 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGStream: Motion-aware 3D Gaussian for Streamable Dynamic Scene Reconstruction
May 20, 20253D Gaussian Splatting (3DGS) has gained significant attention in streamable dynamic novel view synthesis (DNVS) for its photorealistic rendering capability and computational efficiency. Despite much progress in improving rendering quality and optimization strategies, 3DGS-based streamable dynamic scene reconstruction still suffers from flickering artifacts and storage inefficiency, and struggles to model the emerging objects. To tackle this, we introduce MGStream which employs the motion-related 3D Gaussians (3DGs) to reconstruct the dynamic and the vanilla 3DGs for the static. The motion-related 3DGs are implemented according to the motion mask and the clustering-based convex hull algorithm. The rigid deformation is applied to the motion-related 3DGs for modeling the dynamic, and the attention-based optimization on the motion-related 3DGs enables the reconstruction of the emerging objects. As the deformation and optimization are only conducted on the motion-related 3DGs, MGStream avoids flickering artifacts and improves the storage efficiency. Extensive experiments on real-world datasets N3DV and MeetRoom demonstrate that MGStream surpasses existing streaming 3DGS-based approaches in terms of rendering quality, training/storage efficiency and temporal consistency. Our code is available at: https://github.com/pcl3dv/MGStream.
SPC-GS: Gaussian Splatting with Semantic-Prompt Consistency for Indoor Open-World Free-view Synthesis from Sparse Inputs
Mar 16, 20253D Gaussian Splatting-based indoor open-world free-view synthesis approaches have shown significant performance with dense input images. However, they exhibit poor performance when confronted with sparse inputs, primarily due to the sparse distribution of Gaussian points and insufficient view supervision. To relieve these challenges, we propose SPC-GS, leveraging Scene-layout-based Gaussian Initialization (SGI) and Semantic-Prompt Consistency (SPC) Regularization for open-world free view synthesis with sparse inputs. Specifically, SGI provides a dense, scene-layout-based Gaussian distribution by utilizing view-changed images generated from the video generation model and view-constraint Gaussian points densification. Additionally, SPC mitigates limited view supervision by employing semantic-prompt-based consistency constraints developed by SAM2. This approach leverages available semantics from training views, serving as instructive prompts, to optimize visually overlapping regions in novel views with 2D and 3D consistency constraints. Extensive experiments demonstrate the superior performance of SPC-GS across Replica and ScanNet benchmarks. Notably, our SPC-GS achieves a 3.06 dB gain in PSNR for reconstruction quality and a 7.3% improvement in mIoU for open-world semantic segmentation.
LoopSparseGS: Loop Based Sparse-View Friendly Gaussian Splatting
Aug 01, 2024



Despite the photorealistic novel view synthesis (NVS) performance achieved by the original 3D Gaussian splatting (3DGS), its rendering quality significantly degrades with sparse input views. This performance drop is mainly caused by the limited number of initial points generated from the sparse input, insufficient supervision during the training process, and inadequate regularization of the oversized Gaussian ellipsoids. To handle these issues, we propose the LoopSparseGS, a loop-based 3DGS framework for the sparse novel view synthesis task. In specific, we propose a loop-based Progressive Gaussian Initialization (PGI) strategy that could iteratively densify the initialized point cloud using the rendered pseudo images during the training process. Then, the sparse and reliable depth from the Structure from Motion, and the window-based dense monocular depth are leveraged to provide precise geometric supervision via the proposed Depth-alignment Regularization (DAR). Additionally, we introduce a novel Sparse-friendly Sampling (SFS) strategy to handle oversized Gaussian ellipsoids leading to large pixel errors. Comprehensive experiments on four datasets demonstrate that LoopSparseGS outperforms existing state-of-the-art methods for sparse-input novel view synthesis, across indoor, outdoor, and object-level scenes with various image resolutions.
CLIP-GS: CLIP-Informed Gaussian Splatting for Real-time and View-consistent 3D Semantic Understanding
Apr 22, 2024



The recent 3D Gaussian Splatting (GS) exhibits high-quality and real-time synthesis of novel views in 3D scenes. Currently, it primarily focuses on geometry and appearance modeling, while lacking the semantic understanding of scenes. To bridge this gap, we present CLIP-GS, which integrates semantics from Contrastive Language-Image Pre-Training (CLIP) into Gaussian Splatting to efficiently comprehend 3D environments without annotated semantic data. In specific, rather than straightforwardly learning and rendering high-dimensional semantic features of 3D Gaussians, which significantly diminishes the efficiency, we propose a Semantic Attribute Compactness (SAC) approach. SAC exploits the inherent unified semantics within objects to learn compact yet effective semantic representations of 3D Gaussians, enabling highly efficient rendering (>100 FPS). Additionally, to address the semantic ambiguity, caused by utilizing view-inconsistent 2D CLIP semantics to supervise Gaussians, we introduce a 3D Coherent Self-training (3DCS) strategy, resorting to the multi-view consistency originated from the 3D model. 3DCS imposes cross-view semantic consistency constraints by leveraging refined, self-predicted pseudo-labels derived from the trained 3D Gaussian model, thereby enhancing precise and view-consistent segmentation results. Extensive experiments demonstrate that our method remarkably outperforms existing state-of-the-art approaches, achieving improvements of 17.29% and 20.81% in mIoU metric on Replica and ScanNet datasets, respectively, while maintaining real-time rendering speed. Furthermore, our approach exhibits superior performance even with sparse input data, verifying the robustness of our method.
OV-NeRF: Open-vocabulary Neural Radiance Fields with Vision and Language Foundation Models for 3D Semantic Understanding
Feb 07, 2024



The development of Neural Radiance Fields (NeRFs) has provided a potent representation for encapsulating the geometric and appearance characteristics of 3D scenes. Enhancing the capabilities of NeRFs in open-vocabulary 3D semantic perception tasks has been a recent focus. However, current methods that extract semantics directly from Contrastive Language-Image Pretraining (CLIP) for semantic field learning encounter difficulties due to noisy and view-inconsistent semantics provided by CLIP. To tackle these limitations, we propose OV-NeRF, which exploits the potential of pre-trained vision and language foundation models to enhance semantic field learning through proposed single-view and cross-view strategies. First, from the single-view perspective, we introduce Region Semantic Ranking (RSR) regularization by leveraging 2D mask proposals derived from SAM to rectify the noisy semantics of each training view, facilitating accurate semantic field learning. Second, from the cross-view perspective, we propose a Cross-view Self-enhancement (CSE) strategy to address the challenge raised by view-inconsistent semantics. Rather than invariably utilizing the 2D inconsistent semantics from CLIP, CSE leverages the 3D consistent semantics generated from the well-trained semantic field itself for semantic field training, aiming to reduce ambiguity and enhance overall semantic consistency across different views. Extensive experiments validate our OV-NeRF outperforms current state-of-the-art methods, achieving a significant improvement of 20.31% and 18.42% in mIoU metric on Replica and Scannet, respectively. Furthermore, our approach exhibits consistent superior results across various CLIP configurations, further verifying its robustness.
PSAvatar: A Point-based Morphable Shape Model for Real-Time Head Avatar Animation with 3D Gaussian Splatting
Jan 30, 2024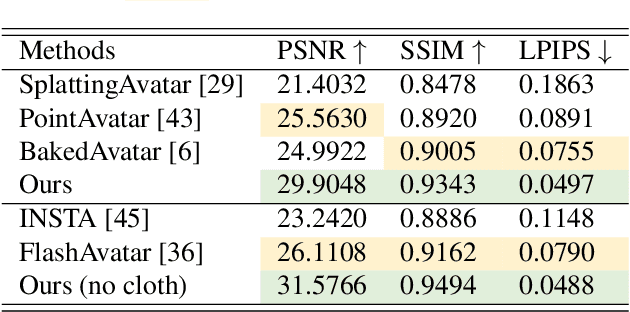



Despite much progress, achieving real-time high-fidelity head avatar animation is still difficult and existing methods have to trade-off between speed and quality. 3DMM based methods often fail to model non-facial structures such as eyeglasses and hairstyles, while neural implicit models suffer from deformation inflexibility and rendering inefficiency. Although 3D Gaussian has been demonstrated to possess promising capability for geometry representation and radiance field reconstruction, applying 3D Gaussian in head avatar creation remains a major challenge since it is difficult for 3D Gaussian to model the head shape variations caused by changing poses and expressions. In this paper, we introduce PSAvatar, a novel framework for animatable head avatar creation that utilizes discrete geometric primitive to create a parametric morphable shape model and employs 3D Gaussian for fine detail representation and high fidelity rendering. The parametric morphable shape model is a Point-based Morphable Shape Model (PMSM) which uses points instead of meshes for 3D representation to achieve enhanced representation flexibility. The PMSM first converts the FLAME mesh to points by sampling on the surfaces as well as off the meshes to enable the reconstruction of not only surface-like structures but also complex geometries such as eyeglasses and hairstyles. By aligning these points with the head shape in an analysis-by-synthesis manner, the PMSM makes it possible to utilize 3D Gaussian for fine detail representation and appearance modeling, thus enabling the creation of high-fidelity avatars. We show that PSAvatar can reconstruct high-fidelity head avatars of a variety of subjects and the avatars can be animated in real-time ($\ge$ 25 fps at a resolution of 512 $\times$ 512 ).
3D Reconstruction and New View Synthesis of Indoor Environments based on a Dual Neural Radiance Field
Jan 26, 2024



Simultaneously achieving 3D reconstruction and new view synthesis for indoor environments has widespread applications but is technically very challenging. State-of-the-art methods based on implicit neural functions can achieve excellent 3D reconstruction results, but their performances on new view synthesis can be unsatisfactory. The exciting development of neural radiance field (NeRF) has revolutionized new view synthesis, however, NeRF-based models can fail to reconstruct clean geometric surfaces. We have developed a dual neural radiance field (Du-NeRF) to simultaneously achieve high-quality geometry reconstruction and view rendering. Du-NeRF contains two geometric fields, one derived from the SDF field to facilitate geometric reconstruction and the other derived from the density field to boost new view synthesis. One of the innovative features of Du-NeRF is that it decouples a view-independent component from the density field and uses it as a label to supervise the learning process of the SDF field. This reduces shape-radiance ambiguity and enables geometry and color to benefit from each other during the learning process. Extensive experiments demonstrate that Du-NeRF can significantly improve the performance of novel view synthesis and 3D reconstruction for indoor environments and it is particularly effective in constructing areas containing fine geometries that do not obey multi-view color consistency.
Redistributing the Precision and Content in 3D-LUT-based Inverse Tone-mapping for HDR/WCG Display
Oct 15, 2023ITM(inverse tone-mapping) converts SDR (standard dynamic range) footage to HDR/WCG (high dynamic range /wide color gamut) for media production. It happens not only when remastering legacy SDR footage in front-end content provider, but also adapting on-theair SDR service on user-end HDR display. The latter requires more efficiency, thus the pre-calculated LUT (look-up table) has become a popular solution. Yet, conventional fixed LUT lacks adaptability, so we learn from research community and combine it with AI. Meanwhile, higher-bit-depth HDR/WCG requires larger LUT than SDR, so we consult traditional ITM for an efficiency-performance trade-off: We use 3 smaller LUTs, each has a non-uniform packing (precision) respectively denser in dark, middle and bright luma range. In this case, their results will have less error only in their own range, so we use a contribution map to combine their best parts to final result. With the guidance of this map, the elements (content) of 3 LUTs will also be redistributed during training. We conduct ablation studies to verify method's effectiveness, and subjective and objective experiments to show its practicability. Code is available at: https://github.com/AndreGuo/ITMLUT.
P2I-NET: Mapping Camera Pose to Image via Adversarial Learning for New View Synthesis in Real Indoor Environments
Sep 27, 2023



Given a new $6DoF$ camera pose in an indoor environment, we study the challenging problem of predicting the view from that pose based on a set of reference RGBD views. Existing explicit or implicit 3D geometry construction methods are computationally expensive while those based on learning have predominantly focused on isolated views of object categories with regular geometric structure. Differing from the traditional \textit{render-inpaint} approach to new view synthesis in the real indoor environment, we propose a conditional generative adversarial neural network (P2I-NET) to directly predict the new view from the given pose. P2I-NET learns the conditional distribution of the images of the environment for establishing the correspondence between the camera pose and its view of the environment, and achieves this through a number of innovative designs in its architecture and training lost function. Two auxiliary discriminator constraints are introduced for enforcing the consistency between the pose of the generated image and that of the corresponding real world image in both the latent feature space and the real world pose space. Additionally a deep convolutional neural network (CNN) is introduced to further reinforce this consistency in the pixel space. We have performed extensive new view synthesis experiments on real indoor datasets. Results show that P2I-NET has superior performance against a number of NeRF based strong baseline models. In particular, we show that P2I-NET is 40 to 100 times faster than these competitor techniques while synthesising similar quality images. Furthermore, we contribute a new publicly available indoor environment dataset containing 22 high resolution RGBD videos where each frame also has accurate camera pose parameters.
Lightness Modulated Deep Inverse Tone Mapping
Jul 16, 2021

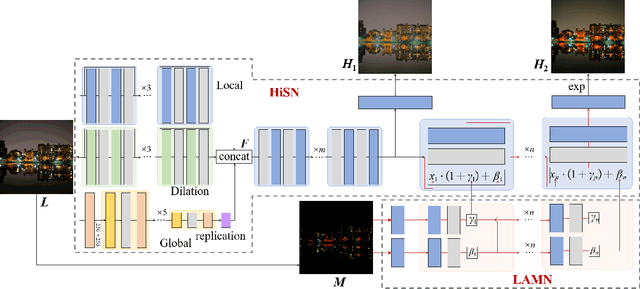

Single-image HDR reconstruction or inverse tone mapping (iTM) is a challenging task. In particular, recovering information in over-exposed regions is extremely difficult because details in such regions are almost completely lost. In this paper, we present a deep learning based iTM method that takes advantage of the feature extraction and mapping power of deep convolutional neural networks (CNNs) and uses a lightness prior to modulate the CNN to better exploit observations in the surrounding areas of the over-exposed regions to enhance the quality of HDR image reconstruction. Specifically, we introduce a Hierarchical Synthesis Network (HiSN) for inferring a HDR image from a LDR input and a Lightness Adpative Modulation Network (LAMN) to incorporate the the lightness prior knowledge in the inferring process. The HiSN hierarchically synthesizes the high-brightness component and the low-brightness component of the HDR image whilst the LAMN uses a lightness adaptive mask that separates detail-less saturated bright pixels from well-exposed lower light pixels to enable HiSN to better infer the missing information, particularly in the difficult over-exposed detail-less areas. We present experimental results to demonstrate the effectiveness of the new technique based on quantitative measures and visual comparisons. In addition, we present ablation studies of HiSN and visualization of the activation maps inside LAMN to help gain a deeper understanding of the internal working of the new iTM algorithm and explain why it can achieve much improved performance over state-of-the-art algorithms.