 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMDformer: Patch-Mean Decoupling Information Transformer for Long-term Forecasting
Jun 25, 2026Long-term time series forecasting (LTSF) plays a crucial role in fields such as energy management, finance, and traffic prediction. Transformer-based models have adopted patch-based strategies to capture long-range dependencies, but accurately modeling shape similarities across patches and variables remains challenging due to scale differences. To address this, we introduce patch-mean decoupling (PMD), which separates the trend and residual shape information by subtracting the mean of each patch, preserving the original structure and ensuring that the attention mechanism captures true shape similarities. Futhermore, to more effectively model long-range dependencies and capture cross-variable relationships, we propose Trend Restoration Attention (TRA) and Proximal Variable Attention (PVA). The former module reintegrates the decoupled trend from PMD while calculating attention output. And the latter focuses cross-variable attention on the most relevant, recent time segments to avoid overfitting on outdated correlations. Combining these components, we propose PMDformer, a model designed to effectively capture shape similarity in long-term forecasting scenarios. Extensive experiments indicate that PMDformer outperforms existing state-of-the-art methods in stability and accuracy across multiple LTSF benchmarks. The code is available at https://github.com/aohu1105/PMDformer.
Zero-shot HOI Detection with MLLM-based Detector-agnostic Interaction Recognition
Feb 16, 2026Zero-shot Human-object interaction (HOI) detection aims to locate humans and objects in images and recognize their interactions. While advances in open-vocabulary object detection provide promising solutions for object localization, interaction recognition (IR) remains challenging due to the combinatorial diversity of interactions. Existing methods, including two-stage methods, tightly couple IR with a specific detector and rely on coarse-grained vision-language model (VLM) features, which limit generalization to unseen interactions. In this work, we propose a decoupled framework that separates object detection from IR and leverages multi-modal large language models (MLLMs) for zero-shot IR. We introduce a deterministic generation method that formulates IR as a visual question answering task and enforces deterministic outputs, enabling training-free zero-shot IR. To further enhance performance and efficiency by fine-tuning the model, we design a spatial-aware pooling module that integrates appearance and pairwise spatial cues, and a one-pass deterministic matching method that predicts all candidate interactions in a single forward pass. Extensive experiments on HICO-DET and V-COCO demonstrate that our method achieves superior zero-shot performance, strong cross-dataset generalization, and the flexibility to integrate with any object detectors without retraining. The codes are publicly available at https://github.com/SY-Xuan/DA-HOI.
TimeCNN: Refining Cross-Variable Interaction on Time Point for Time Series Forecasting
Oct 07, 2024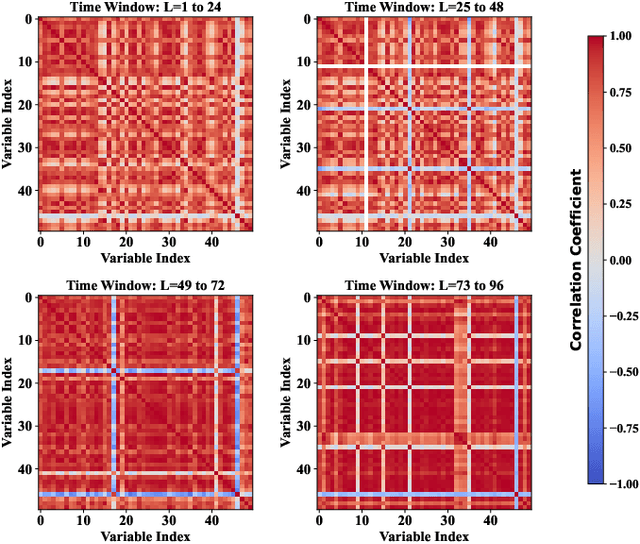
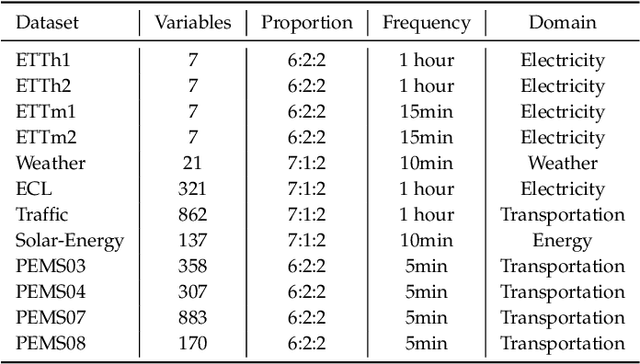
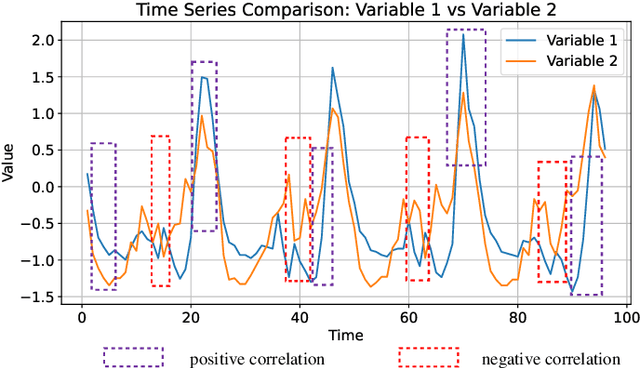
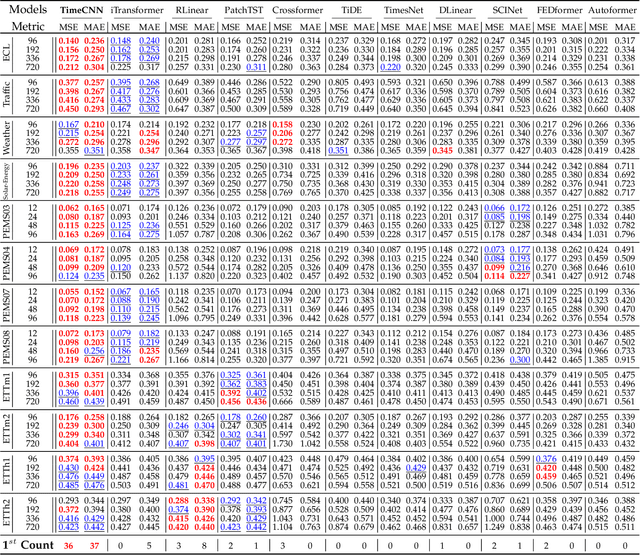
Time series forecasting is extensively applied across diverse domains. Transformer-based models demonstrate significant potential in modeling cross-time and cross-variable interaction. However, we notice that the cross-variable correlation of multivariate time series demonstrates multifaceted (positive and negative correlations) and dynamic progression over time, which is not well captured by existing Transformer-based models. To address this issue, we propose a TimeCNN model to refine cross-variable interactions to enhance time series forecasting. Its key innovation is timepoint-independent, where each time point has an independent convolution kernel, allowing each time point to have its independent model to capture relationships among variables. This approach effectively handles both positive and negative correlations and adapts to the evolving nature of variable relationships over time. Extensive experiments conducted on 12 real-world datasets demonstrate that TimeCNN consistently outperforms state-of-the-art models. Notably, our model achieves significant reductions in computational requirements (approximately 60.46%) and parameter count (about 57.50%), while delivering inference speeds 3 to 4 times faster than the benchmark iTransformer model
LocLLM: Exploiting Generalizable Human Keypoint Localization via Large Language Model
Jun 07, 2024The capacity of existing human keypoint localization models is limited by keypoint priors provided by the training data. To alleviate this restriction and pursue more general model, this work studies keypoint localization from a different perspective by reasoning locations based on keypiont clues in text descriptions. We propose LocLLM, the first Large-Language Model (LLM) based keypoint localization model that takes images and text instructions as inputs and outputs the desired keypoint coordinates. LocLLM leverages the strong reasoning capability of LLM and clues of keypoint type, location, and relationship in textual descriptions for keypoint localization. To effectively tune LocLLM, we construct localization-based instruction conversations to connect keypoint description with corresponding coordinates in input image, and fine-tune the whole model in a parameter-efficient training pipeline. LocLLM shows remarkable performance on standard 2D/3D keypoint localization benchmarks. Moreover, incorporating language clues into the localization makes LocLLM show superior flexibility and generalizable capability in cross dataset keypoint localization, and even detecting novel type of keypoints unseen during training.
Unsupervised Person Re-identification via Multi-label Classification
Apr 20, 2020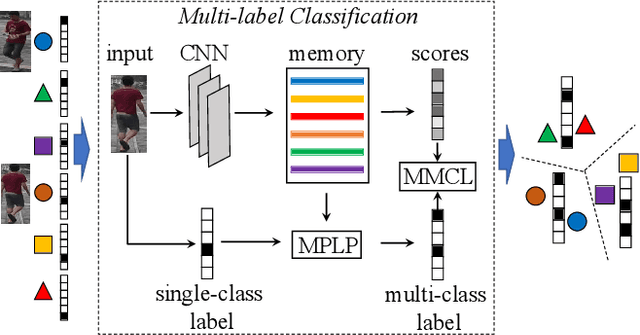
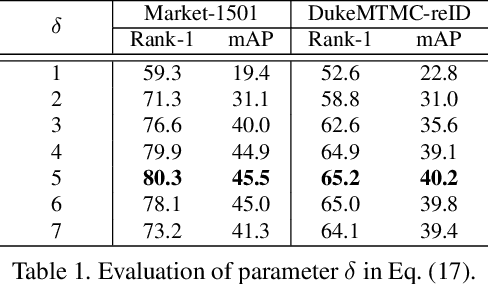
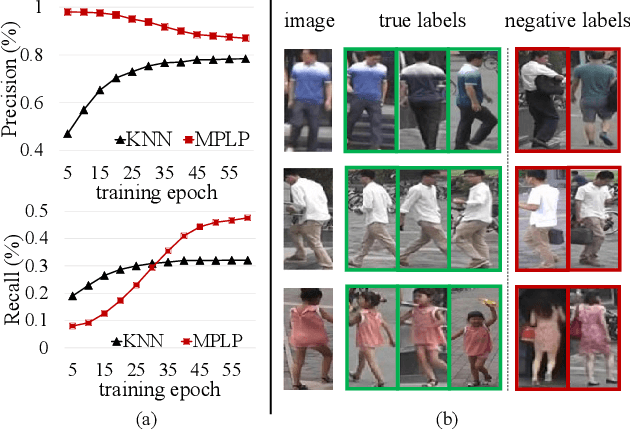
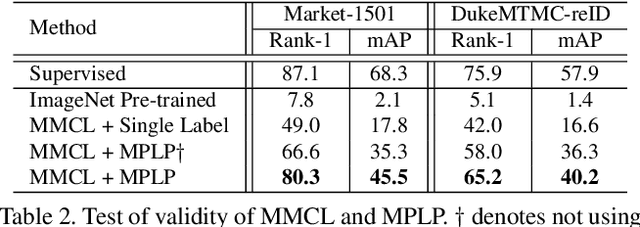
The challenge of unsupervised person re-identification (ReID) lies in learning discriminative features without true labels. This paper formulates unsupervised person ReID as a multi-label classification task to progressively seek true labels. Our method starts by assigning each person image with a single-class label, then evolves to multi-label classification by leveraging the updated ReID model for label prediction. The label prediction comprises similarity computation and cycle consistency to ensure the quality of predicted labels. To boost the ReID model training efficiency in multi-label classification, we further propose the memory-based multi-label classification loss (MMCL). MMCL works with memory-based non-parametric classifier and integrates multi-label classification and single-label classification in a unified framework. Our label prediction and MMCL work iteratively and substantially boost the ReID performance. Experiments on several large-scale person ReID datasets demonstrate the superiority of our method in unsupervised person ReID. Our method also allows to use labeled person images in other domains. Under this transfer learning setting, our method also achieves state-of-the-art performance.