 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Proxy Evolving for OOD Detection with Vision-Language Models
Jan 13, 2026Reliable zero-shot detection of out-of-distribution (OOD) inputs is critical for deploying vision-language models in open-world settings. However, the lack of labeled negatives in zero-shot OOD detection necessitates proxy signals that remain effective under distribution shift. Existing negative-label methods rely on a fixed set of textual proxies, which (i) sparsely sample the semantic space beyond in-distribution (ID) classes and (ii) remain static while only visual features drift, leading to cross-modal misalignment and unstable predictions. In this paper, we propose CoEvo, a training- and annotation-free test-time framework that performs bidirectional, sample-conditioned adaptation of both textual and visual proxies. Specifically, CoEvo introduces a proxy-aligned co-evolution mechanism to maintain two evolving proxy caches, which dynamically mines contextual textual negatives guided by test images and iteratively refines visual proxies, progressively realigning cross-modal similarities and enlarging local OOD margins. Finally, we dynamically re-weight the contributions of dual-modal proxies to obtain a calibrated OOD score that is robust to distribution shift. Extensive experiments on standard benchmarks demonstrate that CoEvo achieves state-of-the-art performance, improving AUROC by 1.33% and reducing FPR95 by 45.98% on ImageNet-1K compared to strong negative-label baselines.
Diverse Semantics-Guided Feature Alignment and Decoupling for Visible-Infrared Person Re-Identification
May 01, 2025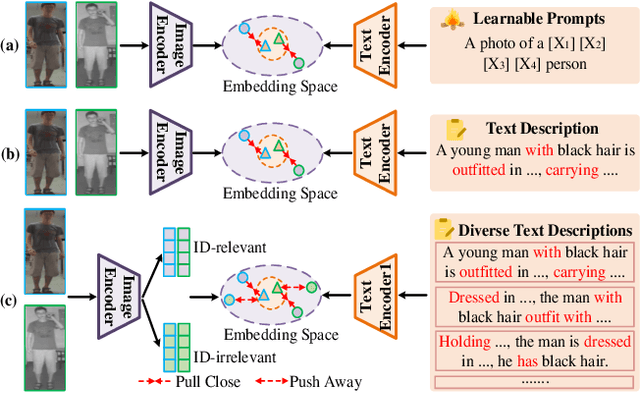
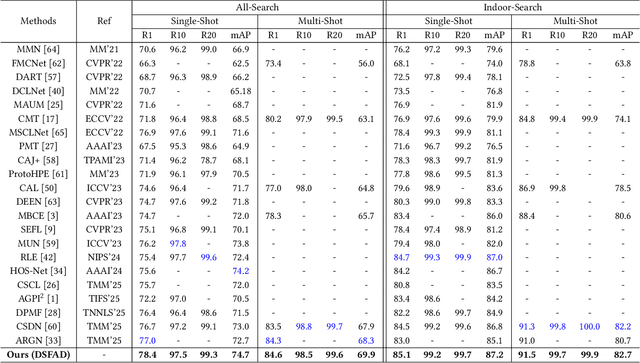
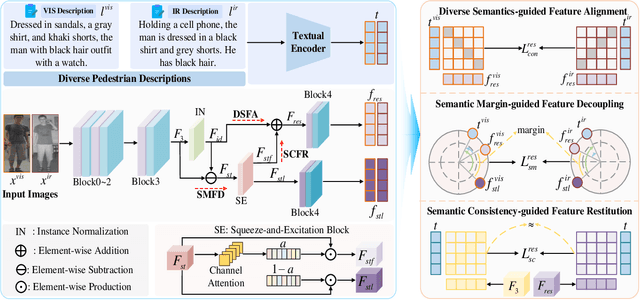
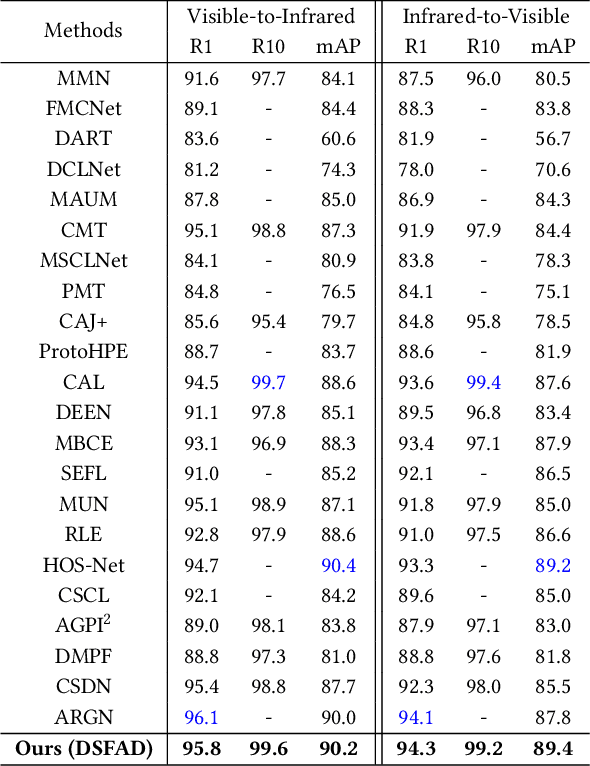
Visible-Infrared Person Re-Identification (VI-ReID) is a challenging task due to the large modality discrepancy between visible and infrared images, which complicates the alignment of their features into a suitable common space. Moreover, style noise, such as illumination and color contrast, reduces the identity discriminability and modality invariance of features. To address these challenges, we propose a novel Diverse Semantics-guided Feature Alignment and Decoupling (DSFAD) network to align identity-relevant features from different modalities into a textual embedding space and disentangle identity-irrelevant features within each modality. Specifically, we develop a Diverse Semantics-guided Feature Alignment (DSFA) module, which generates pedestrian descriptions with diverse sentence structures to guide the cross-modality alignment of visual features. Furthermore, to filter out style information, we propose a Semantic Margin-guided Feature Decoupling (SMFD) module, which decomposes visual features into pedestrian-related and style-related components, and then constrains the similarity between the former and the textual embeddings to be at least a margin higher than that between the latter and the textual embeddings. Additionally, to prevent the loss of pedestrian semantics during feature decoupling, we design a Semantic Consistency-guided Feature Restitution (SCFR) module, which further excavates useful information for identification from the style-related features and restores it back into the pedestrian-related features, and then constrains the similarity between the features after restitution and the textual embeddings to be consistent with that between the features before decoupling and the textual embeddings. Extensive experiments on three VI-ReID datasets demonstrate the superiority of our DSFAD.
ShapeSpeak: Body Shape-Aware Textual Alignment for Visible-Infrared Person Re-Identification
Apr 25, 2025



Visible-Infrared Person Re-identification (VIReID) aims to match visible and infrared pedestrian images, but the modality differences and the complexity of identity features make it challenging. Existing methods rely solely on identity label supervision, which makes it difficult to fully extract high-level semantic information. Recently, vision-language pre-trained models have been introduced to VIReID, enhancing semantic information modeling by generating textual descriptions. However, such methods do not explicitly model body shape features, which are crucial for cross-modal matching. To address this, we propose an effective Body Shape-aware Textual Alignment (BSaTa) framework that explicitly models and utilizes body shape information to improve VIReID performance. Specifically, we design a Body Shape Textual Alignment (BSTA) module that extracts body shape information using a human parsing model and converts it into structured text representations via CLIP. We also design a Text-Visual Consistency Regularizer (TVCR) to ensure alignment between body shape textual representations and visual body shape features. Furthermore, we introduce a Shape-aware Representation Learning (SRL) mechanism that combines Multi-text Supervision and Distribution Consistency Constraints to guide the visual encoder to learn modality-invariant and discriminative identity features, thus enhancing modality invariance. Experimental results demonstrate that our method achieves superior performance on the SYSU-MM01 and RegDB datasets, validating its effectiveness.
Embedding and Enriching Explicit Semantics for Visible-Infrared Person Re-Identification
Dec 11, 2024Visible-infrared person re-identification (VIReID) retrieves pedestrian images with the same identity across different modalities. Existing methods learn visual content solely from images, lacking the capability to sense high-level semantics. In this paper, we propose an Embedding and Enriching Explicit Semantics (EEES) framework to learn semantically rich cross-modality pedestrian representations. Our method offers several contributions. First, with the collaboration of multiple large language-vision models, we develop Explicit Semantics Embedding (ESE), which automatically supplements language descriptions for pedestrians and aligns image-text pairs into a common space, thereby learning visual content associated with explicit semantics. Second, recognizing the complementarity of multi-view information, we present Cross-View Semantics Compensation (CVSC), which constructs multi-view image-text pair representations, establishes their many-to-many matching, and propagates knowledge to single-view representations, thus compensating visual content with its missing cross-view semantics. Third, to eliminate noisy semantics such as conflicting color attributes in different modalities, we design Cross-Modality Semantics Purification (CMSP), which constrains the distance between inter-modality image-text pair representations to be close to that between intra-modality image-text pair representations, further enhancing the modality-invariance of visual content. Finally, experimental results demonstrate the effectiveness and superiority of the proposed EEES.
Multi-view Information Integration and Propagation for Occluded Person Re-identification
Nov 09, 2023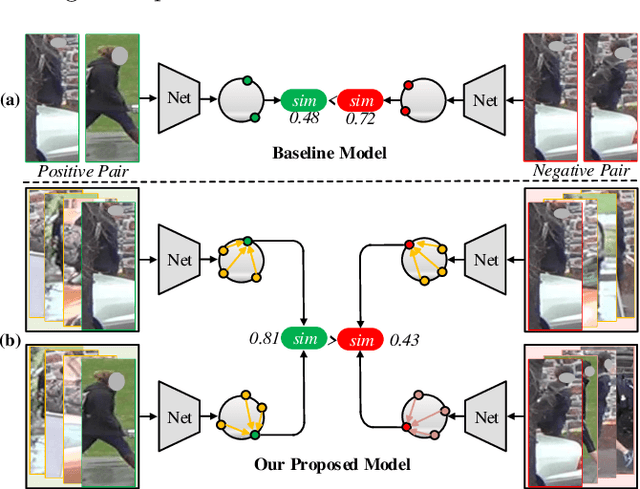
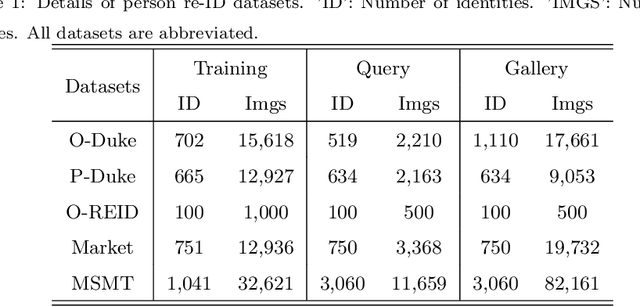
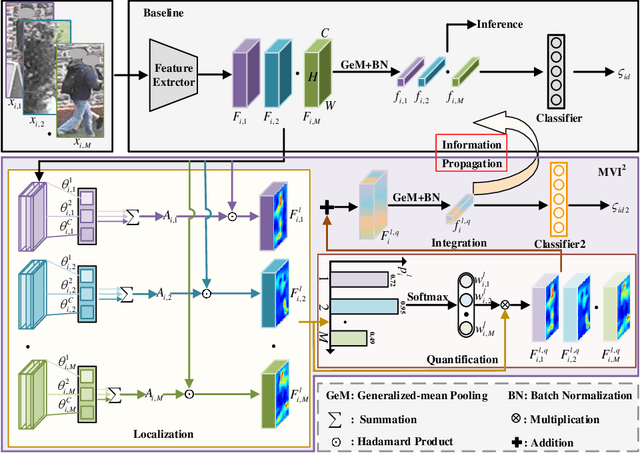
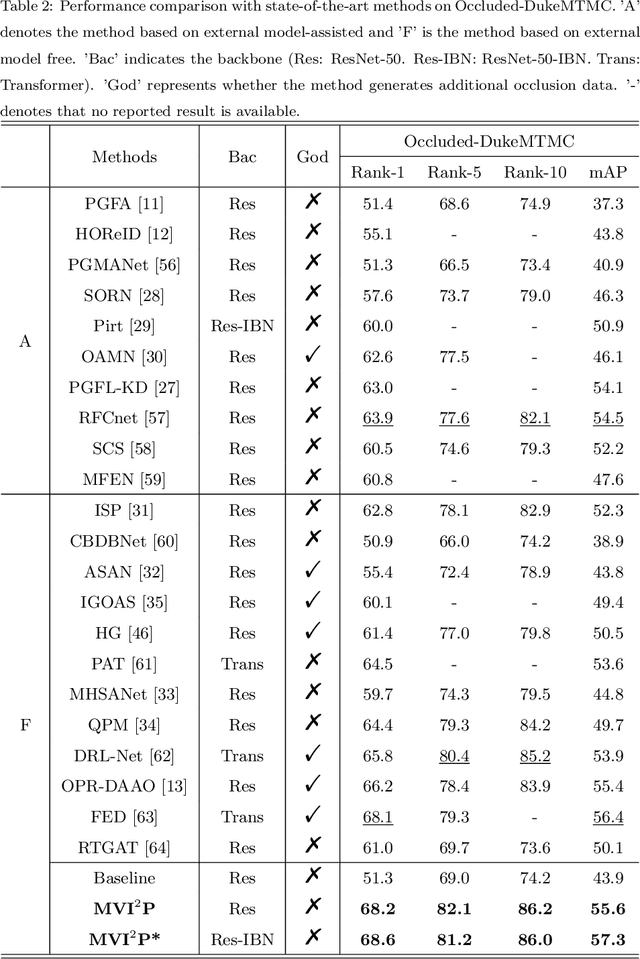
Occluded person re-identification (re-ID) presents a challenging task due to occlusion perturbations. Although great efforts have been made to prevent the model from being disturbed by occlusion noise, most current solutions only capture information from a single image, disregarding the rich complementary information available in multiple images depicting the same pedestrian. In this paper, we propose a novel framework called Multi-view Information Integration and Propagation (MVI$^{2}$P). Specifically, realizing the potential of multi-view images in effectively characterizing the occluded target pedestrian, we integrate feature maps of which to create a comprehensive representation. During this process, to avoid introducing occlusion noise, we develop a CAMs-aware Localization module that selectively integrates information contributing to the identification. Additionally, considering the divergence in the discriminative nature of different images, we design a probability-aware Quantification module to emphatically integrate highly reliable information. Moreover, as multiple images with the same identity are not accessible in the testing stage, we devise an Information Propagation (IP) mechanism to distill knowledge from the comprehensive representation to that of a single occluded image. Extensive experiments and analyses have unequivocally demonstrated the effectiveness and superiority of the proposed MVI$^{2}$P. The code will be released at \url{https://github.com/nengdong96/MVIIP}.
Learning Comprehensive Representations with Richer Self for Text-to-Image Person Re-Identification
Oct 17, 2023



Text-to-image person re-identification (TIReID) retrieves pedestrian images of the same identity based on a query text. However, existing methods for TIReID typically treat it as a one-to-one image-text matching problem, only focusing on the relationship between image-text pairs within a view. The many-to-many matching between image-text pairs across views under the same identity is not taken into account, which is one of the main reasons for the poor performance of existing methods. To this end, we propose a simple yet effective framework, called LCR$^2$S, for modeling many-to-many correspondences of the same identity by learning comprehensive representations for both modalities from a novel perspective. We construct a support set for each image (text) by using other images (texts) under the same identity and design a multi-head attentional fusion module to fuse the image (text) and its support set. The resulting enriched image and text features fuse information from multiple views, which are aligned to train a "richer" TIReID model with many-to-many correspondences. Since the support set is unavailable during inference, we propose to distill the knowledge learned by the "richer" model into a lightweight model for inference with a single image/text as input. The lightweight model focuses on semantic association and reasoning of multi-view information, which can generate a comprehensive representation containing multi-view information with only a single-view input to perform accurate text-to-image retrieval during inference. In particular, we use the intra-modal features and inter-modal semantic relations of the "richer" model to supervise the lightweight model to inherit its powerful capability. Extensive experiments demonstrate the effectiveness of LCR$^2$S, and it also achieves new state-of-the-art performance on three popular TIReID datasets.
M$^3$Net: Multi-view Encoding, Matching, and Fusion for Few-shot Fine-grained Action Recognition
Aug 06, 2023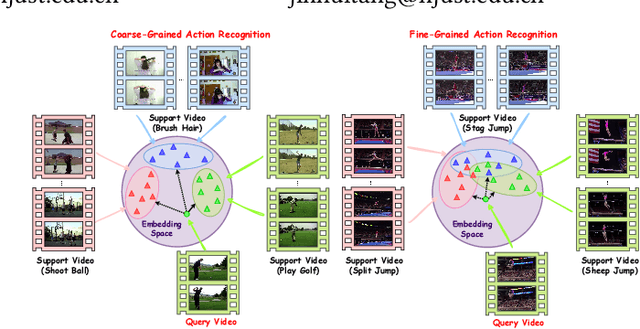

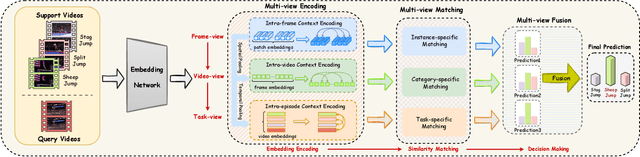

Due to the scarcity of manually annotated data required for fine-grained video understanding, few-shot fine-grained (FS-FG) action recognition has gained significant attention, with the aim of classifying novel fine-grained action categories with only a few labeled instances. Despite the progress made in FS coarse-grained action recognition, current approaches encounter two challenges when dealing with the fine-grained action categories: the inability to capture subtle action details and the insufficiency of learning from limited data that exhibit high intra-class variance and inter-class similarity. To address these limitations, we propose M$^3$Net, a matching-based framework for FS-FG action recognition, which incorporates \textit{multi-view encoding}, \textit{multi-view matching}, and \textit{multi-view fusion} to facilitate embedding encoding, similarity matching, and decision making across multiple viewpoints. \textit{Multi-view encoding} captures rich contextual details from the intra-frame, intra-video, and intra-episode perspectives, generating customized higher-order embeddings for fine-grained data. \textit{Multi-view matching} integrates various matching functions enabling flexible relation modeling within limited samples to handle multi-scale spatio-temporal variations by leveraging the instance-specific, category-specific, and task-specific perspectives. \textit{Multi-view fusion} consists of matching-predictions fusion and matching-losses fusion over the above views, where the former promotes mutual complementarity and the latter enhances embedding generalizability by employing multi-task collaborative learning. Explainable visualizations and experimental results on three challenging benchmarks demonstrate the superiority of M$^3$Net in capturing fine-grained action details and achieving state-of-the-art performance for FS-FG action recognition.
Erasing, Transforming, and Noising Defense Network for Occluded Person Re-Identification
Jul 14, 2023Occlusion perturbation presents a significant challenge in person re-identification (re-ID), and existing methods that rely on external visual cues require additional computational resources and only consider the issue of missing information caused by occlusion. In this paper, we propose a simple yet effective framework, termed Erasing, Transforming, and Noising Defense Network (ETNDNet), which treats occlusion as a noise disturbance and solves occluded person re-ID from the perspective of adversarial defense. In the proposed ETNDNet, we introduce three strategies: Firstly, we randomly erase the feature map to create an adversarial representation with incomplete information, enabling adversarial learning of identity loss to protect the re-ID system from the disturbance of missing information. Secondly, we introduce random transformations to simulate the position misalignment caused by occlusion, training the extractor and classifier adversarially to learn robust representations immune to misaligned information. Thirdly, we perturb the feature map with random values to address noisy information introduced by obstacles and non-target pedestrians, and employ adversarial gaming in the re-ID system to enhance its resistance to occlusion noise. Without bells and whistles, ETNDNet has three key highlights: (i) it does not require any external modules with parameters, (ii) it effectively handles various issues caused by occlusion from obstacles and non-target pedestrians, and (iii) it designs the first GAN-based adversarial defense paradigm for occluded person re-ID. Extensive experiments on five public datasets fully demonstrate the effectiveness, superiority, and practicality of the proposed ETNDNet. The code will be released at \url{https://github.com/nengdong96/ETNDNet}.
CLIP-Driven Fine-grained Text-Image Person Re-identification
Oct 19, 2022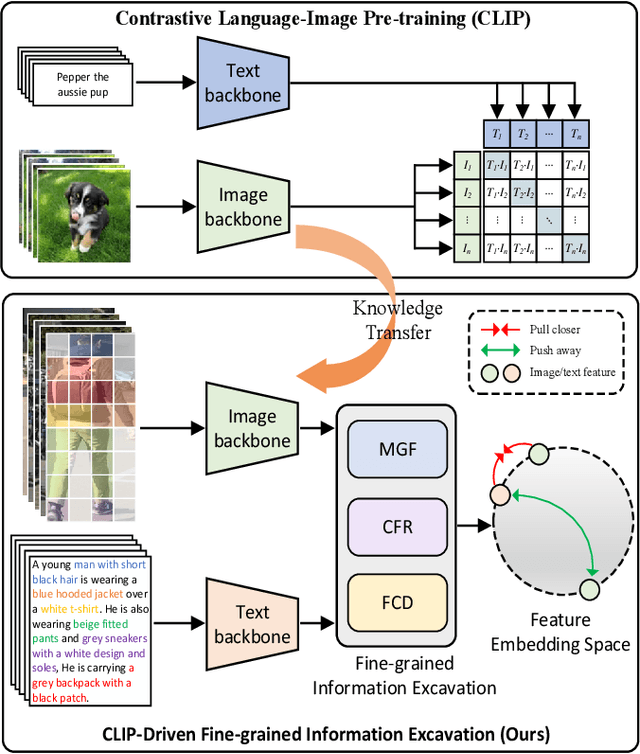
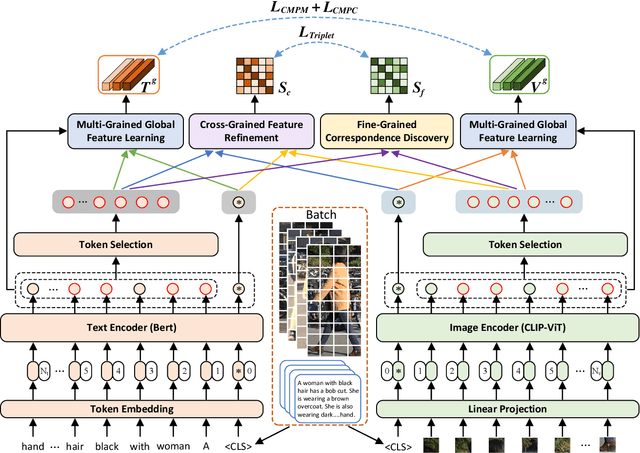
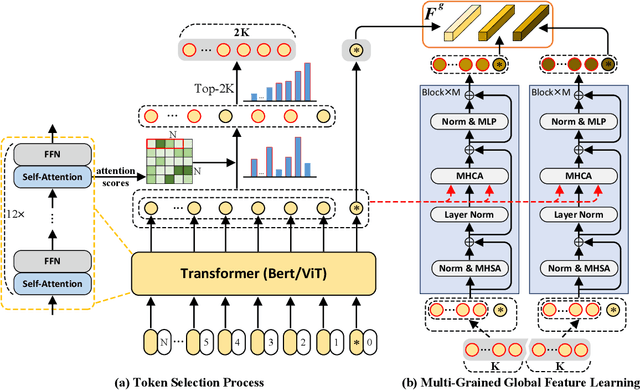
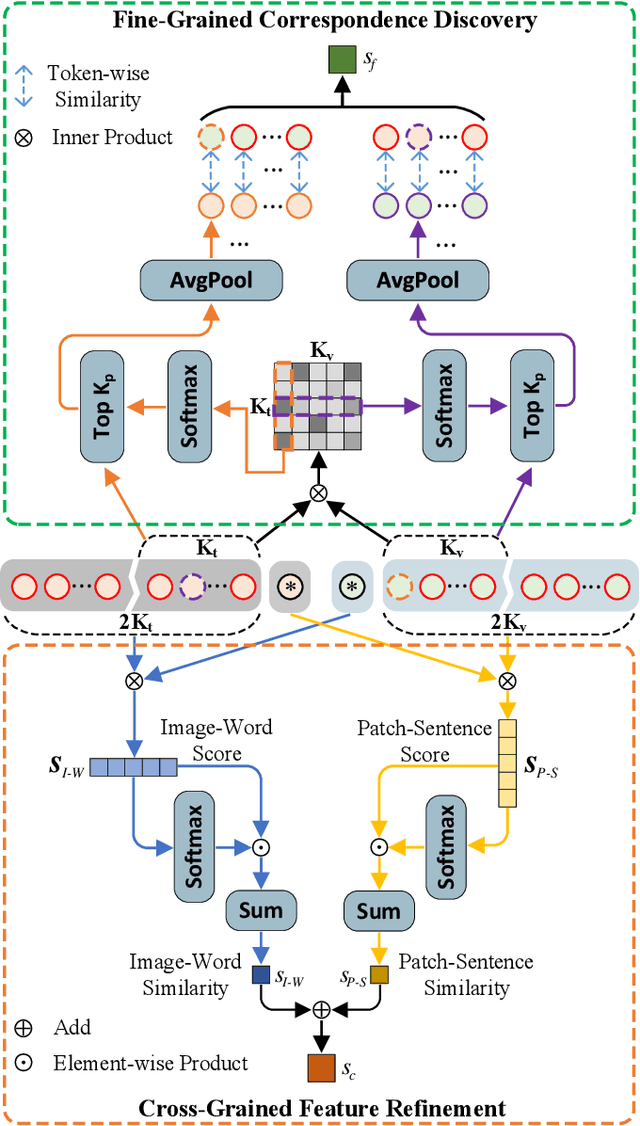
TIReID aims to retrieve the image corresponding to the given text query from a pool of candidate images. Existing methods employ prior knowledge from single-modality pre-training to facilitate learning, but lack multi-modal correspondences. Besides, due to the substantial gap between modalities, existing methods embed the original modal features into the same latent space for cross-modal alignment. However, feature embedding may lead to intra-modal information distortion. Recently, CLIP has attracted extensive attention from researchers due to its powerful semantic concept learning capacity and rich multi-modal knowledge, which can help us solve the above problems. Accordingly, in the paper, we propose a CLIP-driven Fine-grained information excavation framework (CFine) to fully utilize the powerful knowledge of CLIP for TIReID. To transfer the multi-modal knowledge effectively, we perform fine-grained information excavation to mine intra-modal discriminative clues and inter-modal correspondences. Specifically, we first design a multi-grained global feature learning module to fully mine intra-modal discriminative local information, which can emphasize identity-related discriminative clues by enhancing the interactions between global image (text) and informative local patches (words). Secondly, cross-grained feature refinement (CFR) and fine-grained correspondence discovery (FCD) modules are proposed to establish the cross-grained and fine-grained interactions between modalities, which can filter out non-modality-shared image patches/words and mine cross-modal correspondences from coarse to fine. CFR and FCD are removed during inference to save computational costs. Note that the above process is performed in the original modality space without further feature embedding. Extensive experiments on multiple benchmarks demonstrate the superior performance of our method on TIReID.
Image-Specific Information Suppression and Implicit Local Alignment for Text-based Person Search
Aug 30, 2022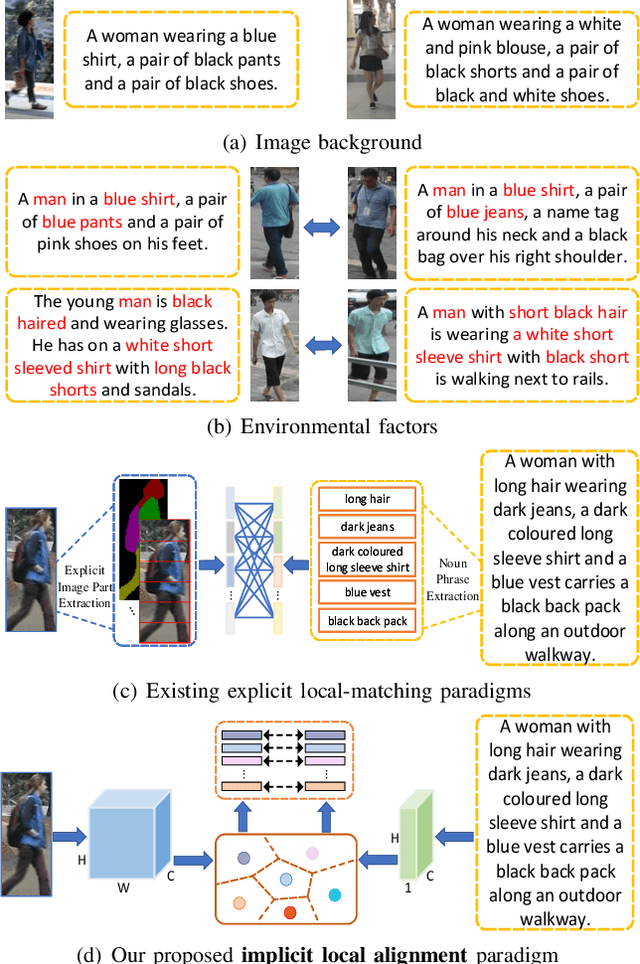
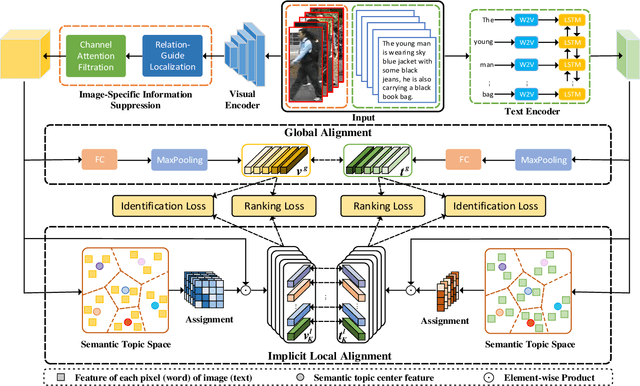
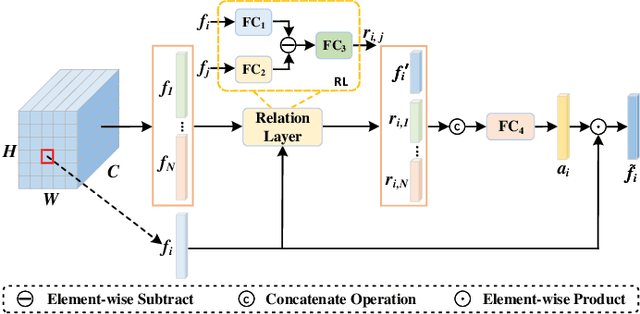
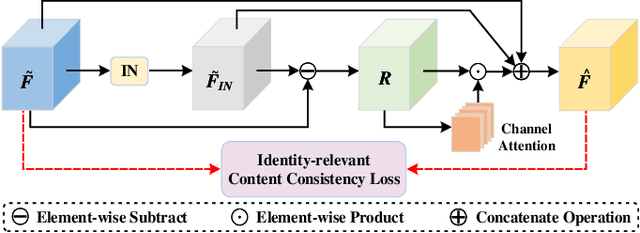
Text-based person search is a challenging task that aims to search pedestrian images with the same identity from the image gallery given a query text description. In recent years, text-based person search has made good progress, and state-of-the-art methods achieve superior performance by learning local fine-grained correspondence between images and texts. However, the existing methods explicitly extract image parts and text phrases from images and texts by hand-crafted split or external tools and then conduct complex cross-modal local matching. Moreover, the existing methods seldom consider the problem of information inequality between modalities caused by image-specific information. In this paper, we propose an efficient joint Information and Semantic Alignment Network (ISANet) for text-based person search. Specifically, we first design an image-specific information suppression module, which suppresses image background and environmental factors by relation-guide localization and channel attention filtration respectively. This design can effectively alleviate the problem of information inequality and realize the information alignment between images and texts. Secondly, we propose an implicit local alignment module to adaptively aggregate image and text features to a set of modality-shared semantic topic centers, and implicitly learn the local fine-grained correspondence between images and texts without additional supervision information and complex cross-modal interactions. Moreover, a global alignment is introduced as a supplement to the local perspective. Extensive experiments on multiple databases demonstrate the effectiveness and superiority of the proposed ISANet.