practical face recognition system demands not only high recognition performance, but also the capability of detecting spoofing attacks. While emerging approaches of face anti-spoofing have been proposed in recent years, most of them do not generalize well to new database. The generalization ability of face anti-spoofing needs to be significantly improved before they can be adopted by practical application systems. The main reason for the poor generalization of current approaches is the variety of materials among the spoofing devices. As the attacks are produced by putting a spoofing display (e.t., paper, electronic screen, forged mask) in front of a camera, the variety of spoofing materials can make the spoofing attacks quite different. Furthermore, the background/lighting condition of a new environment can make both the real accesses and spoofing attacks different. Another reason for the poor generalization is that limited labeled data is available for training in face anti-spoofing. In this paper, we focus on improving the generalization ability across different kinds of datasets. We propose a CNN framework using sparsely labeled data from the target domain to learn features that are invariant across domains for face anti-spoofing. Experiments on public-domain face spoofing databases show that the proposed method significantly improve the cross-dataset testing performance only with a small number of labeled samples from the target domain.
Learning Generalizable and Identity-Discriminative Representations for Face Anti-Spoofing
Jan 17, 2019
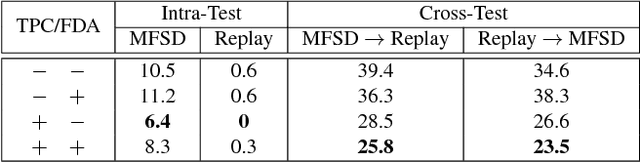
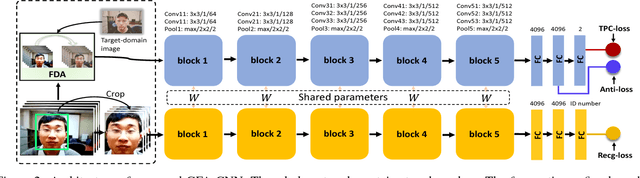

Face anti-spoofing (a.k.a presentation attack detection) has drawn growing attention due to the high-security demand in face authentication systems. Existing CNN-based approaches usually well recognize the spoofing faces when training and testing spoofing samples display similar patterns, but their performance would drop drastically on testing spoofing faces of unseen scenes. In this paper, we try to boost the generalizability and applicability of these methods by designing a CNN model with two major novelties. First, we propose a simple yet effective Total Pairwise Confusion (TPC) loss for CNN training, which enhances the generalizability of the learned Presentation Attack (PA) representations. Secondly, we incorporate a Fast Domain Adaptation (FDA) component into the CNN model to alleviate negative effects brought by domain changes. Besides, our proposed model, which is named Generalizable Face Authentication CNN (GFA-CNN), works in a multi-task manner, performing face anti-spoofing and face recognition simultaneously. Experimental results show that GFA-CNN outperforms previous face anti-spoofing approaches and also well preserves the identity information of input face images.