 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDRfeat: A Feature-Rich Network for High Dynamic Range Image Reconstruction
Nov 08, 2022



A major challenge for high dynamic range (HDR) image reconstruction from multi-exposed low dynamic range (LDR) images, especially with dynamic scenes, is the extraction and merging of relevant contextual features in order to suppress any ghosting and blurring artifacts from moving objects. To tackle this, in this work we propose a novel network for HDR reconstruction with deep and rich feature extraction layers, including residual attention blocks with sequential channel and spatial attention. For the compression of the rich-features to the HDR domain, a residual feature distillation block (RFDB) based architecture is adopted. In contrast to earlier deep-learning methods for HDR, the above contributions shift focus from merging/compression to feature extraction, the added value of which we demonstrate with ablation experiments. We present qualitative and quantitative comparisons on a public benchmark dataset, showing that our proposed method outperforms the state-of-the-art.
VHS to HDTV Video Translation using Multi-task Adversarial Learning
Jan 07, 2021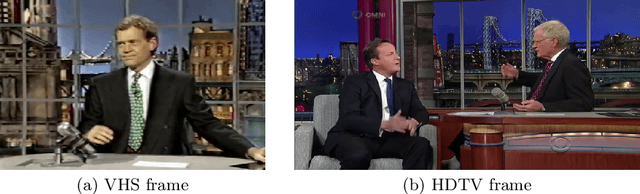

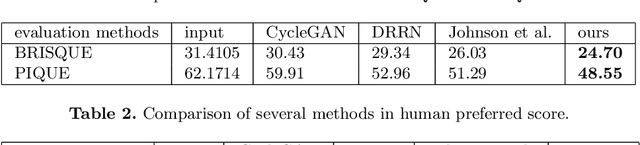
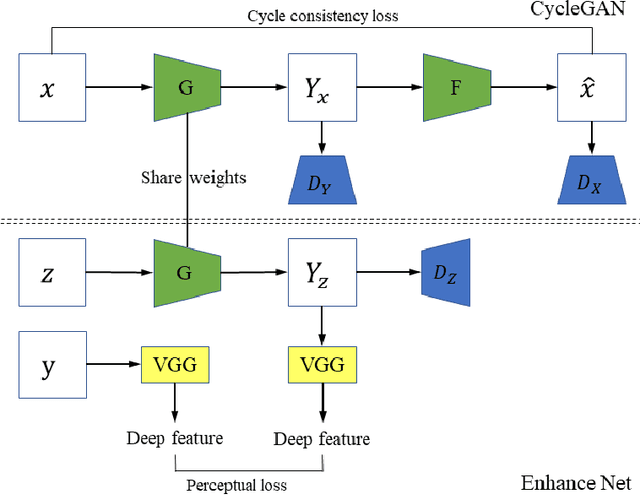
There are large amount of valuable video archives in Video Home System (VHS) format. However, due to the analog nature, their quality is often poor. Compared to High-definition television (HDTV), VHS video not only has a dull color appearance but also has a lower resolution and often appears blurry. In this paper, we focus on the problem of translating VHS video to HDTV video and have developed a solution based on a novel unsupervised multi-task adversarial learning model. Inspired by the success of generative adversarial network (GAN) and CycleGAN, we employ cycle consistency loss, adversarial loss and perceptual loss together to learn a translation model. An important innovation of our work is the incorporation of super-resolution model and color transfer model that can solve unsupervised multi-task problem. To our knowledge, this is the first work that dedicated to the study of the relation between VHS and HDTV and the first computational solution to translate VHS to HDTV. We present experimental results to demonstrate the effectiveness of our solution qualitatively and quantitatively.
Disentangling Latent Space for Unsupervised Semantic Face Editing
Nov 05, 2020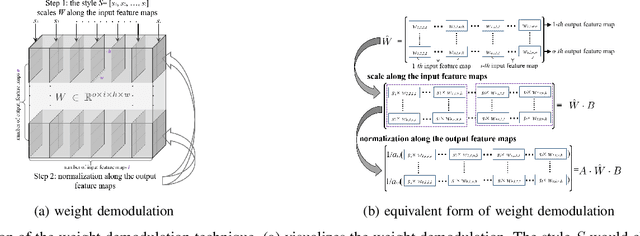
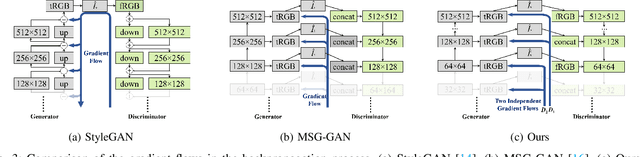

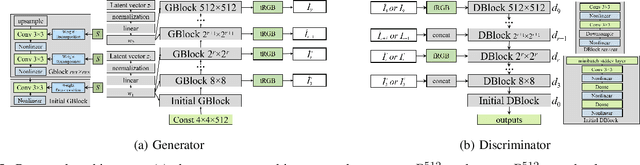
Editing facial images created by StyleGAN is a popular research topic with important applications. Through editing the latent vectors, it is possible to control the facial attributes such as smile, age, \textit{etc}. However, facial attributes are entangled in the latent space and this makes it very difficult to independently control a specific attribute without affecting the others. The key to developing neat semantic control is to completely disentangle the latent space and perform image editing in an unsupervised manner. In this paper, we present a new technique termed Structure-Texture Independent Architecture with Weight Decomposition and Orthogonal Regularization (STIA-WO) to disentangle the latent space. The GAN model, applying STIA-WO, is referred to as STGAN-WO. STGAN-WO performs weight decomposition by utilizing the style vector to construct a fully controllable weight matrix for controlling the image synthesis, and utilizes orthogonal regularization to ensure each entry of the style vector only controls one factor of variation. To further disentangle the facial attributes, STGAN-WO introduces a structure-texture independent architecture which utilizes two independently and identically distributed (i.i.d.) latent vectors to control the synthesis of the texture and structure components in a disentangled way.Unsupervised semantic editing is achieved by moving the latent code in the coarse layers along its orthogonal directions to change texture related attributes or changing the latent code in the fine layers to manipulate structure related ones. We present experimental results which show that our new STGAN-WO can achieve better attribute editing than state of the art methods (The code is available at https://github.com/max-liu-112/STGAN-WO)
Class-Aware Domain Adaptation for Improving Adversarial Robustness
May 10, 2020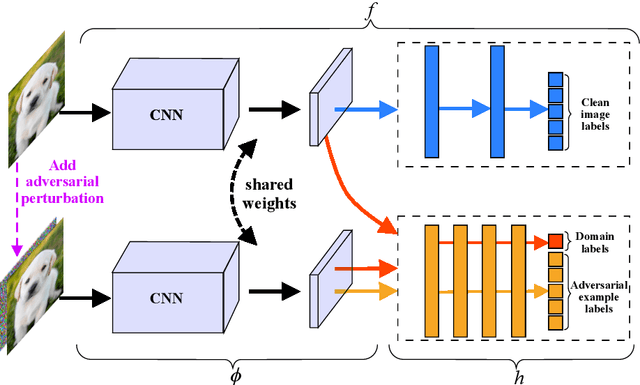
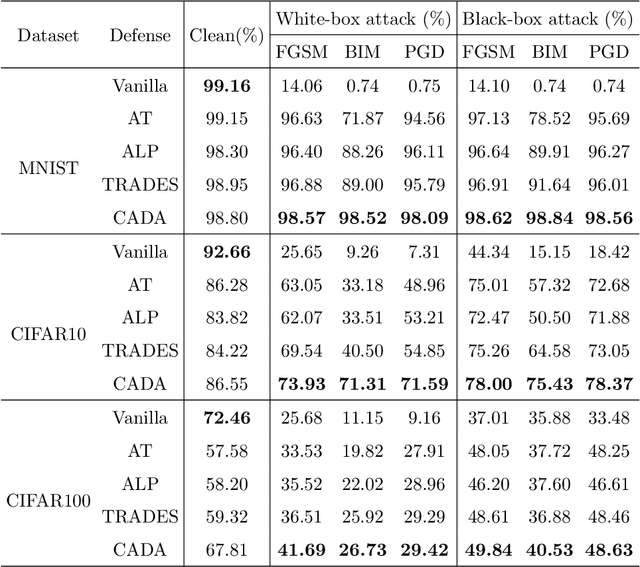
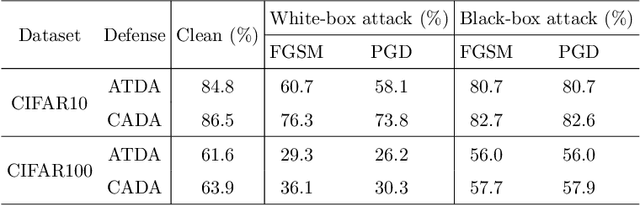
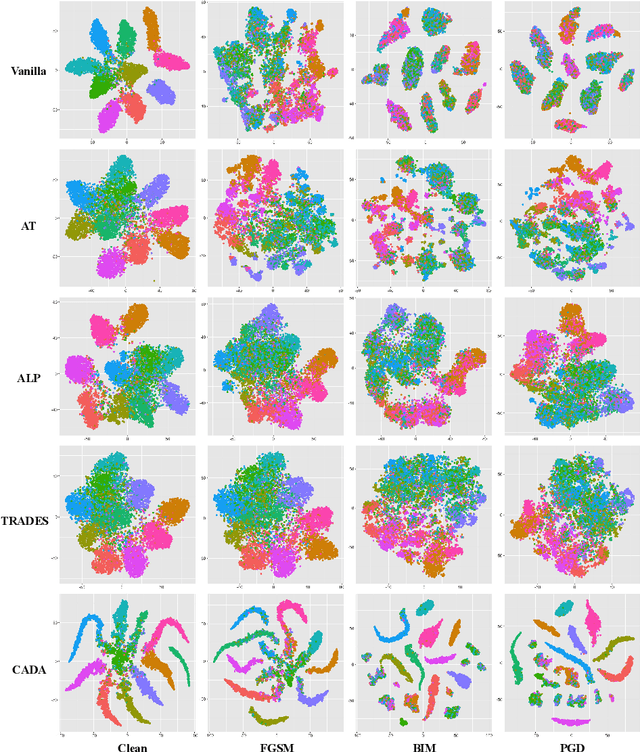
Recent works have demonstrated convolutional neural networks are vulnerable to adversarial examples, i.e., inputs to machine learning models that an attacker has intentionally designed to cause the models to make a mistake. To improve the adversarial robustness of neural networks, adversarial training has been proposed to train networks by injecting adversarial examples into the training data. However, adversarial training could overfit to a specific type of adversarial attack and also lead to standard accuracy drop on clean images. To this end, we propose a novel Class-Aware Domain Adaptation (CADA) method for adversarial defense without directly applying adversarial training. Specifically, we propose to learn domain-invariant features for adversarial examples and clean images via a domain discriminator. Furthermore, we introduce a class-aware component into the discriminator to increase the discriminative power of the network for adversarial examples. We evaluate our newly proposed approach using multiple benchmark datasets. The results demonstrate that our method can significantly improve the state-of-the-art of adversarial robustness for various attacks and maintain high performances on clean images.
Dual Adaptive Pyramid Network for Cross-Stain Histopathology Image Segmentation
Sep 25, 2019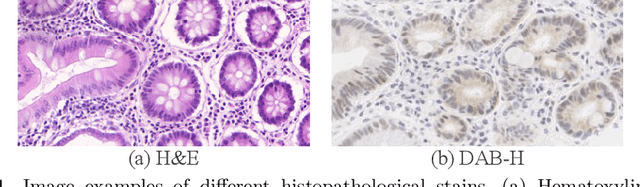
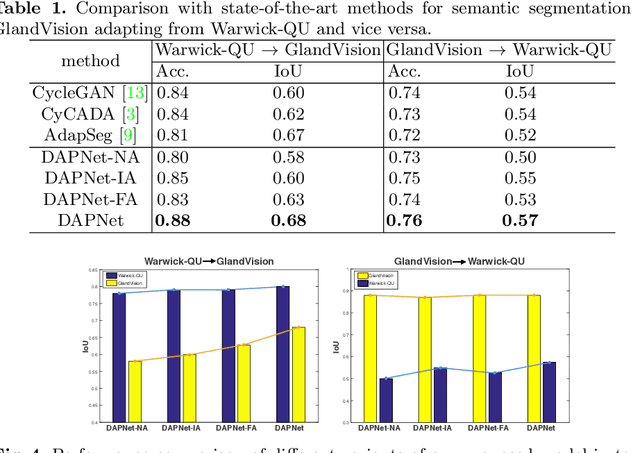
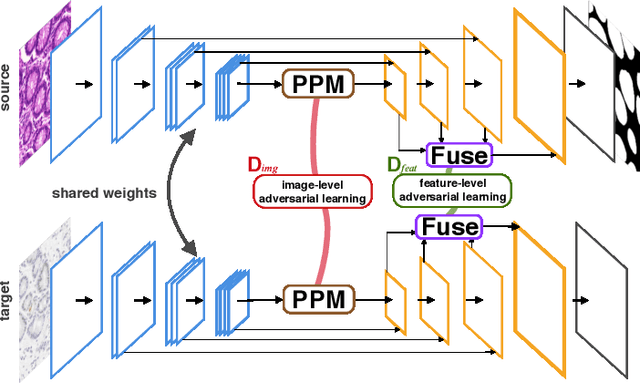
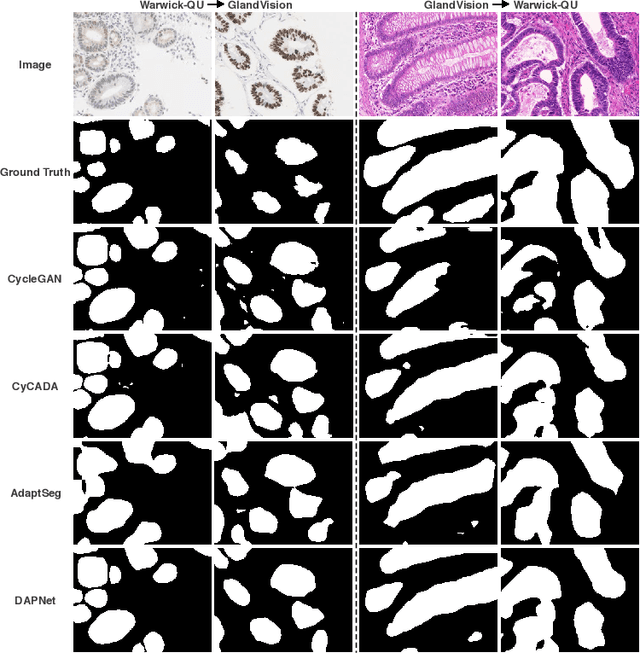
Supervised semantic segmentation normally assumes the test data being in a similar data domain as the training data. However, in practice, the domain mismatch between the training and unseen data could lead to a significant performance drop. Obtaining accurate pixel-wise label for images in different domains is tedious and labor intensive, especially for histopathology images. In this paper, we propose a dual adaptive pyramid network (DAPNet) for histopathological gland segmentation adapting from one stain domain to another. We tackle the domain adaptation problem on two levels: 1) the image-level considers the differences of image color and style; 2) the feature-level addresses the spatial inconsistency between two domains. The two components are implemented as domain classifiers with adversarial training. We evaluate our new approach using two gland segmentation datasets with H&E and DAB-H stains respectively. The extensive experiments and ablation study demonstrate the effectiveness of our approach on the domain adaptive segmentation task. We show that the proposed approach performs favorably against other state-of-the-art methods.
Learning Deep Image Priors for Blind Image Denoising
Jun 04, 2019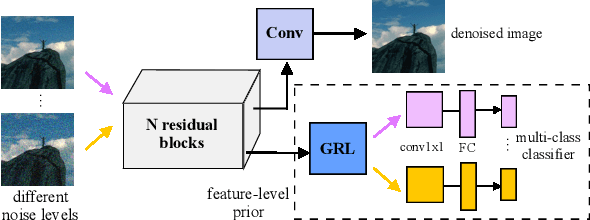
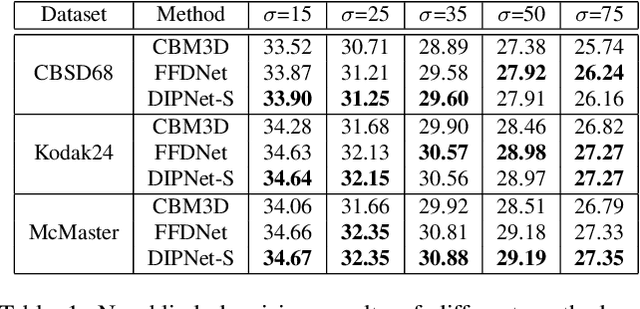
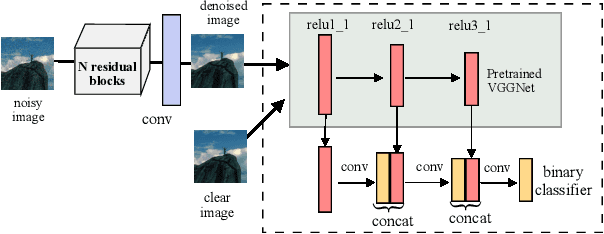
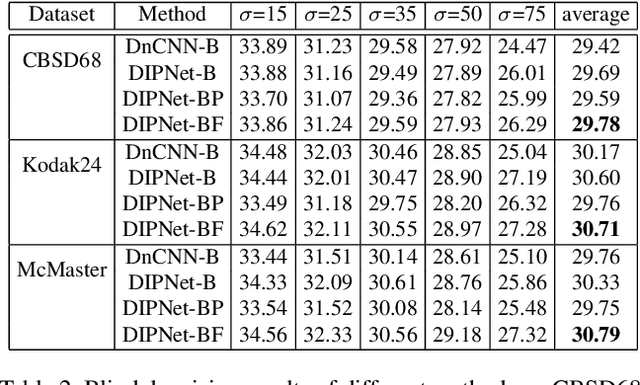
Image denoising is the process of removing noise from noisy images, which is an image domain transferring task, i.e., from a single or several noise level domains to a photo-realistic domain. In this paper, we propose an effective image denoising method by learning two image priors from the perspective of domain alignment. We tackle the domain alignment on two levels. 1) the feature-level prior is to learn domain-invariant features for corrupted images with different level noise; 2) the pixel-level prior is used to push the denoised images to the natural image manifold. The two image priors are based on $\mathcal{H}$-divergence theory and implemented by learning classifiers in adversarial training manners. We evaluate our approach on multiple datasets. The results demonstrate the effectiveness of our approach for robust image denoising on both synthetic and real-world noisy images. Furthermore, we show that the feature-level prior is capable of alleviating the discrepancy between different level noise. It can be used to improve the blind denoising performance in terms of distortion measures (PSNR and SSIM), while pixel-level prior can effectively improve the perceptual quality to ensure the realistic outputs, which is further validated by subjective evaluation.
Look, Investigate, and Classify: A Deep Hybrid Attention Method for Breast Cancer Classification
Feb 28, 2019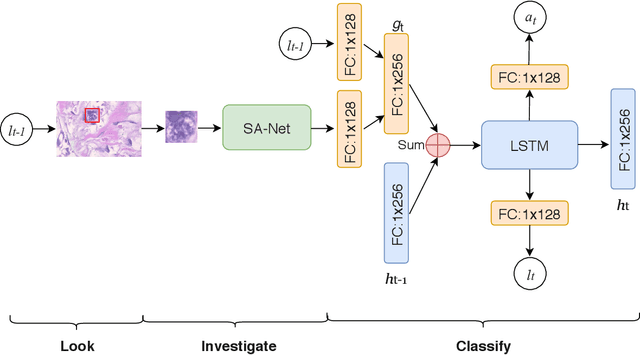
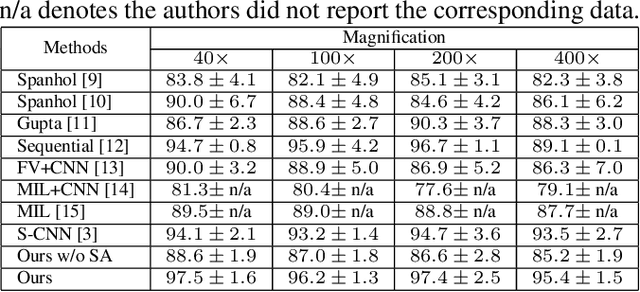
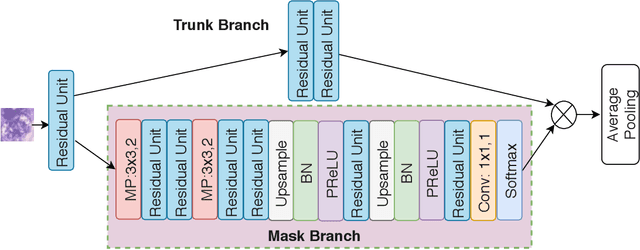
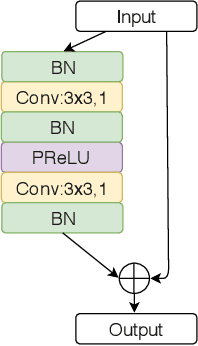
One issue with computer based histopathology image analysis is that the size of the raw image is usually very large. Taking the raw image as input to the deep learning model would be computationally expensive while resizing the raw image to low resolution would incur information loss. In this paper, we present a novel deep hybrid attention approach to breast cancer classification. It first adaptively selects a sequence of coarse regions from the raw image by a hard visual attention algorithm, and then for each such region it is able to investigate the abnormal parts based on a soft-attention mechanism. A recurrent network is then built to make decisions to classify the image region and also to predict the location of the image region to be investigated at the next time step. As the region selection process is non-differentiable, we optimize the whole network through a reinforcement approach to learn an optimal policy to classify the regions. Based on this novel Look, Investigate and Classify approach, we only need to process a fraction of the pixels in the raw image resulting in significant saving in computational resources without sacrificing performances. Our approach is evaluated on a public breast cancer histopathology database, where it demonstrates superior performance to the state-of-the-art deep learning approaches, achieving around 96\% classification accuracy while only 15% of raw pixels are used.
Enhancing Remote Sensing Image Retrieval with Triplet Deep Metric Learning Network
Feb 15, 2019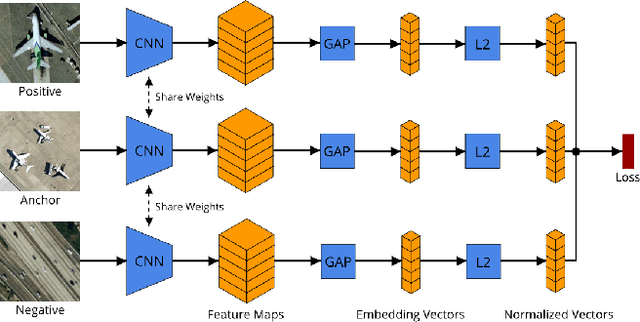

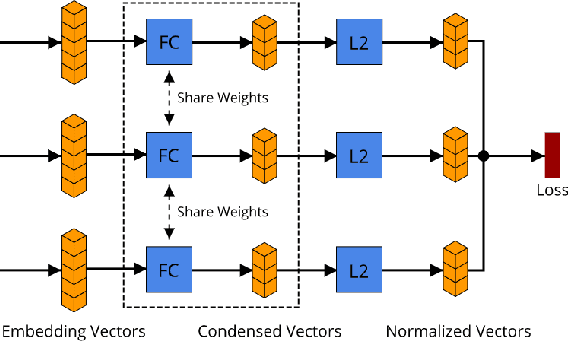
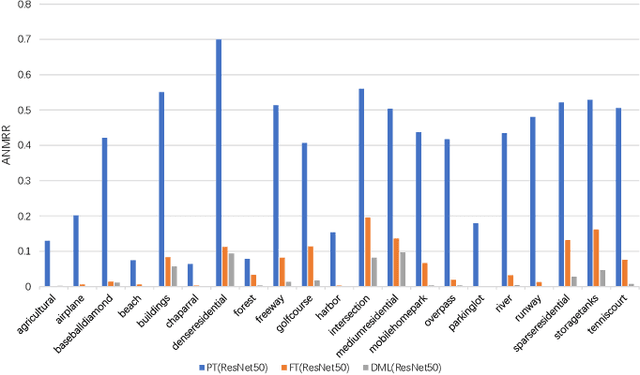
With the rapid growing of remotely sensed imagery data, there is a high demand for effective and efficient image retrieval tools to manage and exploit such data. In this letter, we present a novel content-based remote sensing image retrieval method based on Triplet deep metric learning convolutional neural network (CNN). By constructing a Triplet network with metric learning objective function, we extract the representative features of the images in a semantic space in which images from the same class are close to each other while those from different classes are far apart. In such a semantic space, simple metric measures such as Euclidean distance can be used directly to compare the similarity of images and effectively retrieve images of the same class. We also investigate a supervised and an unsupervised learning methods for reducing the dimensionality of the learned semantic features. We present comprehensive experimental results on two publicly available remote sensing image retrieval datasets and show that our method significantly outperforms state-of-the-art.
Relative Geometry-Aware Siamese Neural Network for 6DOF Camera Relocalization
Jan 21, 2019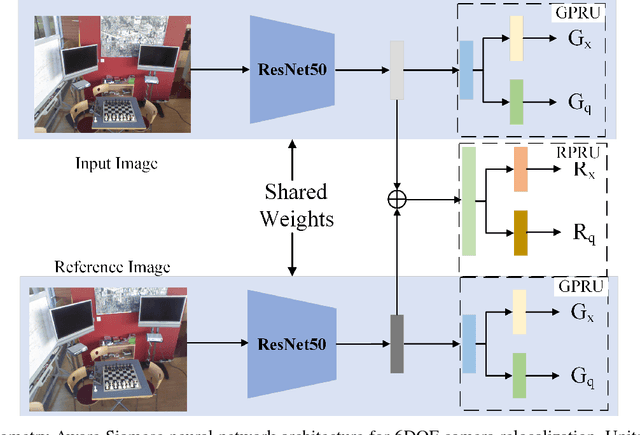
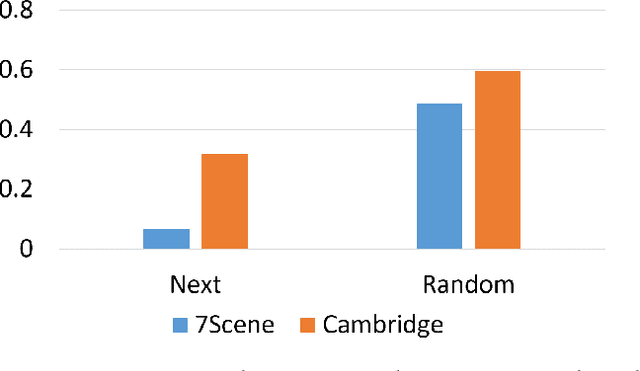
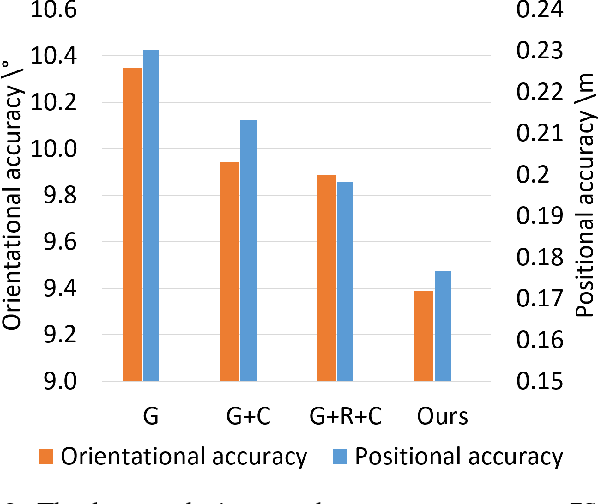
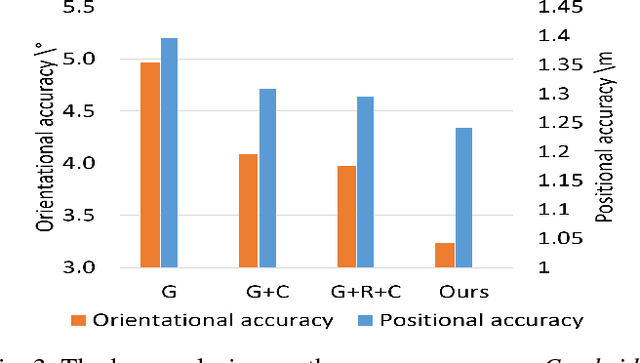
6DOF camera relocalization is an important component of autonomous driving and navigation. Deep learning has recently emerged as a promising technique to tackle this problem. In this paper, we present a novel relative geometry-aware Siamese neural network to enhance the performance of deep learning-based methods through explicitly exploiting the relative geometry constraints between images. We perform multi-task learning and predict the absolute and relative poses simultaneously. We regularize the shared-weight twin networks in both the pose and feature domains to ensure that the estimated poses are globally as well as locally correct. We employ metric learning and design a novel adaptive metric distance loss to learn a feature that is capable of distinguishing poses of visually similar images from different locations. We evaluate the proposed method on public indoor and outdoor benchmarks and the experimental results demonstrate that our method can significantly improve localization performance. Furthermore, extensive ablation evaluations are conducted to demonstrate the effectiveness of different terms of the loss function.