 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeCNN: Refining Cross-Variable Interaction on Time Point for Time Series Forecasting
Oct 07, 2024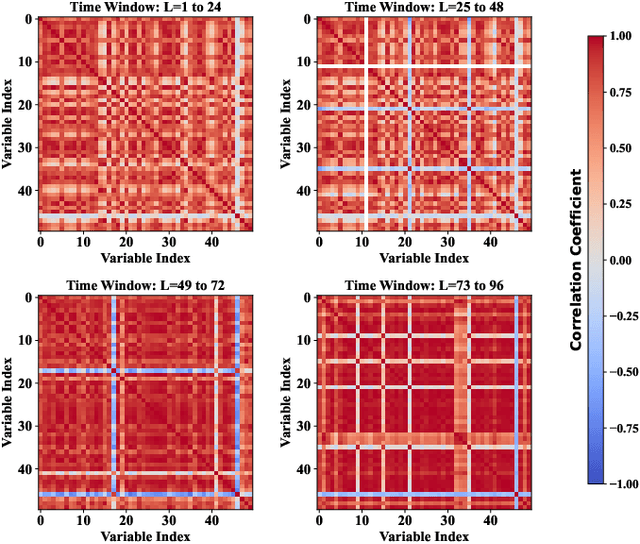
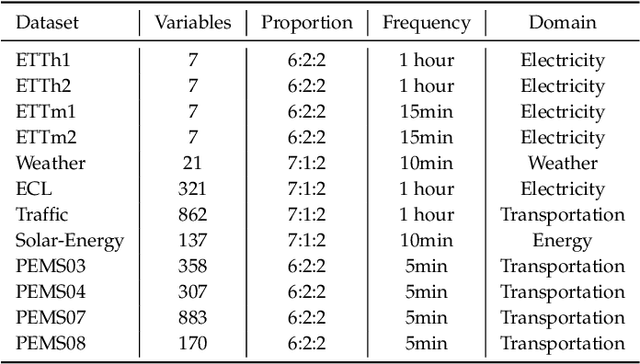
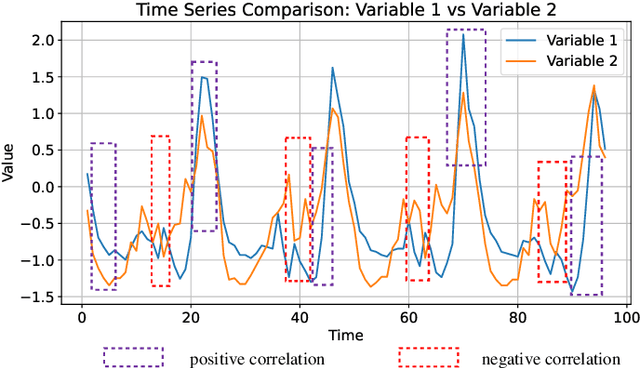
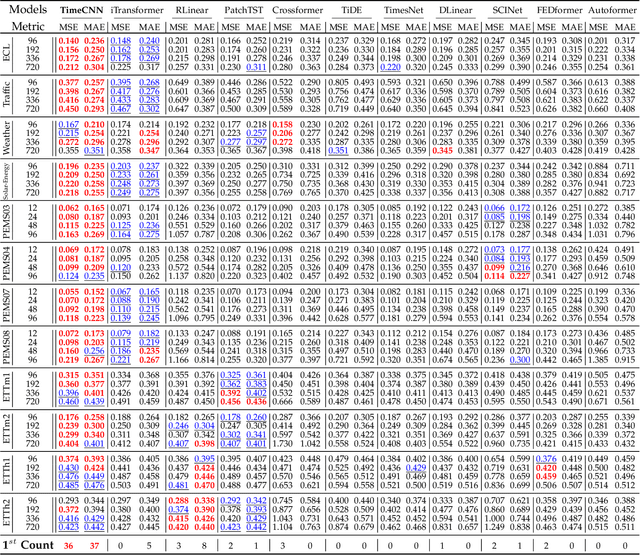
Time series forecasting is extensively applied across diverse domains. Transformer-based models demonstrate significant potential in modeling cross-time and cross-variable interaction. However, we notice that the cross-variable correlation of multivariate time series demonstrates multifaceted (positive and negative correlations) and dynamic progression over time, which is not well captured by existing Transformer-based models. To address this issue, we propose a TimeCNN model to refine cross-variable interactions to enhance time series forecasting. Its key innovation is timepoint-independent, where each time point has an independent convolution kernel, allowing each time point to have its independent model to capture relationships among variables. This approach effectively handles both positive and negative correlations and adapts to the evolving nature of variable relationships over time. Extensive experiments conducted on 12 real-world datasets demonstrate that TimeCNN consistently outperforms state-of-the-art models. Notably, our model achieves significant reductions in computational requirements (approximately 60.46%) and parameter count (about 57.50%), while delivering inference speeds 3 to 4 times faster than the benchmark iTransformer model
P2I-NET: Mapping Camera Pose to Image via Adversarial Learning for New View Synthesis in Real Indoor Environments
Sep 27, 2023



Given a new $6DoF$ camera pose in an indoor environment, we study the challenging problem of predicting the view from that pose based on a set of reference RGBD views. Existing explicit or implicit 3D geometry construction methods are computationally expensive while those based on learning have predominantly focused on isolated views of object categories with regular geometric structure. Differing from the traditional \textit{render-inpaint} approach to new view synthesis in the real indoor environment, we propose a conditional generative adversarial neural network (P2I-NET) to directly predict the new view from the given pose. P2I-NET learns the conditional distribution of the images of the environment for establishing the correspondence between the camera pose and its view of the environment, and achieves this through a number of innovative designs in its architecture and training lost function. Two auxiliary discriminator constraints are introduced for enforcing the consistency between the pose of the generated image and that of the corresponding real world image in both the latent feature space and the real world pose space. Additionally a deep convolutional neural network (CNN) is introduced to further reinforce this consistency in the pixel space. We have performed extensive new view synthesis experiments on real indoor datasets. Results show that P2I-NET has superior performance against a number of NeRF based strong baseline models. In particular, we show that P2I-NET is 40 to 100 times faster than these competitor techniques while synthesising similar quality images. Furthermore, we contribute a new publicly available indoor environment dataset containing 22 high resolution RGBD videos where each frame also has accurate camera pose parameters.
Lightness Modulated Deep Inverse Tone Mapping
Jul 16, 2021

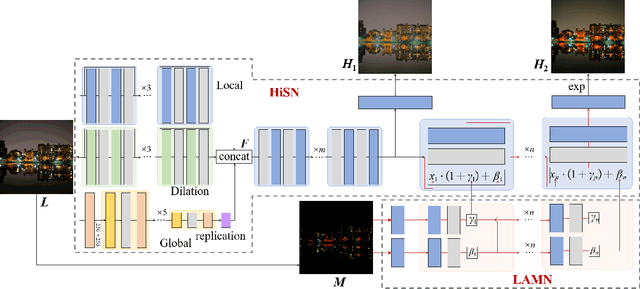

Single-image HDR reconstruction or inverse tone mapping (iTM) is a challenging task. In particular, recovering information in over-exposed regions is extremely difficult because details in such regions are almost completely lost. In this paper, we present a deep learning based iTM method that takes advantage of the feature extraction and mapping power of deep convolutional neural networks (CNNs) and uses a lightness prior to modulate the CNN to better exploit observations in the surrounding areas of the over-exposed regions to enhance the quality of HDR image reconstruction. Specifically, we introduce a Hierarchical Synthesis Network (HiSN) for inferring a HDR image from a LDR input and a Lightness Adpative Modulation Network (LAMN) to incorporate the the lightness prior knowledge in the inferring process. The HiSN hierarchically synthesizes the high-brightness component and the low-brightness component of the HDR image whilst the LAMN uses a lightness adaptive mask that separates detail-less saturated bright pixels from well-exposed lower light pixels to enable HiSN to better infer the missing information, particularly in the difficult over-exposed detail-less areas. We present experimental results to demonstrate the effectiveness of the new technique based on quantitative measures and visual comparisons. In addition, we present ablation studies of HiSN and visualization of the activation maps inside LAMN to help gain a deeper understanding of the internal working of the new iTM algorithm and explain why it can achieve much improved performance over state-of-the-art algorithms.
Supervised Anomaly Detection via Conditional Generative Adversarial Network and Ensemble Active Learning
Apr 24, 2021
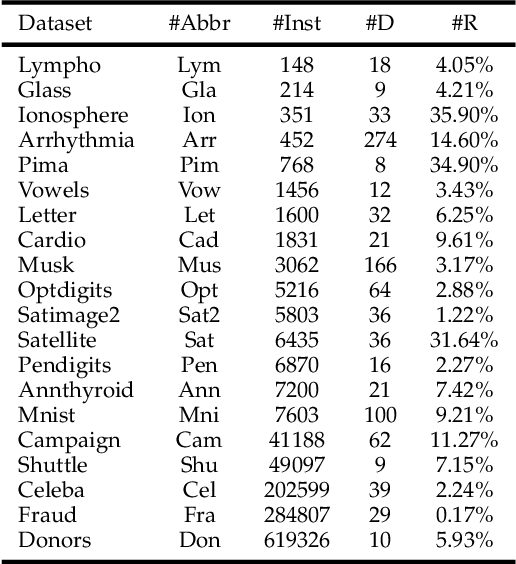
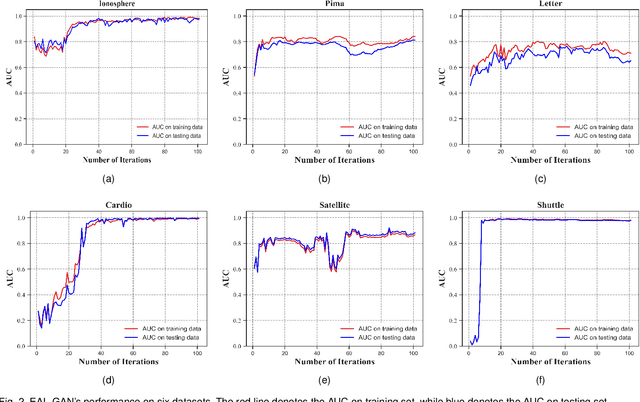
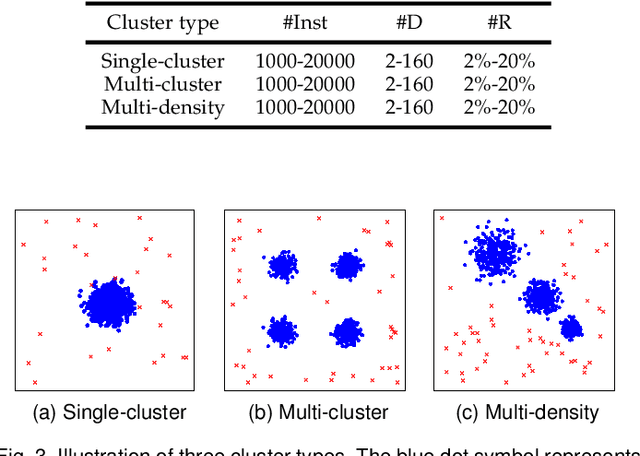
Anomaly detection has wide applications in machine intelligence but is still a difficult unsolved problem. Major challenges include the rarity of labeled anomalies and it is a class highly imbalanced problem. Traditional unsupervised anomaly detectors are suboptimal while supervised models can easily make biased predictions towards normal data. In this paper, we present a new supervised anomaly detector through introducing the novel Ensemble Active Learning Generative Adversarial Network (EAL-GAN). EAL-GAN is a conditional GAN having a unique one generator vs. multiple discriminators architecture where anomaly detection is implemented by an auxiliary classifier of the discriminator. In addition to using the conditional GAN to generate class balanced supplementary training data, an innovative ensemble learning loss function ensuring each discriminator makes up for the deficiencies of the others is designed to overcome the class imbalanced problem, and an active learning algorithm is introduced to significantly reduce the cost of labeling real-world data. We present extensive experimental results to demonstrate that the new anomaly detector consistently outperforms a variety of SOTA methods by significant margins. The codes are available on Github.
Disentangling Latent Space for Unsupervised Semantic Face Editing
Nov 05, 2020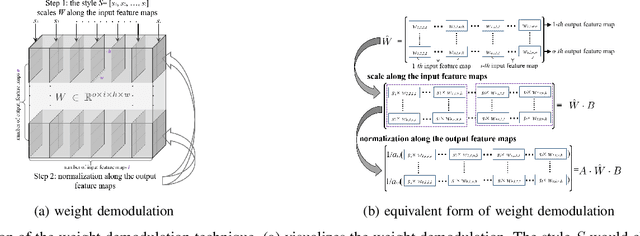
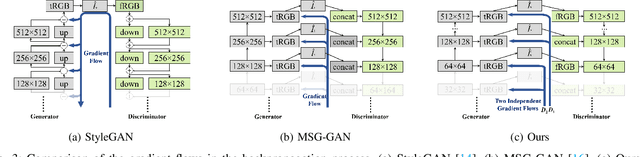

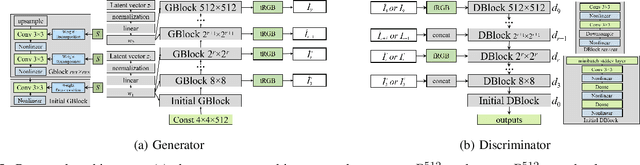
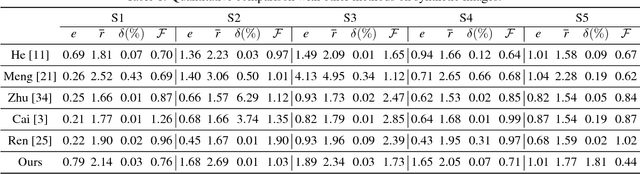
Editing facial images created by StyleGAN is a popular research topic with important applications. Through editing the latent vectors, it is possible to control the facial attributes such as smile, age, \textit{etc}. However, facial attributes are entangled in the latent space and this makes it very difficult to independently control a specific attribute without affecting the others. The key to developing neat semantic control is to completely disentangle the latent space and perform image editing in an unsupervised manner. In this paper, we present a new technique termed Structure-Texture Independent Architecture with Weight Decomposition and Orthogonal Regularization (STIA-WO) to disentangle the latent space. The GAN model, applying STIA-WO, is referred to as STGAN-WO. STGAN-WO performs weight decomposition by utilizing the style vector to construct a fully controllable weight matrix for controlling the image synthesis, and utilizes orthogonal regularization to ensure each entry of the style vector only controls one factor of variation. To further disentangle the facial attributes, STGAN-WO introduces a structure-texture independent architecture which utilizes two independently and identically distributed (i.i.d.) latent vectors to control the synthesis of the texture and structure components in a disentangled way.Unsupervised semantic editing is achieved by moving the latent code in the coarse layers along its orthogonal directions to change texture related attributes or changing the latent code in the fine layers to manipulate structure related ones. We present experimental results which show that our new STGAN-WO can achieve better attribute editing than state of the art methods (The code is available at https://github.com/max-liu-112/STGAN-WO)
End-to-End Single Image Fog Removal using Enhanced Cycle Consistent Adversarial Networks
Feb 04, 2019

Single image defogging is a classical and challenging problem in computer vision. Existing methods towards this problem mainly include handcrafted priors based methods that rely on the use of the atmospheric degradation model and learning based approaches that require paired fog-fogfree training example images. In practice, however, prior-based methods are prone to failure due to their own limitations and paired training data are extremely difficult to acquire. Inspired by the principle of CycleGAN network, we have developed an end-to-end learning system that uses unpaired fog and fogfree training images, adversarial discriminators and cycle consistency losses to automatically construct a fog removal system. Similar to CycleGAN, our system has two transformation paths; one maps fog images to a fogfree image domain and the other maps fogfree images to a fog image domain. Instead of one stage mapping, our system uses a two stage mapping strategy in each transformation path to enhance the effectiveness of fog removal. Furthermore, we make explicit use of prior knowledge in the networks by embedding the atmospheric degradation principle and a sky prior for mapping fogfree images to the fog images domain. In addition, we also contribute the first real world nature fog-fogfree image dataset for defogging research. Our multiple real fog images dataset (MRFID) contains images of 200 natural outdoor scenes. For each scene, there are one clear image and corresponding four foggy images of different fog densities manually selected from a sequence of images taken by a fixed camera over the course of one year. Qualitative and quantitative comparison against several state-of-the-art methods on both synthetic and real world images demonstrate that our approach is effective and performs favorably for recovering a clear image from a foggy image.
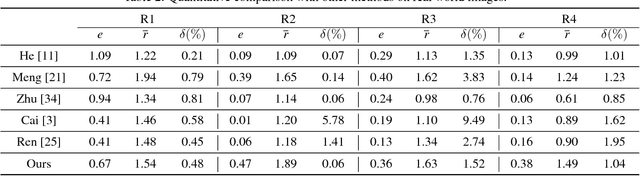
Deep Feature Consistent Deep Image Transformations: Downscaling, Decolorization and HDR Tone Mapping
Sep 11, 2017

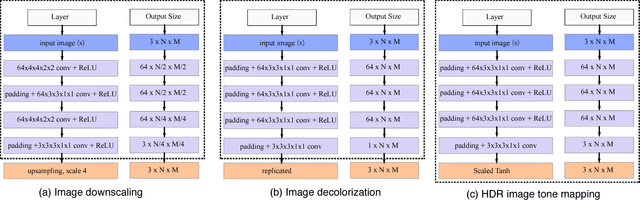
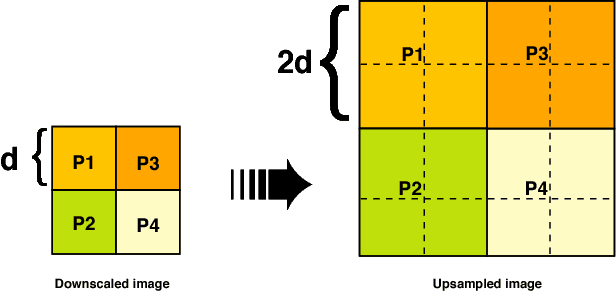
Building on crucial insights into the determining factors of the visual integrity of an image and the property of deep convolutional neural network (CNN), we have developed the Deep Feature Consistent Deep Image Transformation (DFC-DIT) framework which unifies challenging one-to-many mapping image processing problems such as image downscaling, decolorization (colour to grayscale conversion) and high dynamic range (HDR) image tone mapping. We train one CNN as a non-linear mapper to transform an input image to an output image following what we term the deep feature consistency principle which is enforced through another pretrained and fixed deep CNN. This is the first work that uses deep learning to solve and unify these three common image processing tasks. We present experimental results to demonstrate the effectiveness of the DFC-DIT technique and its state of the art performances.