 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot HOI Detection with MLLM-based Detector-agnostic Interaction Recognition
Feb 16, 2026Zero-shot Human-object interaction (HOI) detection aims to locate humans and objects in images and recognize their interactions. While advances in open-vocabulary object detection provide promising solutions for object localization, interaction recognition (IR) remains challenging due to the combinatorial diversity of interactions. Existing methods, including two-stage methods, tightly couple IR with a specific detector and rely on coarse-grained vision-language model (VLM) features, which limit generalization to unseen interactions. In this work, we propose a decoupled framework that separates object detection from IR and leverages multi-modal large language models (MLLMs) for zero-shot IR. We introduce a deterministic generation method that formulates IR as a visual question answering task and enforces deterministic outputs, enabling training-free zero-shot IR. To further enhance performance and efficiency by fine-tuning the model, we design a spatial-aware pooling module that integrates appearance and pairwise spatial cues, and a one-pass deterministic matching method that predicts all candidate interactions in a single forward pass. Extensive experiments on HICO-DET and V-COCO demonstrate that our method achieves superior zero-shot performance, strong cross-dataset generalization, and the flexibility to integrate with any object detectors without retraining. The codes are publicly available at https://github.com/SY-Xuan/DA-HOI.
Diff-MM: Exploring Pre-trained Text-to-Image Generation Model for Unified Multi-modal Object Tracking
May 19, 2025Multi-modal object tracking integrates auxiliary modalities such as depth, thermal infrared, event flow, and language to provide additional information beyond RGB images, showing great potential in improving tracking stabilization in complex scenarios. Existing methods typically start from an RGB-based tracker and learn to understand auxiliary modalities only from training data. Constrained by the limited multi-modal training data, the performance of these methods is unsatisfactory. To alleviate this limitation, this work proposes a unified multi-modal tracker Diff-MM by exploiting the multi-modal understanding capability of the pre-trained text-to-image generation model. Diff-MM leverages the UNet of pre-trained Stable Diffusion as a tracking feature extractor through the proposed parallel feature extraction pipeline, which enables pairwise image inputs for object tracking. We further introduce a multi-modal sub-module tuning method that learns to gain complementary information between different modalities. By harnessing the extensive prior knowledge in the generation model, we achieve a unified tracker with uniform parameters for RGB-N/D/T/E tracking. Experimental results demonstrate the promising performance of our method compared with recently proposed trackers, e.g., its AUC outperforms OneTracker by 8.3% on TNL2K.
Dataset Distillation for Histopathology Image Classification
Aug 19, 2024Deep neural networks (DNNs) have exhibited remarkable success in the field of histopathology image analysis. On the other hand, the contemporary trend of employing large models and extensive datasets has underscored the significance of dataset distillation, which involves compressing large-scale datasets into a condensed set of synthetic samples, offering distinct advantages in improving training efficiency and streamlining downstream applications. In this work, we introduce a novel dataset distillation algorithm tailored for histopathology image datasets (Histo-DD), which integrates stain normalisation and model augmentation into the distillation progress. Such integration can substantially enhance the compatibility with histopathology images that are often characterised by high colour heterogeneity. We conduct a comprehensive evaluation of the effectiveness of the proposed algorithm and the generated histopathology samples in both patch-level and slide-level classification tasks. The experimental results, carried out on three publicly available WSI datasets, including Camelyon16, TCGA-IDH, and UniToPath, demonstrate that the proposed Histo-DD can generate more informative synthetic patches than previous coreset selection and patch sampling methods. Moreover, the synthetic samples can preserve discriminative information, substantially reduce training efforts, and exhibit architecture-agnostic properties. These advantages indicate that synthetic samples can serve as an alternative to large-scale datasets.
LocLLM: Exploiting Generalizable Human Keypoint Localization via Large Language Model
Jun 07, 2024The capacity of existing human keypoint localization models is limited by keypoint priors provided by the training data. To alleviate this restriction and pursue more general model, this work studies keypoint localization from a different perspective by reasoning locations based on keypiont clues in text descriptions. We propose LocLLM, the first Large-Language Model (LLM) based keypoint localization model that takes images and text instructions as inputs and outputs the desired keypoint coordinates. LocLLM leverages the strong reasoning capability of LLM and clues of keypoint type, location, and relationship in textual descriptions for keypoint localization. To effectively tune LocLLM, we construct localization-based instruction conversations to connect keypoint description with corresponding coordinates in input image, and fine-tune the whole model in a parameter-efficient training pipeline. LocLLM shows remarkable performance on standard 2D/3D keypoint localization benchmarks. Moreover, incorporating language clues into the localization makes LocLLM show superior flexibility and generalizable capability in cross dataset keypoint localization, and even detecting novel type of keypoints unseen during training.
Decoupled Contrastive Learning for Long-Tailed Recognition
Mar 10, 2024Supervised Contrastive Loss (SCL) is popular in visual representation learning. Given an anchor image, SCL pulls two types of positive samples, i.e., its augmentation and other images from the same class together, while pushes negative images apart to optimize the learned embedding. In the scenario of long-tailed recognition, where the number of samples in each class is imbalanced, treating two types of positive samples equally leads to the biased optimization for intra-category distance. In addition, similarity relationship among negative samples, that are ignored by SCL, also presents meaningful semantic cues. To improve the performance on long-tailed recognition, this paper addresses those two issues of SCL by decoupling the training objective. Specifically, it decouples two types of positives in SCL and optimizes their relations toward different objectives to alleviate the influence of the imbalanced dataset. We further propose a patch-based self distillation to transfer knowledge from head to tail classes to relieve the under-representation of tail classes. It uses patch-based features to mine shared visual patterns among different instances and leverages a self distillation procedure to transfer such knowledge. Experiments on different long-tailed classification benchmarks demonstrate the superiority of our method. For instance, it achieves the 57.7% top-1 accuracy on the ImageNet-LT dataset. Combined with the ensemble-based method, the performance can be further boosted to 59.7%, which substantially outperforms many recent works. The code is available at https://github.com/SY-Xuan/DSCL.
Pink: Unveiling the Power of Referential Comprehension for Multi-modal LLMs
Oct 01, 2023



Multi-modal Large Language Models (MLLMs) have shown remarkable capabilities in many vision-language tasks. Nevertheless, most MLLMs still lack the Referential Comprehension (RC) ability to identify a specific object or area in images, limiting their application in fine-grained perception tasks. This paper proposes a novel method to enhance the RC capability for MLLMs. Our model represents the referring object in the image using the coordinates of its bounding box and converts the coordinates into texts in a specific format. This allows the model to treat the coordinates as natural language. Moreover, we construct the instruction tuning dataset with various designed RC tasks at a low cost by unleashing the potential of annotations in existing datasets. To further boost the RC ability of the model, we propose a self-consistent bootstrapping method that extends dense object annotations of a dataset into high-quality referring-expression-bounding-box pairs. The model is trained end-to-end with a parameter-efficient tuning framework that allows both modalities to benefit from multi-modal instruction tuning. This framework requires fewer trainable parameters and less training data. Experimental results on conventional vision-language and RC tasks demonstrate the superior performance of our method. For instance, our model exhibits a 12.0% absolute accuracy improvement over Instruct-BLIP on VSR and surpasses Kosmos-2 by 24.7% on RefCOCO_val under zero-shot settings. We also attain the top position on the leaderboard of MMBench. The models, datasets, and codes are publicly available at https://github.com/SY-Xuan/Pink
Intra-Inter Camera Similarity for Unsupervised Person Re-Identification
Mar 22, 2021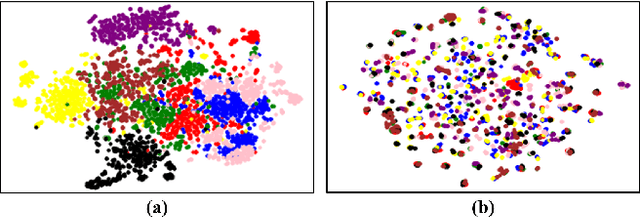

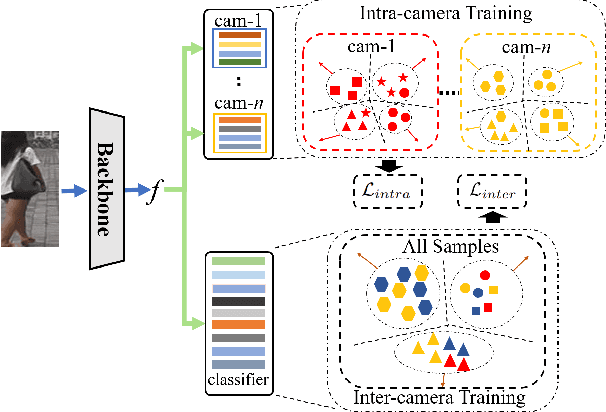

Most of unsupervised person Re-Identification (Re-ID) works produce pseudo-labels by measuring the feature similarity without considering the distribution discrepancy among cameras, leading to degraded accuracy in label computation across cameras. This paper targets to address this challenge by studying a novel intra-inter camera similarity for pseudo-label generation. We decompose the sample similarity computation into two stage, i.e., the intra-camera and inter-camera computations, respectively. The intra-camera computation directly leverages the CNN features for similarity computation within each camera. Pseudo-labels generated on different cameras train the re-id model in a multi-branch network. The second stage considers the classification scores of each sample on different cameras as a new feature vector. This new feature effectively alleviates the distribution discrepancy among cameras and generates more reliable pseudo-labels. We hence train our re-id model in two stages with intra-camera and inter-camera pseudo-labels, respectively. This simple intra-inter camera similarity produces surprisingly good performance on multiple datasets, e.g., achieves rank-1 accuracy of 89.5% on the Market1501 dataset, outperforming the recent unsupervised works by 9+%, and is comparable with the latest transfer learning works that leverage extra annotations.