 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLean Learning Beyond Clouds: Efficient Discrepancy-Conditioned Optical-SAR Fusion for Semantic Segmentation
Mar 21, 2026Cloud occlusion severely degrades the semantic integrity of optical remote sensing imagery. While incorporating Synthetic Aperture Radar (SAR) provides complementary observations, achieving efficient global modeling and reliable cross-modal fusion under cloud interference remains challenging. Existing methods rely on dense global attention to capture long-range dependencies, yet such aggregation indiscriminately propagates cloud-induced noise. Improving robustness typically entails enlarging model capacity, which further increases computational overhead. Given the large-scale and high-resolution nature of remote sensing applications, such computational demands hinder practical deployment, leading to an efficiency-reliability trade-off. To address this dilemma, we propose EDC, an efficiency-oriented and discrepancy-conditioned optical-SAR semantic segmentation framework. A tri-stream encoder with Carrier Tokens enables compact global context modeling with reduced complexity. To prevent noise contamination, we introduce a Discrepancy-Conditioned Hybrid Fusion (DCHF) mechanism that selectively suppresses unreliable regions during global aggregation. In addition, an auxiliary cloud removal branch with teacher-guided distillation enhances semantic consistency under occlusion. Extensive experiments demonstrate that EDC achieves superior accuracy and efficiency, improving mIoU by 0.56\% and 0.88\% on M3M-CR and WHU-OPT-SAR, respectively, while reducing the number of parameters by 46.7\% and accelerating inference by 1.98$\times$. Our implementation is available at https://github.com/mengcx0209/EDC.
M2IR: Proactive All-in-One Image Restoration via Mamba-style Modulation and Mixture-of-Experts
Mar 16, 2026While Transformer-based architectures have dominated recent advances in all-in-one image restoration, they remain fundamentally reactive: propagating degradations rather than proactively suppressing them. In the absence of explicit suppression mechanisms, degraded signals interfere with feature learning, compelling the decoder to balance artifact removal and detail preservation, thereby increasing model complexity and limiting adaptability. To address these challenges, we propose M2IR, a novel restoration framework that proactively regulates degradation propagation during the encoding stage and efficiently eliminates residual degradations during decoding. Specifically, the Mamba-Style Transformer (MST) block performs pixel-wise selective state modulation to mitigate degradations while preserving structural integrity. In parallel, the Adaptive Degradation Expert Collaboration (ADEC) module utilizes degradation-specific experts guided by a DA-CLIP-driven router and complemented by a shared expert to eliminate residual degradations through targeted and cooperative restoration. By integrating the MST block and ADEC module, M2IR transitions from passive reaction to active degradation control, effectively harnessing learned representations to achieve superior generalization, enhanced adaptability, and refined recovery of fine-grained details across diverse all-in-one image restoration benchmarks. Our source codes are available at https://github.com/Im34v/M2IR.
Diverse Semantics-Guided Feature Alignment and Decoupling for Visible-Infrared Person Re-Identification
May 01, 2025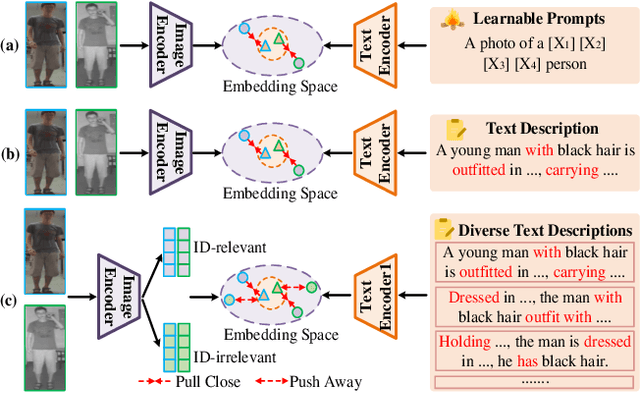
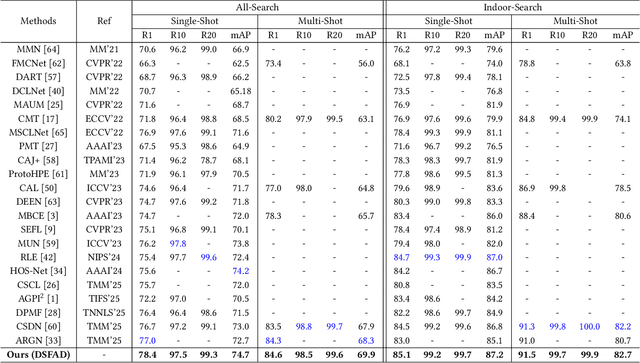
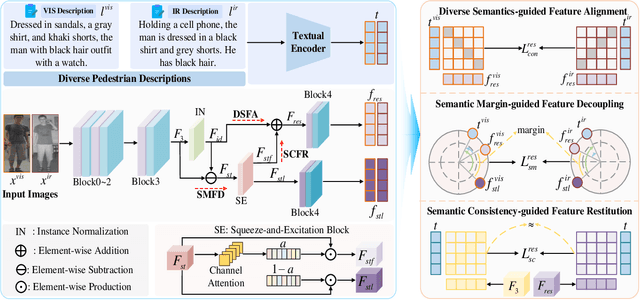
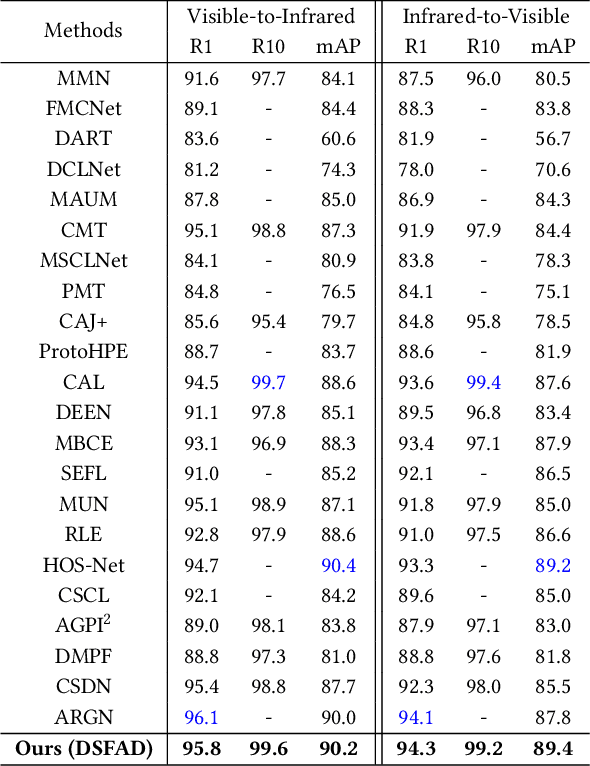
Visible-Infrared Person Re-Identification (VI-ReID) is a challenging task due to the large modality discrepancy between visible and infrared images, which complicates the alignment of their features into a suitable common space. Moreover, style noise, such as illumination and color contrast, reduces the identity discriminability and modality invariance of features. To address these challenges, we propose a novel Diverse Semantics-guided Feature Alignment and Decoupling (DSFAD) network to align identity-relevant features from different modalities into a textual embedding space and disentangle identity-irrelevant features within each modality. Specifically, we develop a Diverse Semantics-guided Feature Alignment (DSFA) module, which generates pedestrian descriptions with diverse sentence structures to guide the cross-modality alignment of visual features. Furthermore, to filter out style information, we propose a Semantic Margin-guided Feature Decoupling (SMFD) module, which decomposes visual features into pedestrian-related and style-related components, and then constrains the similarity between the former and the textual embeddings to be at least a margin higher than that between the latter and the textual embeddings. Additionally, to prevent the loss of pedestrian semantics during feature decoupling, we design a Semantic Consistency-guided Feature Restitution (SCFR) module, which further excavates useful information for identification from the style-related features and restores it back into the pedestrian-related features, and then constrains the similarity between the features after restitution and the textual embeddings to be consistent with that between the features before decoupling and the textual embeddings. Extensive experiments on three VI-ReID datasets demonstrate the superiority of our DSFAD.
Embedding and Enriching Explicit Semantics for Visible-Infrared Person Re-Identification
Dec 11, 2024Visible-infrared person re-identification (VIReID) retrieves pedestrian images with the same identity across different modalities. Existing methods learn visual content solely from images, lacking the capability to sense high-level semantics. In this paper, we propose an Embedding and Enriching Explicit Semantics (EEES) framework to learn semantically rich cross-modality pedestrian representations. Our method offers several contributions. First, with the collaboration of multiple large language-vision models, we develop Explicit Semantics Embedding (ESE), which automatically supplements language descriptions for pedestrians and aligns image-text pairs into a common space, thereby learning visual content associated with explicit semantics. Second, recognizing the complementarity of multi-view information, we present Cross-View Semantics Compensation (CVSC), which constructs multi-view image-text pair representations, establishes their many-to-many matching, and propagates knowledge to single-view representations, thus compensating visual content with its missing cross-view semantics. Third, to eliminate noisy semantics such as conflicting color attributes in different modalities, we design Cross-Modality Semantics Purification (CMSP), which constrains the distance between inter-modality image-text pair representations to be close to that between intra-modality image-text pair representations, further enhancing the modality-invariance of visual content. Finally, experimental results demonstrate the effectiveness and superiority of the proposed EEES.
Discriminative Pedestrian Features and Gated Channel Attention for Clothes-Changing Person Re-Identification
Oct 29, 2024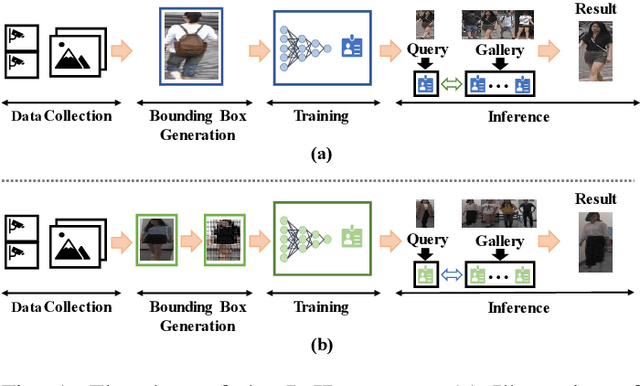
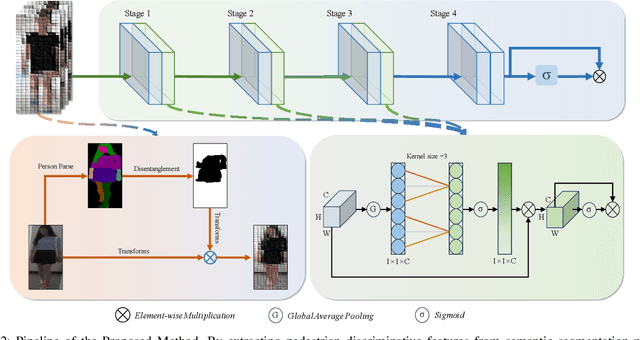
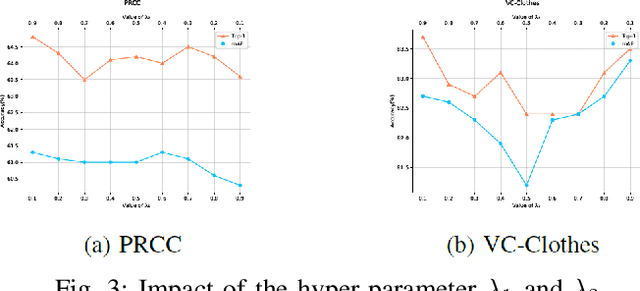
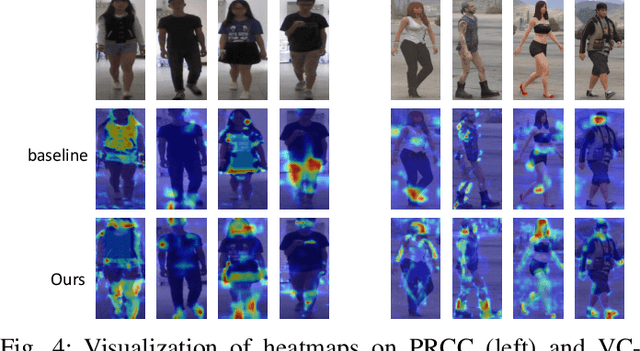
In public safety and social life, the task of Clothes-Changing Person Re-Identification (CC-ReID) has become increasingly significant. However, this task faces considerable challenges due to appearance changes caused by clothing alterations. Addressing this issue, this paper proposes an innovative method for disentangled feature extraction, effectively extracting discriminative features from pedestrian images that are invariant to clothing. This method leverages pedestrian parsing techniques to identify and retain features closely associated with individual identity while disregarding the variable nature of clothing attributes. Furthermore, this study introduces a gated channel attention mechanism, which, by adjusting the network's focus, aids the model in more effectively learning and emphasizing features critical for pedestrian identity recognition. Extensive experiments conducted on two standard CC-ReID datasets validate the effectiveness of the proposed approach, with performance surpassing current leading solutions. The Top-1 accuracy under clothing change scenarios on the PRCC and VC-Clothes datasets reached 64.8% and 83.7%, respectively.
Multi-view Information Integration and Propagation for Occluded Person Re-identification
Nov 09, 2023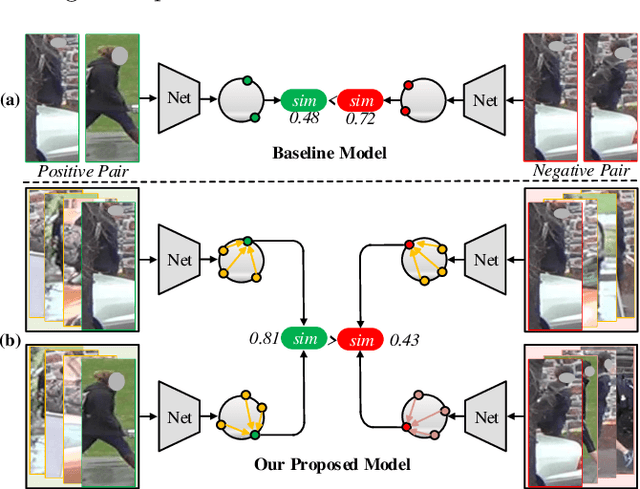
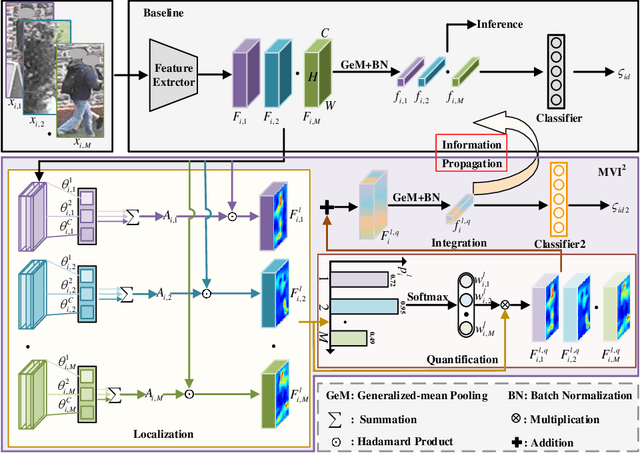
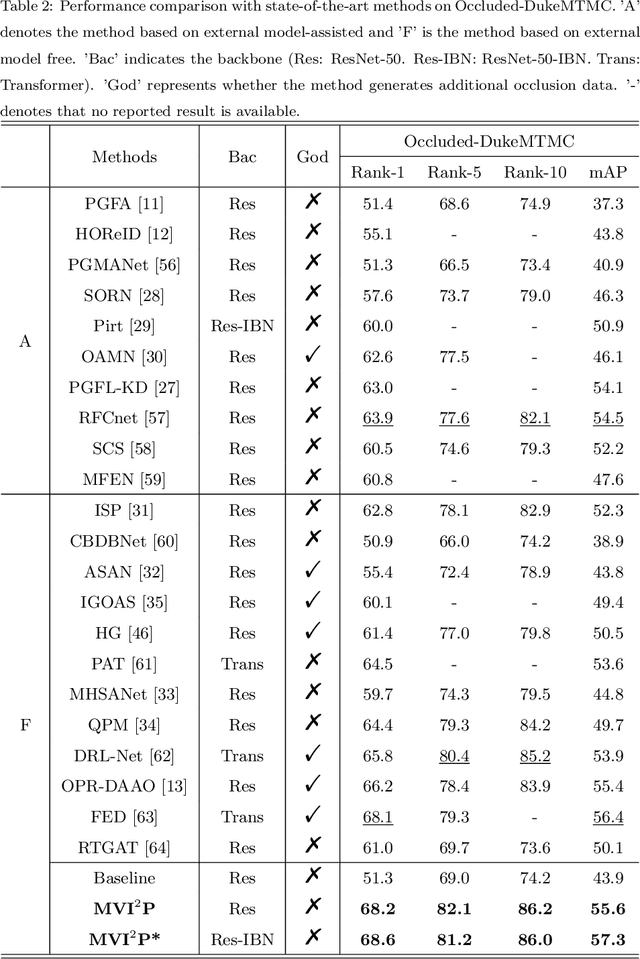
Occluded person re-identification (re-ID) presents a challenging task due to occlusion perturbations. Although great efforts have been made to prevent the model from being disturbed by occlusion noise, most current solutions only capture information from a single image, disregarding the rich complementary information available in multiple images depicting the same pedestrian. In this paper, we propose a novel framework called Multi-view Information Integration and Propagation (MVI$^{2}$P). Specifically, realizing the potential of multi-view images in effectively characterizing the occluded target pedestrian, we integrate feature maps of which to create a comprehensive representation. During this process, to avoid introducing occlusion noise, we develop a CAMs-aware Localization module that selectively integrates information contributing to the identification. Additionally, considering the divergence in the discriminative nature of different images, we design a probability-aware Quantification module to emphatically integrate highly reliable information. Moreover, as multiple images with the same identity are not accessible in the testing stage, we devise an Information Propagation (IP) mechanism to distill knowledge from the comprehensive representation to that of a single occluded image. Extensive experiments and analyses have unequivocally demonstrated the effectiveness and superiority of the proposed MVI$^{2}$P. The code will be released at \url{https://github.com/nengdong96/MVIIP}.
Learning Comprehensive Representations with Richer Self for Text-to-Image Person Re-Identification
Oct 17, 2023



Text-to-image person re-identification (TIReID) retrieves pedestrian images of the same identity based on a query text. However, existing methods for TIReID typically treat it as a one-to-one image-text matching problem, only focusing on the relationship between image-text pairs within a view. The many-to-many matching between image-text pairs across views under the same identity is not taken into account, which is one of the main reasons for the poor performance of existing methods. To this end, we propose a simple yet effective framework, called LCR$^2$S, for modeling many-to-many correspondences of the same identity by learning comprehensive representations for both modalities from a novel perspective. We construct a support set for each image (text) by using other images (texts) under the same identity and design a multi-head attentional fusion module to fuse the image (text) and its support set. The resulting enriched image and text features fuse information from multiple views, which are aligned to train a "richer" TIReID model with many-to-many correspondences. Since the support set is unavailable during inference, we propose to distill the knowledge learned by the "richer" model into a lightweight model for inference with a single image/text as input. The lightweight model focuses on semantic association and reasoning of multi-view information, which can generate a comprehensive representation containing multi-view information with only a single-view input to perform accurate text-to-image retrieval during inference. In particular, we use the intra-modal features and inter-modal semantic relations of the "richer" model to supervise the lightweight model to inherit its powerful capability. Extensive experiments demonstrate the effectiveness of LCR$^2$S, and it also achieves new state-of-the-art performance on three popular TIReID datasets.
Prototype-guided Cross-modal Completion and Alignment for Incomplete Text-based Person Re-identification
Oct 03, 2023
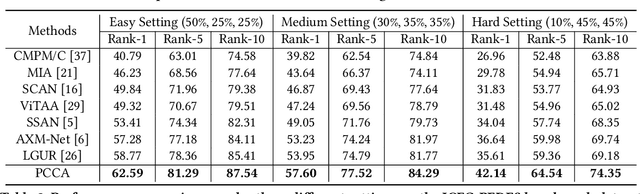

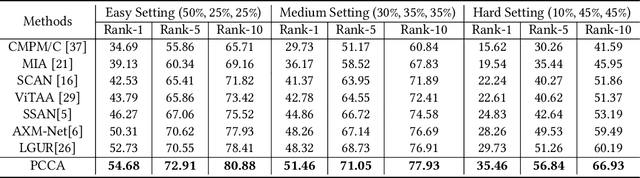
Traditional text-based person re-identification (ReID) techniques heavily rely on fully matched multi-modal data, which is an ideal scenario. However, due to inevitable data missing and corruption during the collection and processing of cross-modal data, the incomplete data issue is usually met in real-world applications. Therefore, we consider a more practical task termed the incomplete text-based ReID task, where person images and text descriptions are not completely matched and contain partially missing modality data. To this end, we propose a novel Prototype-guided Cross-modal Completion and Alignment (PCCA) framework to handle the aforementioned issues for incomplete text-based ReID. Specifically, we cannot directly retrieve person images based on a text query on missing modality data. Therefore, we propose the cross-modal nearest neighbor construction strategy for missing data by computing the cross-modal similarity between existing images and texts, which provides key guidance for the completion of missing modal features. Furthermore, to efficiently complete the missing modal features, we construct the relation graphs with the aforementioned cross-modal nearest neighbor sets of missing modal data and the corresponding prototypes, which can further enhance the generated missing modal features. Additionally, for tighter fine-grained alignment between images and texts, we raise a prototype-aware cross-modal alignment loss that can effectively reduce the modality heterogeneity gap for better fine-grained alignment in common space. Extensive experimental results on several benchmarks with different missing ratios amply demonstrate that our method can consistently outperform state-of-the-art text-image ReID approaches.
* Sorry, some collaborators do not agree to publish it on Arxiv, so please withdraw this paper
Erasing, Transforming, and Noising Defense Network for Occluded Person Re-Identification
Jul 14, 2023Occlusion perturbation presents a significant challenge in person re-identification (re-ID), and existing methods that rely on external visual cues require additional computational resources and only consider the issue of missing information caused by occlusion. In this paper, we propose a simple yet effective framework, termed Erasing, Transforming, and Noising Defense Network (ETNDNet), which treats occlusion as a noise disturbance and solves occluded person re-ID from the perspective of adversarial defense. In the proposed ETNDNet, we introduce three strategies: Firstly, we randomly erase the feature map to create an adversarial representation with incomplete information, enabling adversarial learning of identity loss to protect the re-ID system from the disturbance of missing information. Secondly, we introduce random transformations to simulate the position misalignment caused by occlusion, training the extractor and classifier adversarially to learn robust representations immune to misaligned information. Thirdly, we perturb the feature map with random values to address noisy information introduced by obstacles and non-target pedestrians, and employ adversarial gaming in the re-ID system to enhance its resistance to occlusion noise. Without bells and whistles, ETNDNet has three key highlights: (i) it does not require any external modules with parameters, (ii) it effectively handles various issues caused by occlusion from obstacles and non-target pedestrians, and (iii) it designs the first GAN-based adversarial defense paradigm for occluded person re-ID. Extensive experiments on five public datasets fully demonstrate the effectiveness, superiority, and practicality of the proposed ETNDNet. The code will be released at \url{https://github.com/nengdong96/ETNDNet}.
Coupling Global Context and Local Contents for Weakly-Supervised Semantic Segmentation
Apr 26, 2023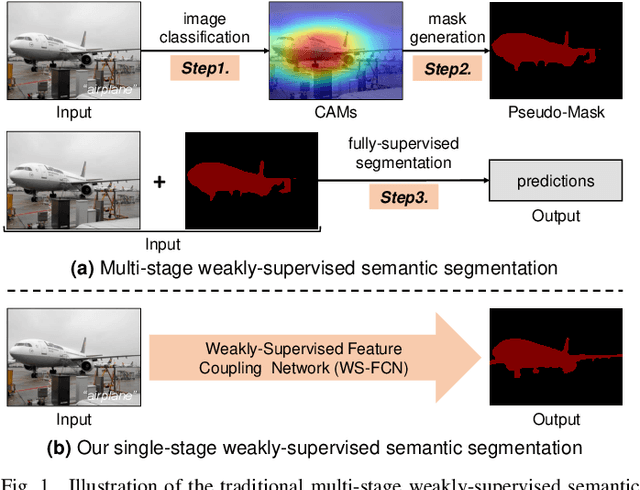

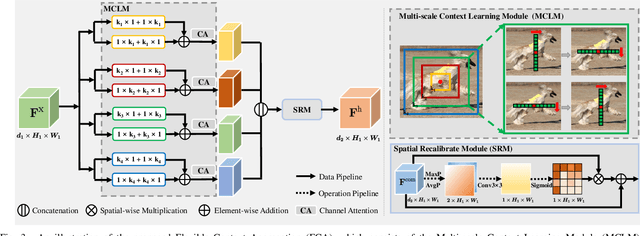
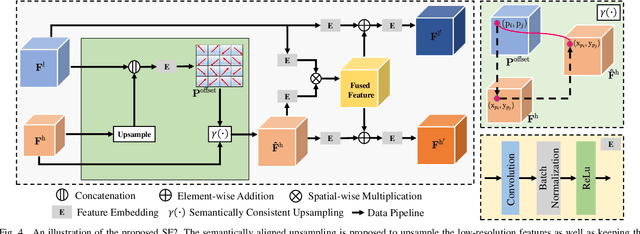
Thanks to the advantages of the friendly annotations and the satisfactory performance, Weakly-Supervised Semantic Segmentation (WSSS) approaches have been extensively studied. Recently, the single-stage WSSS was awakened to alleviate problems of the expensive computational costs and the complicated training procedures in multi-stage WSSS. However, results of such an immature model suffer from problems of background incompleteness and object incompleteness. We empirically find that they are caused by the insufficiency of the global object context and the lack of the local regional contents, respectively. Under these observations, we propose a single-stage WSSS model with only the image-level class label supervisions, termed as Weakly Supervised Feature Coupling Network (WS-FCN), which can capture the multi-scale context formed from the adjacent feature grids, and encode the fine-grained spatial information from the low-level features into the high-level ones. Specifically, a flexible context aggregation module is proposed to capture the global object context in different granular spaces. Besides, a semantically consistent feature fusion module is proposed in a bottom-up parameter-learnable fashion to aggregate the fine-grained local contents. Based on these two modules, WS-FCN lies in a self-supervised end-to-end training fashion. Extensive experimental results on the challenging PASCAL VOC 2012 and MS COCO 2014 demonstrate the effectiveness and efficiency of WS-FCN, which can achieve state-of-the-art results by 65.02\% and 64.22\% mIoU on PASCAL VOC 2012 val set and test set, 34.12\% mIoU on MS COCO 2014 val set, respectively. The code and weight have been released at:https://github.com/ChunyanWang1/ws-fcn.