 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynAgent: Generalizable Cooperative Humanoid Manipulation via Solo-to-Cooperative Agent Synergy
Apr 20, 2026Controllable cooperative humanoid manipulation is a fundamental yet challenging problem for embodied intelligence, due to severe data scarcity, complexities in multi-agent coordination, and limited generalization across objects. In this paper, we present SynAgent, a unified framework that enables scalable and physically plausible cooperative manipulation by leveraging Solo-to-Cooperative Agent Synergy to transfer skills from single-agent human-object interaction to multi-agent human-object-human scenarios. To maintain semantic integrity during motion transfer, we introduce an interaction-preserving retargeting method based on an Interact Mesh constructed via Delaunay tetrahedralization, which faithfully maintains spatial relationships among humans and objects. Building upon this refined data, we propose a single-agent pretraining and adaptation paradigm that bootstraps synergistic collaborative behaviors from abundant single-human data through decentralized training and multi-agent PPO. Finally, we develop a trajectory-conditioned generative policy using a conditional VAE, trained via multi-teacher distillation from motion imitation priors to achieve stable and controllable object-level trajectory execution. Extensive experiments demonstrate that SynAgent significantly outperforms existing baselines in both cooperative imitation and trajectory-conditioned control, while generalizing across diverse object geometries. Codes and data will be available after publication. Project Page: http://yw0208.github.io/synagent
Precise Shield: Explaining and Aligning VLLM Safety via Neuron-Level Guidance
Apr 10, 2026In real-world deployments, Vision-Language Large Models (VLLMs) face critical challenges from multilingual and multimodal composite attacks: harmful images paired with low-resource language texts can easily bypass defenses designed for high-resource language scenarios, exposing structural blind spots in current cross-lingual and cross-modal safety methods. This raises a mechanistic question: where is safety capability instantiated within the model, and how is it distributed across languages and modalities? Prior studies on pure-text LLMs have identified cross-lingual shared safety neurons, suggesting that safety may be governed by a small subset of critical neurons. Leveraging this insight, we propose Precise Shield, a two-stage framework that first identifies safety neurons by contrasting activation patterns between harmful and benign inputs, and then constrains parameter updates strictly within this subspace via gradient masking with affecting fewer than 0.03% of parameters. This strategy substantially improves safety while preserving multilingual and multimodal generalization. Further analysis reveals a moderate overlap of safety neurons across languages and modalities, enabling zero-shot cross-lingual and cross-modal transfer of safety capabilities, and offering a new direction for neuron-level, transfer-based safety enhancement.
MAB-DQA: Addressing Query Aspect Importance in Document Question Answering with Multi-Armed Bandits
Apr 10, 2026Document Question Answering (DQA) involves generating answers from a document based on a user's query, representing a key task in document understanding. This task requires interpreting visual layouts, which has prompted recent studies to adopt multimodal Retrieval-Augmented Generation (RAG) that processes page images for answer generation. However, in multimodal RAG, visual DQA struggles to utilize a large number of images effectively, as the retrieval stage often retains only a few candidate pages (e.g., Top-4), causing informative but less visually salient content to be overlooked in favor of common yet low-information pages. To address this issue, we propose a Multi-Armed Bandit-based DQA framework (MAB-DQA) to explicitly model the varying importance of multiple implicit aspects in a query. Specifically, MAB-DQA decomposes a query into aspect-aware subqueries and retrieves an aspect-specific candidate set for each. It treats each subquery as an arm and uses preliminary reasoning results from a small number of representative pages as reward signals to estimate aspect utility. Guided by an exploration-exploitation policy, MAB-DQA dynamically reallocates retrieval budgets toward high-value aspects. With the most informative pages and their correlations, MAB-DQA generates the expected results. On four benchmarks, MAB-DQA shows an average improvement of 5%-18% over the state-of-the-art method, consistently enhancing document understanding. Code at https://github.com/ElephantOH/MAB-DQA.
VersaVogue: Visual Expert Orchestration and Preference Alignment for Unified Fashion Synthesis
Apr 08, 2026Diffusion models have driven remarkable advancements in fashion image generation, yet prior works usually treat garment generation and virtual dressing as separate problems, limiting their flexibility in real-world fashion workflows. Moreover, fashion image synthesis under multi-source heterogeneous conditions remains challenging, as existing methods typically rely on simple feature concatenation or static layer-wise injection, which often causes attribute entanglement and semantic interference. To address these issues, we propose VersaVogue, a unified framework for multi-condition controllable fashion synthesis that jointly supports garment generation and virtual dressing, corresponding to the design and showcase stages of the fashion lifecycle. Specifically, we introduce a trait-routing attention (TA) module that leverages a mixture-of-experts mechanism to dynamically route condition features to the most compatible experts and generative layers, enabling disentangled injection of visual attributes such as texture, shape, and color. To further improve realism and controllability, we develop an automated multi-perspective preference optimization (MPO) pipeline that constructs preference data without human annotation or task-specific reward models. By combining evaluators of content fidelity, textual alignment, and perceptual quality, MPO identifies reliable preference pairs, which are then used to optimize the model via direct preference optimization (DPO). Extensive experiments on both garment generation and virtual dressing benchmarks demonstrate that VersaVogue consistently outperforms existing methods in visual fidelity, semantic consistency, and fine-grained controllability.
Zero-shot HOI Detection with MLLM-based Detector-agnostic Interaction Recognition
Feb 16, 2026Zero-shot Human-object interaction (HOI) detection aims to locate humans and objects in images and recognize their interactions. While advances in open-vocabulary object detection provide promising solutions for object localization, interaction recognition (IR) remains challenging due to the combinatorial diversity of interactions. Existing methods, including two-stage methods, tightly couple IR with a specific detector and rely on coarse-grained vision-language model (VLM) features, which limit generalization to unseen interactions. In this work, we propose a decoupled framework that separates object detection from IR and leverages multi-modal large language models (MLLMs) for zero-shot IR. We introduce a deterministic generation method that formulates IR as a visual question answering task and enforces deterministic outputs, enabling training-free zero-shot IR. To further enhance performance and efficiency by fine-tuning the model, we design a spatial-aware pooling module that integrates appearance and pairwise spatial cues, and a one-pass deterministic matching method that predicts all candidate interactions in a single forward pass. Extensive experiments on HICO-DET and V-COCO demonstrate that our method achieves superior zero-shot performance, strong cross-dataset generalization, and the flexibility to integrate with any object detectors without retraining. The codes are publicly available at https://github.com/SY-Xuan/DA-HOI.
DMAP: Human-Aligned Structural Document Map for Multimodal Document Understanding
Jan 27, 2026Existing multimodal document question-answering (QA) systems predominantly rely on flat semantic retrieval, representing documents as a set of disconnected text chunks and largely neglecting their intrinsic hierarchical and relational structures. Such flattening disrupts logical and spatial dependencies - such as section organization, figure-text correspondence, and cross-reference relations, that humans naturally exploit for comprehension. To address this limitation, we introduce a document-level structural Document MAP (DMAP), which explicitly encodes both hierarchical organization and inter-element relationships within multimodal documents. Specifically, we design a Structured-Semantic Understanding Agent to construct DMAP by organizing textual content together with figures, tables, charts, etc. into a human-aligned hierarchical schema that captures both semantic and layout dependencies. Building upon this representation, a Reflective Reasoning Agent performs structure-aware and evidence-driven reasoning, dynamically assessing the sufficiency of retrieved context and iteratively refining answers through targeted interactions with DMAP. Extensive experiments on MMDocQA benchmarks demonstrate that DMAP yields document-specific structural representations aligned with human interpretive patterns, substantially enhancing retrieval precision, reasoning consistency, and multimodal comprehension over conventional RAG-based approaches. Code is available at https://github.com/Forlorin/DMAP
Combating Noisy Labels through Fostering Self- and Neighbor-Consistency
Jan 19, 2026Label noise is pervasive in various real-world scenarios, posing challenges in supervised deep learning. Deep networks are vulnerable to such label-corrupted samples due to the memorization effect. One major stream of previous methods concentrates on identifying clean data for training. However, these methods often neglect imbalances in label noise across different mini-batches and devote insufficient attention to out-of-distribution noisy data. To this end, we propose a noise-robust method named Jo-SNC (\textbf{Jo}int sample selection and model regularization based on \textbf{S}elf- and \textbf{N}eighbor-\textbf{C}onsistency). Specifically, we propose to employ the Jensen-Shannon divergence to measure the ``likelihood'' of a sample being clean or out-of-distribution. This process factors in the nearest neighbors of each sample to reinforce the reliability of clean sample identification. We design a self-adaptive, data-driven thresholding scheme to adjust per-class selection thresholds. While clean samples undergo conventional training, detected in-distribution and out-of-distribution noisy samples are trained following partial label learning and negative learning, respectively. Finally, we advance the model performance further by proposing a triplet consistency regularization that promotes self-prediction consistency, neighbor-prediction consistency, and feature consistency. Extensive experiments on various benchmark datasets and comprehensive ablation studies demonstrate the effectiveness and superiority of our approach over existing state-of-the-art methods.
Spatiotemporal-Untrammelled Mixture of Experts for Multi-Person Motion Prediction
Dec 25, 2025Comprehensively and flexibly capturing the complex spatio-temporal dependencies of human motion is critical for multi-person motion prediction. Existing methods grapple with two primary limitations: i) Inflexible spatiotemporal representation due to reliance on positional encodings for capturing spatiotemporal information. ii) High computational costs stemming from the quadratic time complexity of conventional attention mechanisms. To overcome these limitations, we propose the Spatiotemporal-Untrammelled Mixture of Experts (ST-MoE), which flexibly explores complex spatio-temporal dependencies in human motion and significantly reduces computational cost. To adaptively mine complex spatio-temporal patterns from human motion, our model incorporates four distinct types of spatiotemporal experts, each specializing in capturing different spatial or temporal dependencies. To reduce the potential computational overhead while integrating multiple experts, we introduce bidirectional spatiotemporal Mamba as experts, each sharing bidirectional temporal and spatial Mamba in distinct combinations to achieve model efficiency and parameter economy. Extensive experiments on four multi-person benchmark datasets demonstrate that our approach not only outperforms state-of-art in accuracy but also reduces model parameter by 41.38% and achieves a 3.6x speedup in training. The code is available at https://github.com/alanyz106/ST-MoE.
FoundIR-v2: Optimizing Pre-Training Data Mixtures for Image Restoration Foundation Model
Dec 10, 2025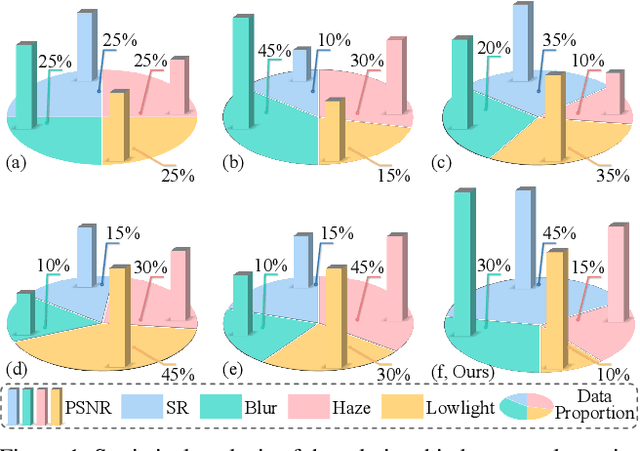
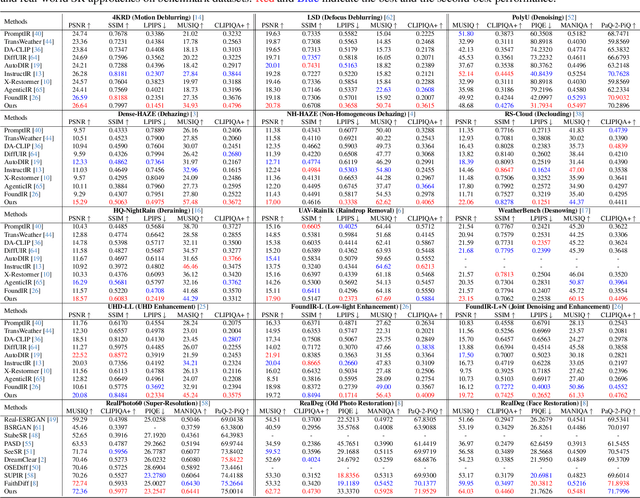
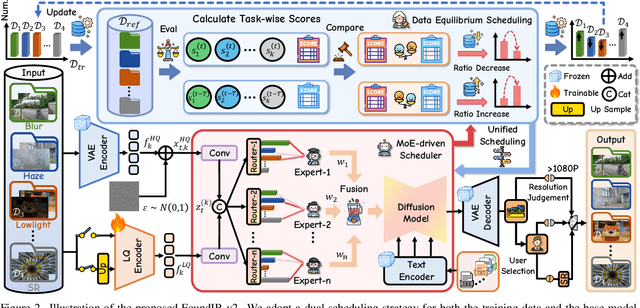
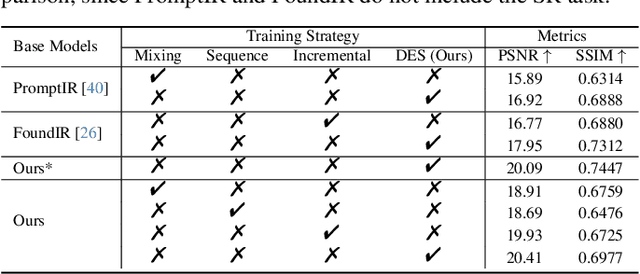
Recent studies have witnessed significant advances in image restoration foundation models driven by improvements in the scale and quality of pre-training data. In this work, we find that the data mixture proportions from different restoration tasks are also a critical factor directly determining the overall performance of all-in-one image restoration models. To this end, we propose a high-capacity diffusion-based image restoration foundation model, FoundIR-v2, which adopts a data equilibrium scheduling paradigm to dynamically optimize the proportions of mixed training datasets from different tasks. By leveraging the data mixing law, our method ensures a balanced dataset composition, enabling the model to achieve consistent generalization and comprehensive performance across diverse tasks. Furthermore, we introduce an effective Mixture-of-Experts (MoE)-driven scheduler into generative pre-training to flexibly allocate task-adaptive diffusion priors for each restoration task, accounting for the distinct degradation forms and levels exhibited by different tasks. Extensive experiments demonstrate that our method can address over 50 sub-tasks across a broader scope of real-world scenarios and achieves favorable performance against state-of-the-art approaches.
PC-Diffusion: Aligning Diffusion Models with Human Preferences via Preference Classifier
Nov 11, 2025
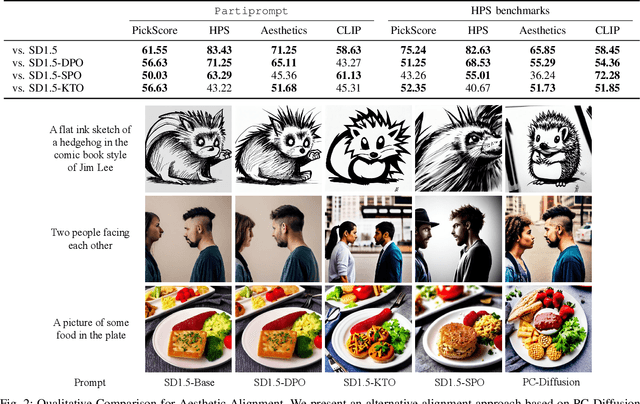
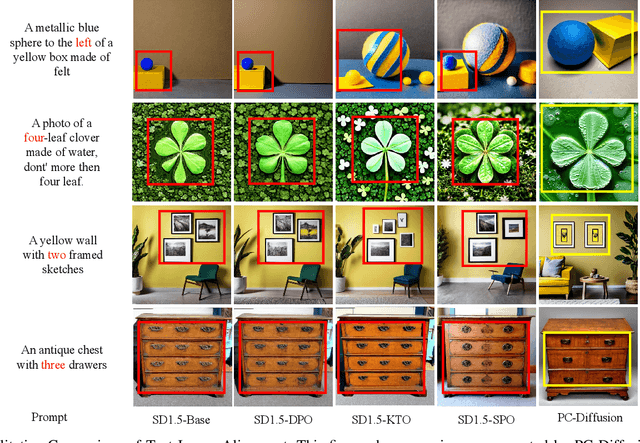

Diffusion models have achieved remarkable success in conditional image generation, yet their outputs often remain misaligned with human preferences. To address this, recent work has applied Direct Preference Optimization (DPO) to diffusion models, yielding significant improvements.~However, DPO-like methods exhibit two key limitations: 1) High computational cost,due to the entire model fine-tuning; 2) Sensitivity to reference model quality}, due to its tendency to introduce instability and bias. To overcome these limitations, we propose a novel framework for human preference alignment in diffusion models (PC-Diffusion), using a lightweight, trainable Preference Classifier that directly models the relative preference between samples. By restricting preference learning to this classifier, PC-Diffusion decouples preference alignment from the generative model, eliminating the need for entire model fine-tuning and reference model reliance.~We further provide theoretical guarantees for PC-Diffusion:1) PC-Diffusion ensures that the preference-guided distributions are consistently propagated across timesteps. 2)The training objective of the preference classifier is equivalent to DPO, but does not require a reference model.3) The proposed preference-guided correction can progressively steer generation toward preference-aligned regions.~Empirical results show that PC-Diffusion achieves comparable preference consistency to DPO while significantly reducing training costs and enabling efficient and stable preference-guided generation.