 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill Weaving: Efficient LLM Improvement via Modular Skillpacks
May 21, 2026Large language models increasingly require specialization across diverse domains, yet existing approaches struggle to balance multi-domain capacities with strict memory and inference constraints. In this work, we introduce SkillWeave, a modular improvement framework that enables LLMs to specialize under fixed memory budgets. SkillWeave partitions full capabilities of a general-purpose model into skillpacks -- lightweight, domain-specific delta modules -- that reorganize and refine the model's internal knowledge. For efficient deployment, SkillWeave integrates SkillZip to compress skillpacks into compact and inference-ready format, enabling strong multi-domain performance with low-latency execution. On multi-task and agentic benchmarks, a 9B SkillWeave model outperforms several baselines and even surpasses a 32B monolithic LLM, while achieving up to 4x speedup.
Vocabulary Hijacking in LVLMs: Unveiling Critical Attention Heads by Excluding Inert Tokens to Mitigate Hallucination
May 11, 2026Large Vision-Language Models (LVLMs) have achieved remarkable progress in multimodal tasks, yet their reliability is persistently undermined by hallucinations-generating text that contradicts visual input. Recent studies often attribute these errors to inadequate visual attention. In this work, we analyze the attention mechanisms via the logit lens, uncovering a distinct anomaly we term Vocabulary Hijacking. We discover that specific visual tokens, defined as Inert Tokens, disproportionately attract attention. Crucially, when their intermediate hidden states are projected into the vocabulary space, they consistently decode to a fixed set of unrelated words (termed Hijacking Anchors) across layers, revealing a rigid semantic collapse. Leveraging this semantic rigidity, we propose Hijacking Anchor-Based Identification (HABI), a robust strategy to accurately localize these Inert Tokens. To quantify the impact of this phenomenon, we introduce the Non-Hijacked Visual Attention Ratio (NHAR), a novel metric designed to identify attention heads that remain resilient to hijacking and are critical for factual accuracy. Building on these insights, we propose Hijacking-Aware Visual Attention Enhancement (HAVAE), a training-free intervention that selectively strengthens the focus of these identified heads on salient visual content. Extensive experiments across multiple benchmarks demonstrate that HAVAE significantly mitigates hallucinations with no additional computational overhead, while preserving the model's general capabilities. Our code is publicly available at https://github.com/lab-klc/HAVAE.
Escaping Stability-Plasticity Dilemma in Online Continual Learning for Motion Forecasting via Synergetic Memory Rehearsal
Aug 27, 2025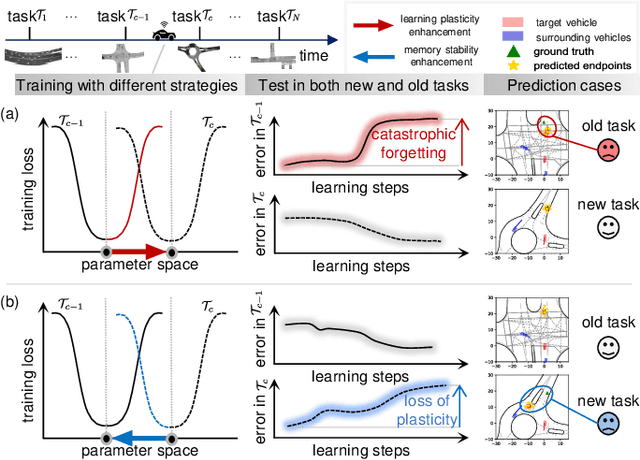
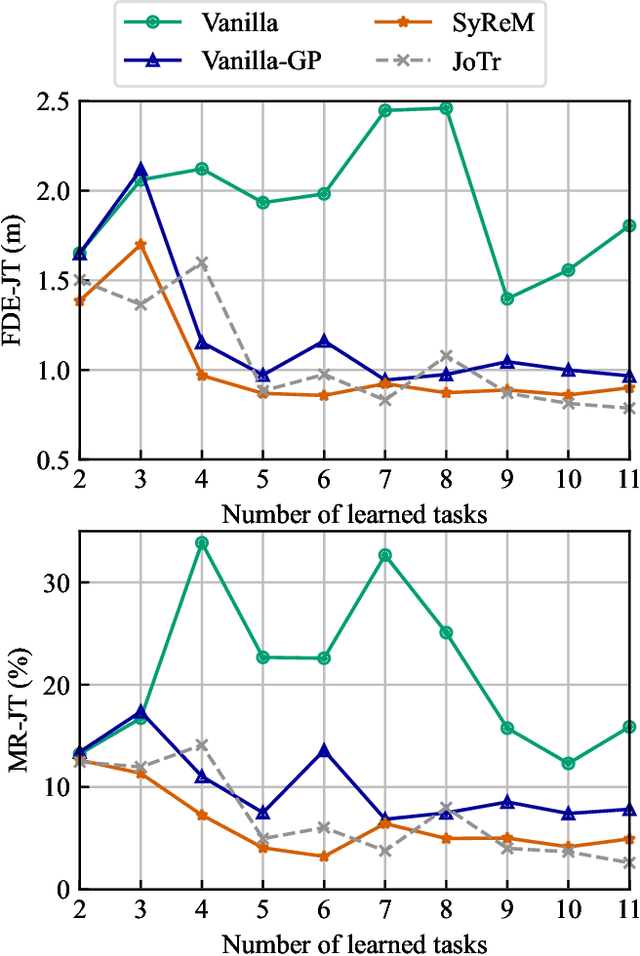
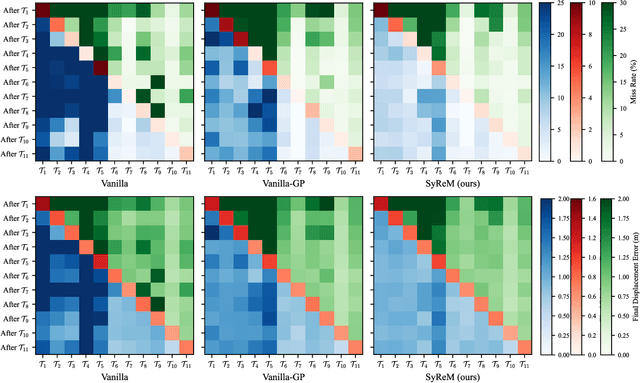
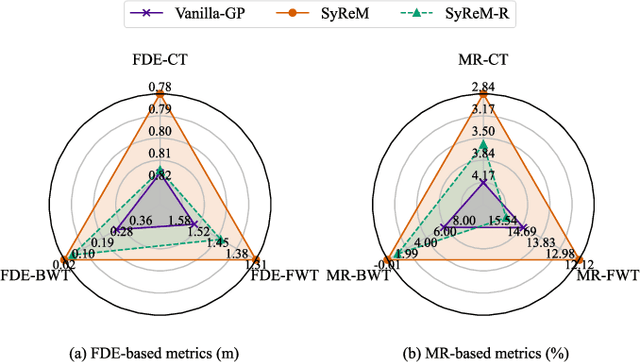
Deep neural networks (DNN) have achieved remarkable success in motion forecasting. However, most DNN-based methods suffer from catastrophic forgetting and fail to maintain their performance in previously learned scenarios after adapting to new data. Recent continual learning (CL) studies aim to mitigate this phenomenon by enhancing memory stability of DNN, i.e., the ability to retain learned knowledge. Yet, excessive emphasis on the memory stability often impairs learning plasticity, i.e., the capacity of DNN to acquire new information effectively. To address such stability-plasticity dilemma, this study proposes a novel CL method, synergetic memory rehearsal (SyReM), for DNN-based motion forecasting. SyReM maintains a compact memory buffer to represent learned knowledge. To ensure memory stability, it employs an inequality constraint that limits increments in the average loss over the memory buffer. Synergistically, a selective memory rehearsal mechanism is designed to enhance learning plasticity by selecting samples from the memory buffer that are most similar to recently observed data. This selection is based on an online-measured cosine similarity of loss gradients, ensuring targeted memory rehearsal. Since replayed samples originate from learned scenarios, this memory rehearsal mechanism avoids compromising memory stability. We validate SyReM under an online CL paradigm where training samples from diverse scenarios arrive as a one-pass stream. Experiments on 11 naturalistic driving datasets from INTERACTION demonstrate that, compared to non-CL and CL baselines, SyReM significantly mitigates catastrophic forgetting in past scenarios while improving forecasting accuracy in new ones. The implementation is publicly available at https://github.com/BIT-Jack/SyReM.
Complementary Learning System Empowers Online Continual Learning of Vehicle Motion Forecasting in Smart Cities
Aug 27, 2025



Artificial intelligence underpins most smart city services, yet deep neural network (DNN) that forecasts vehicle motion still struggle with catastrophic forgetting, the loss of earlier knowledge when models are updated. Conventional fixes enlarge the training set or replay past data, but these strategies incur high data collection costs, sample inefficiently and fail to balance long- and short-term experience, leaving them short of human-like continual learning. Here we introduce Dual-LS, a task-free, online continual learning paradigm for DNN-based motion forecasting that is inspired by the complementary learning system of the human brain. Dual-LS pairs two synergistic memory rehearsal replay mechanisms to accelerate experience retrieval while dynamically coordinating long-term and short-term knowledge representations. Tests on naturalistic data spanning three countries, over 772,000 vehicles and cumulative testing mileage of 11,187 km show that Dual-LS mitigates catastrophic forgetting by up to 74.31\% and reduces computational resource demand by up to 94.02\%, markedly boosting predictive stability in vehicle motion forecasting without inflating data requirements. Meanwhile, it endows DNN-based vehicle motion forecasting with computation efficient and human-like continual learning adaptability fit for smart cities.
Neural Parameter Search for Slimmer Fine-Tuned Models and Better Transfer
May 24, 2025Foundation models and their checkpoints have significantly advanced deep learning, boosting performance across various applications. However, fine-tuned models often struggle outside their specific domains and exhibit considerable redundancy. Recent studies suggest that combining a pruned fine-tuned model with the original pre-trained model can mitigate forgetting, reduce interference when merging model parameters across tasks, and improve compression efficiency. In this context, developing an effective pruning strategy for fine-tuned models is crucial. Leveraging the advantages of the task vector mechanism, we preprocess fine-tuned models by calculating the differences between them and the original model. Recognizing that different task vector subspaces contribute variably to model performance, we introduce a novel method called Neural Parameter Search (NPS-Pruning) for slimming down fine-tuned models. This method enhances pruning efficiency by searching through neural parameters of task vectors within low-rank subspaces. Our method has three key applications: enhancing knowledge transfer through pairwise model interpolation, facilitating effective knowledge fusion via model merging, and enabling the deployment of compressed models that retain near-original performance while significantly reducing storage costs. Extensive experiments across vision, NLP, and multi-modal benchmarks demonstrate the effectiveness and robustness of our approach, resulting in substantial performance gains. The code is publicly available at: https://github.com/duguodong7/NPS-Pruning.
Knowledge Grafting of Large Language Models
May 24, 2025Cross-capability transfer is a key challenge in large language model (LLM) research, with applications in multi-task integration, model compression, and continual learning. Recent works like FuseLLM and FuseChat have demonstrated the potential of transferring multiple model capabilities to lightweight models, enhancing adaptability and efficiency, which motivates our investigation into more efficient cross-capability transfer methods. However, existing approaches primarily focus on small, homogeneous models, limiting their applicability. For large, heterogeneous models, knowledge distillation with full-parameter fine-tuning often overlooks the student model's intrinsic capacity and risks catastrophic forgetting, while PEFT methods struggle to effectively absorb knowledge from source LLMs. To address these issues, we introduce GraftLLM, a novel method that stores source model capabilities in a target model with SkillPack format. This approach preserves general capabilities, reduces parameter conflicts, and supports forget-free continual learning and model fusion. We employ a module-aware adaptive compression strategy to compress parameter updates, ensuring efficient storage while maintaining task-specific knowledge. The resulting SkillPack serves as a compact and transferable knowledge carrier, ideal for heterogeneous model fusion and continual learning. Experiments across various scenarios demonstrate that GraftLLM outperforms existing techniques in knowledge transfer, knowledge fusion, and forget-free learning, providing a scalable and efficient solution for cross-capability transfer. The code is publicly available at: https://github.com/duguodong7/GraftLLM.
Parameter Competition Balancing for Model Merging
Oct 03, 2024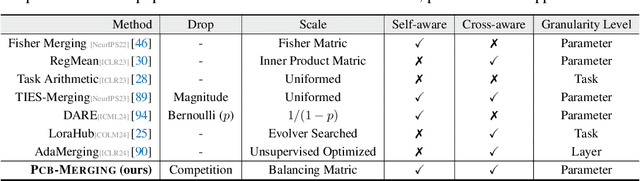
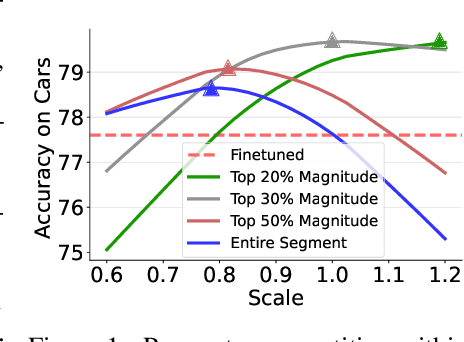
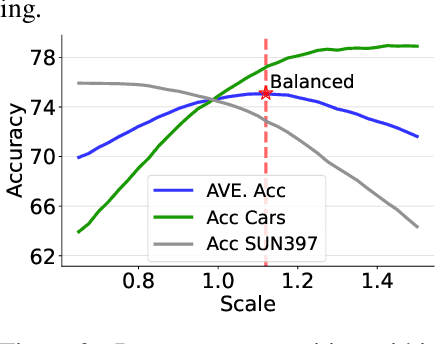
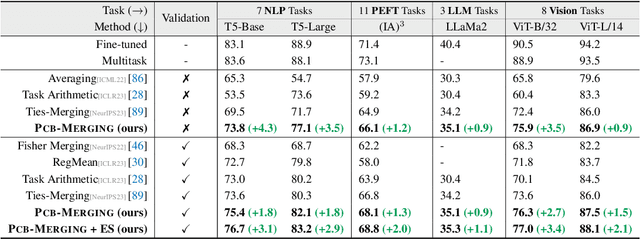
While fine-tuning pretrained models has become common practice, these models often underperform outside their specific domains. Recently developed model merging techniques enable the direct integration of multiple models, each fine-tuned for distinct tasks, into a single model. This strategy promotes multitasking capabilities without requiring retraining on the original datasets. However, existing methods fall short in addressing potential conflicts and complex correlations between tasks, especially in parameter-level adjustments, posing a challenge in effectively balancing parameter competition across various tasks. This paper introduces an innovative technique named PCB-Merging (Parameter Competition Balancing), a lightweight and training-free technique that adjusts the coefficients of each parameter for effective model merging. PCB-Merging employs intra-balancing to gauge parameter significance within individual tasks and inter-balancing to assess parameter similarities across different tasks. Parameters with low importance scores are dropped, and the remaining ones are rescaled to form the final merged model. We assessed our approach in diverse merging scenarios, including cross-task, cross-domain, and cross-training configurations, as well as out-of-domain generalization. The experimental results reveal that our approach achieves substantial performance enhancements across multiple modalities, domains, model sizes, number of tasks, fine-tuning forms, and large language models, outperforming existing model merging methods. The code is publicly available at: \url{https://github.com/duguodong7/pcb-merging}.
Impacts of Darwinian Evolution on Pre-trained Deep Neural Networks
Aug 10, 2024



Darwinian evolution of the biological brain is documented through multiple lines of evidence, although the modes of evolutionary changes remain unclear. Drawing inspiration from the evolved neural systems (e.g., visual cortex), deep learning models have demonstrated superior performance in visual tasks, among others. While the success of training deep neural networks has been relying on back-propagation (BP) and its variants to learn representations from data, BP does not incorporate the evolutionary processes that govern biological neural systems. This work proposes a neural network optimization framework based on evolutionary theory. Specifically, BP-trained deep neural networks for visual recognition tasks obtained from the ending epochs are considered the primordial ancestors (initial population). Subsequently, the population evolved with differential evolution. Extensive experiments are carried out to examine the relationships between Darwinian evolution and neural network optimization, including the correspondence between datasets, environment, models, and living species. The empirical results show that the proposed framework has positive impacts on the network, with reduced over-fitting and an order of magnitude lower time complexity compared to BP. Moreover, the experiments show that the proposed framework performs well on deep neural networks and big datasets.
Knowledge Fusion By Evolving Weights of Language Models
Jun 18, 2024



Fine-tuning pre-trained language models, particularly large language models, demands extensive computing resources and can result in varying performance outcomes across different domains and datasets. This paper examines the approach of integrating multiple models from diverse training scenarios into a unified model. This unified model excels across various data domains and exhibits the ability to generalize well on out-of-domain data. We propose a knowledge fusion method named Evolver, inspired by evolutionary algorithms, which does not need further training or additional training data. Specifically, our method involves aggregating the weights of different language models into a population and subsequently generating offspring models through mutation and crossover operations. These offspring models are then evaluated against their parents, allowing for the preservation of those models that show enhanced performance on development datasets. Importantly, our model evolving strategy can be seamlessly integrated with existing model merging frameworks, offering a versatile tool for model enhancement. Experimental results on mainstream language models (i.e., encoder-only, decoder-only, encoder-decoder) reveal that Evolver outperforms previous state-of-the-art models by large margins. The code is publicly available at {https://github.com/duguodong7/model-evolution}.
CADE: Cosine Annealing Differential Evolution for Spiking Neural Network
Jun 04, 2024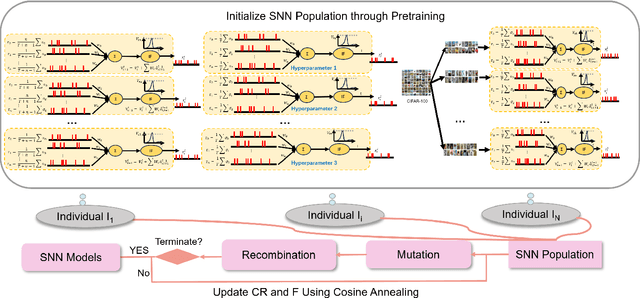



Spiking neural networks (SNNs) have gained prominence for their potential in neuromorphic computing and energy-efficient artificial intelligence, yet optimizing them remains a formidable challenge for gradient-based methods due to their discrete, spike-based computation. This paper attempts to tackle the challenges by introducing Cosine Annealing Differential Evolution (CADE), designed to modulate the mutation factor (F) and crossover rate (CR) of differential evolution (DE) for the SNN model, i.e., Spiking Element Wise (SEW) ResNet. Extensive empirical evaluations were conducted to analyze CADE. CADE showed a balance in exploring and exploiting the search space, resulting in accelerated convergence and improved accuracy compared to existing gradient-based and DE-based methods. Moreover, an initialization method based on a transfer learning setting was developed, pretraining on a source dataset (i.e., CIFAR-10) and fine-tuning the target dataset (i.e., CIFAR-100), to improve population diversity. It was found to further enhance CADE for SNN. Remarkably, CADE elevates the performance of the highest accuracy SEW model by an additional 0.52 percentage points, underscoring its effectiveness in fine-tuning and enhancing SNNs. These findings emphasize the pivotal role of a scheduler for F and CR adjustment, especially for DE-based SNN. Source Code on Github: https://github.com/Tank-Jiang/CADE4SNN.