 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightness Modulated Deep Inverse Tone Mapping
Jul 16, 2021

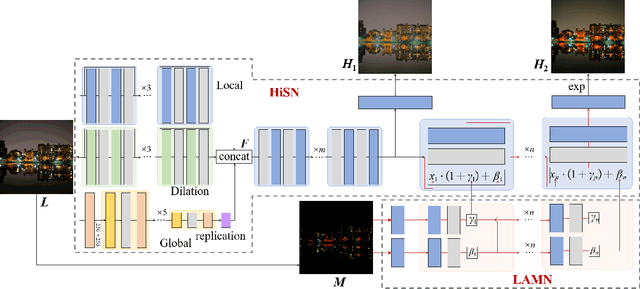

Single-image HDR reconstruction or inverse tone mapping (iTM) is a challenging task. In particular, recovering information in over-exposed regions is extremely difficult because details in such regions are almost completely lost. In this paper, we present a deep learning based iTM method that takes advantage of the feature extraction and mapping power of deep convolutional neural networks (CNNs) and uses a lightness prior to modulate the CNN to better exploit observations in the surrounding areas of the over-exposed regions to enhance the quality of HDR image reconstruction. Specifically, we introduce a Hierarchical Synthesis Network (HiSN) for inferring a HDR image from a LDR input and a Lightness Adpative Modulation Network (LAMN) to incorporate the the lightness prior knowledge in the inferring process. The HiSN hierarchically synthesizes the high-brightness component and the low-brightness component of the HDR image whilst the LAMN uses a lightness adaptive mask that separates detail-less saturated bright pixels from well-exposed lower light pixels to enable HiSN to better infer the missing information, particularly in the difficult over-exposed detail-less areas. We present experimental results to demonstrate the effectiveness of the new technique based on quantitative measures and visual comparisons. In addition, we present ablation studies of HiSN and visualization of the activation maps inside LAMN to help gain a deeper understanding of the internal working of the new iTM algorithm and explain why it can achieve much improved performance over state-of-the-art algorithms.
Disentangling Latent Space for Unsupervised Semantic Face Editing
Nov 05, 2020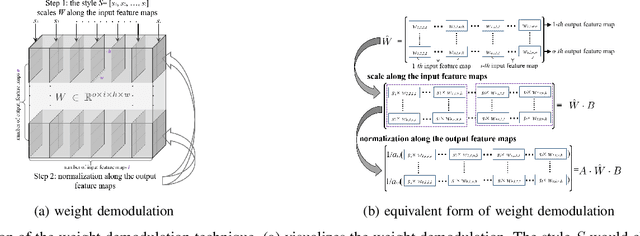
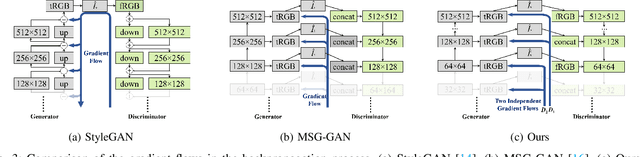

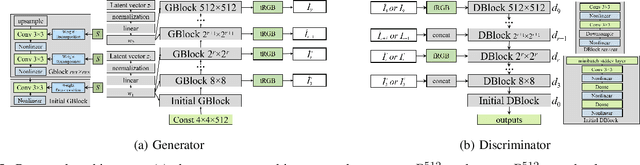
Editing facial images created by StyleGAN is a popular research topic with important applications. Through editing the latent vectors, it is possible to control the facial attributes such as smile, age, \textit{etc}. However, facial attributes are entangled in the latent space and this makes it very difficult to independently control a specific attribute without affecting the others. The key to developing neat semantic control is to completely disentangle the latent space and perform image editing in an unsupervised manner. In this paper, we present a new technique termed Structure-Texture Independent Architecture with Weight Decomposition and Orthogonal Regularization (STIA-WO) to disentangle the latent space. The GAN model, applying STIA-WO, is referred to as STGAN-WO. STGAN-WO performs weight decomposition by utilizing the style vector to construct a fully controllable weight matrix for controlling the image synthesis, and utilizes orthogonal regularization to ensure each entry of the style vector only controls one factor of variation. To further disentangle the facial attributes, STGAN-WO introduces a structure-texture independent architecture which utilizes two independently and identically distributed (i.i.d.) latent vectors to control the synthesis of the texture and structure components in a disentangled way.Unsupervised semantic editing is achieved by moving the latent code in the coarse layers along its orthogonal directions to change texture related attributes or changing the latent code in the fine layers to manipulate structure related ones. We present experimental results which show that our new STGAN-WO can achieve better attribute editing than state of the art methods (The code is available at https://github.com/max-liu-112/STGAN-WO)