 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDGS: Gradient Domain Gaussian Splatting for Sparse Representation of Radiance Fields
May 08, 2024



The 3D Gaussian splatting methods are getting popular. However, they work directly on the signal, leading to a dense representation of the signal. Even with some techniques such as pruning or distillation, the results are still dense. In this paper, we propose to model the gradient of the original signal. The gradients are much sparser than the original signal. Therefore, the gradients use much less Gaussian splats, leading to the more efficient storage and thus higher computational performance during both training and rendering. Thanks to the sparsity, during the view synthesis, only a small mount of pixels are needed, leading to much higher computational performance ($100\sim 1000\times$ faster). And the 2D image can be recovered from the gradients via solving a Poisson equation with linear computation complexity. Several experiments are performed to confirm the sparseness of the gradients and the computation performance of the proposed method. The method can be applied various applications, such as human body modeling and indoor environment modeling.
EGGS: Edge Guided Gaussian Splatting for Radiance Fields
Apr 14, 2024
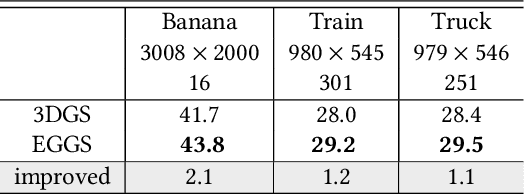
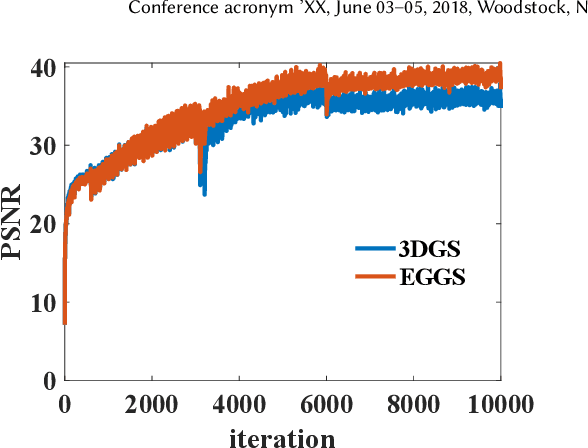
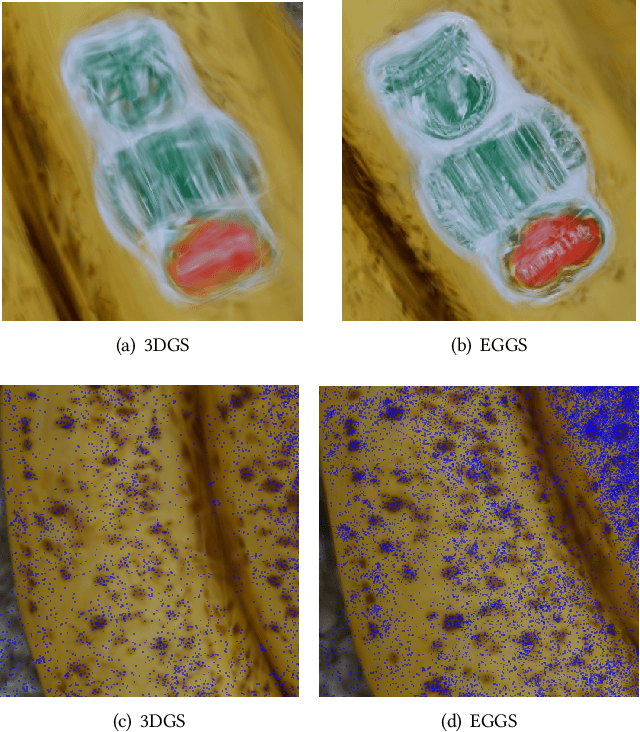
The Gaussian splatting methods are getting popular. However, their loss function only contains the $\ell_1$ norm and the structural similarity between the rendered and input images, without considering the edges in these images. It is well-known that the edges in an image provide important information. Therefore, in this paper, we propose an Edge Guided Gaussian Splatting (EGGS) method that leverages the edges in the input images. More specifically, we give the edge region a higher weight than the flat region. With such edge guidance, the resulting Gaussian particles focus more on the edges instead of the flat regions. Moreover, such edge guidance does not crease the computation cost during the training and rendering stage. The experiments confirm that such simple edge-weighted loss function indeed improves about $1\sim2$ dB on several difference data sets. With simply plugging in the edge guidance, the proposed method can improve all Gaussian splatting methods in different scenarios, such as human head modeling, building 3D reconstruction, etc.
Isotropic Gaussian Splatting for Real-Time Radiance Field Rendering
Mar 21, 2024



The 3D Gaussian splatting method has drawn a lot of attention, thanks to its high performance in training and high quality of the rendered image. However, it uses anisotropic Gaussian kernels to represent the scene. Although such anisotropic kernels have advantages in representing the geometry, they lead to difficulties in terms of computation, such as splitting or merging two kernels. In this paper, we propose to use isotropic Gaussian kernels to avoid such difficulties in the computation, leading to a higher performance method. The experiments confirm that the proposed method is about {\bf 100X} faster without losing the geometry representation accuracy. The proposed method can be applied in a large range applications where the radiance field is needed, such as 3D reconstruction, view synthesis, and dynamic object modeling.
P2I-NET: Mapping Camera Pose to Image via Adversarial Learning for New View Synthesis in Real Indoor Environments
Sep 27, 2023



Given a new $6DoF$ camera pose in an indoor environment, we study the challenging problem of predicting the view from that pose based on a set of reference RGBD views. Existing explicit or implicit 3D geometry construction methods are computationally expensive while those based on learning have predominantly focused on isolated views of object categories with regular geometric structure. Differing from the traditional \textit{render-inpaint} approach to new view synthesis in the real indoor environment, we propose a conditional generative adversarial neural network (P2I-NET) to directly predict the new view from the given pose. P2I-NET learns the conditional distribution of the images of the environment for establishing the correspondence between the camera pose and its view of the environment, and achieves this through a number of innovative designs in its architecture and training lost function. Two auxiliary discriminator constraints are introduced for enforcing the consistency between the pose of the generated image and that of the corresponding real world image in both the latent feature space and the real world pose space. Additionally a deep convolutional neural network (CNN) is introduced to further reinforce this consistency in the pixel space. We have performed extensive new view synthesis experiments on real indoor datasets. Results show that P2I-NET has superior performance against a number of NeRF based strong baseline models. In particular, we show that P2I-NET is 40 to 100 times faster than these competitor techniques while synthesising similar quality images. Furthermore, we contribute a new publicly available indoor environment dataset containing 22 high resolution RGBD videos where each frame also has accurate camera pose parameters.
PLMM: Personal Large Models on Mobile Devices
Sep 26, 2023

Inspired by Federated Learning, in this paper, we propose personal large models that are distilled from traditional large language models but more adaptive to local users' personal information such as education background and hobbies. We classify the large language models into three levels: the personal level, expert level and traditional level. The personal level models are adaptive to users' personal information. They encrypt the users' input and protect their privacy. The expert level models focus on merging specific knowledge such as finance, IT and art. The traditional models focus on the universal knowledge discovery and upgrading the expert models. In such classifications, the personal models directly interact with the user. For the whole system, the personal models have users' (encrypted) personal information. Moreover, such models must be small enough to be performed on personal computers or mobile devices. Finally, they also have to response in real-time for better user experience and produce high quality results. The proposed personal large models can be applied in a wide range of applications such as language and vision tasks.
Gradient Domain Diffusion Models for Image Synthesis
Sep 05, 2023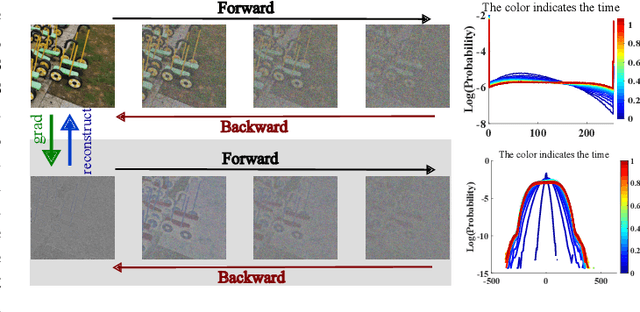
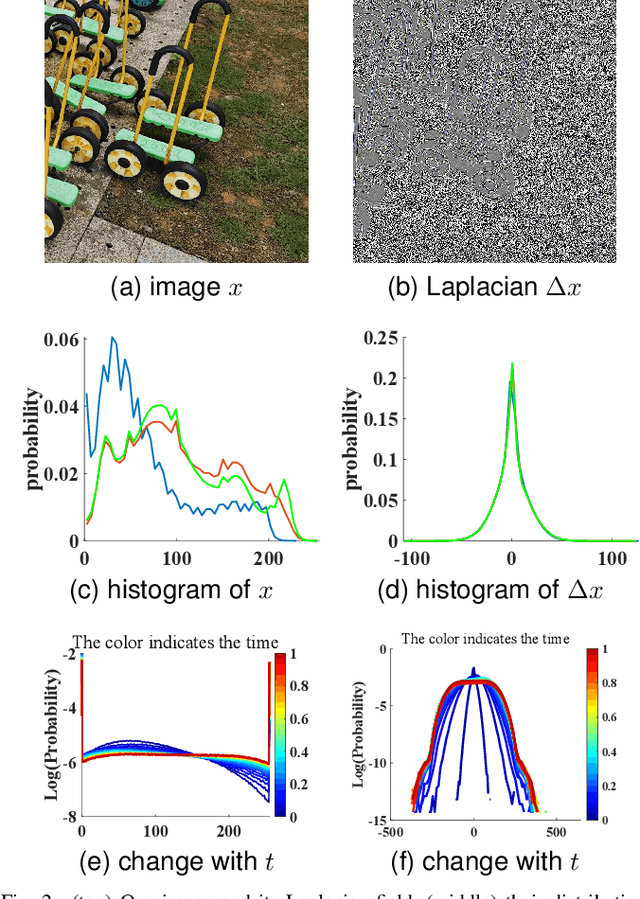
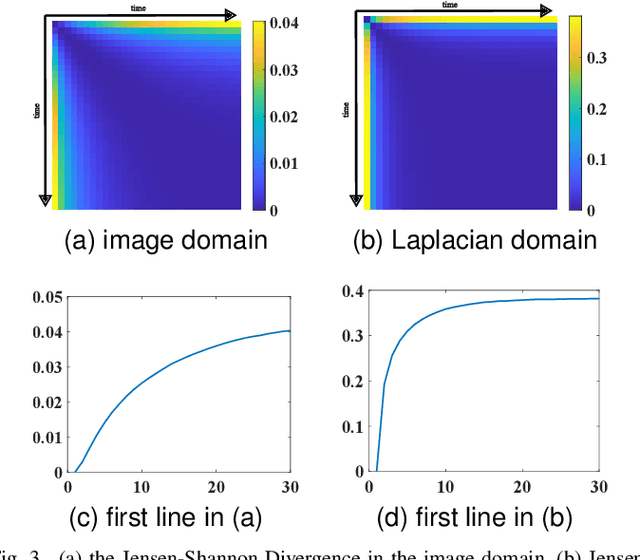
Diffusion models are getting popular in generative image and video synthesis. However, due to the diffusion process, they require a large number of steps to converge. To tackle this issue, in this paper, we propose to perform the diffusion process in the gradient domain, where the convergence becomes faster. There are two reasons. First, thanks to the Poisson equation, the gradient domain is mathematically equivalent to the original image domain. Therefore, each diffusion step in the image domain has a unique corresponding gradient domain representation. Second, the gradient domain is much sparser than the image domain. As a result, gradient domain diffusion models converge faster. Several numerical experiments confirm that the gradient domain diffusion models are more efficient than the original diffusion models. The proposed method can be applied in a wide range of applications such as image processing, computer vision and machine learning tasks.
TSSR: A Truncated and Signed Square Root Activation Function for Neural Networks
Aug 09, 2023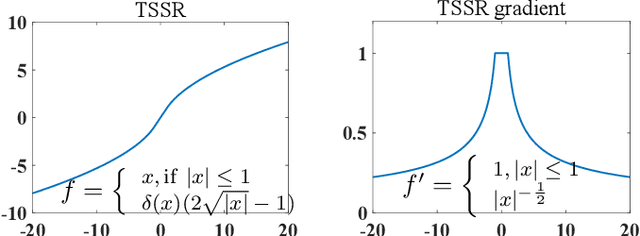
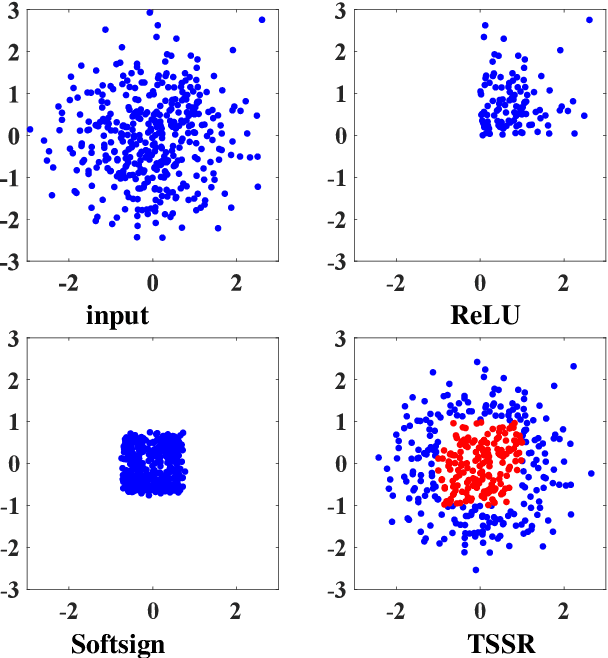
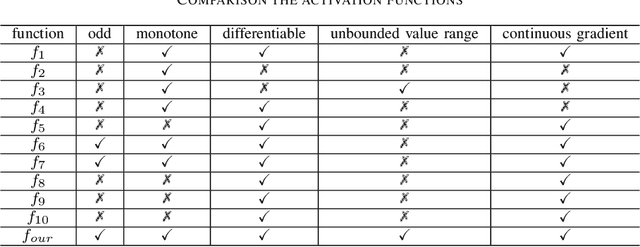
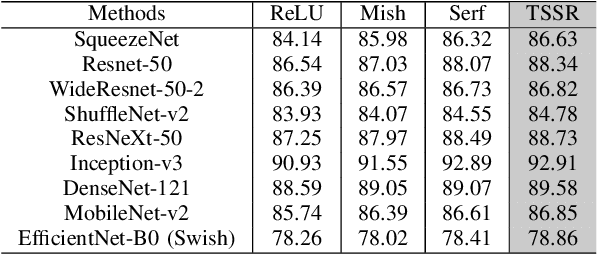
Activation functions are essential components of neural networks. In this paper, we introduce a new activation function called the Truncated and Signed Square Root (TSSR) function. This function is distinctive because it is odd, nonlinear, monotone and differentiable. Its gradient is continuous and always positive. Thanks to these properties, it has the potential to improve the numerical stability of neural networks. Several experiments confirm that the proposed TSSR has better performance than other stat-of-the-art activation functions. The proposed function has significant implications for the development of neural network models and can be applied to a wide range of applications in fields such as computer vision, natural language processing, and speech recognition.
STL: A Signed and Truncated Logarithm Activation Function for Neural Networks
Jul 31, 2023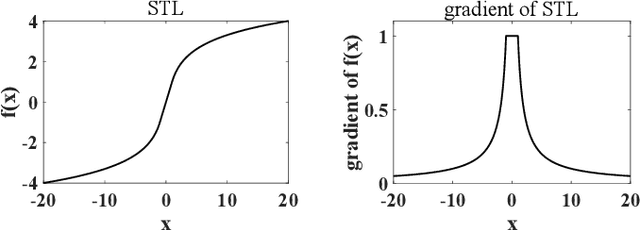
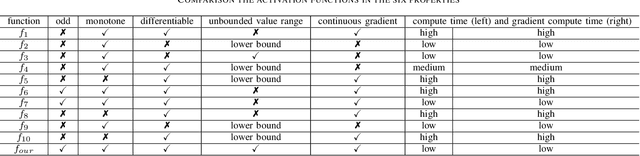
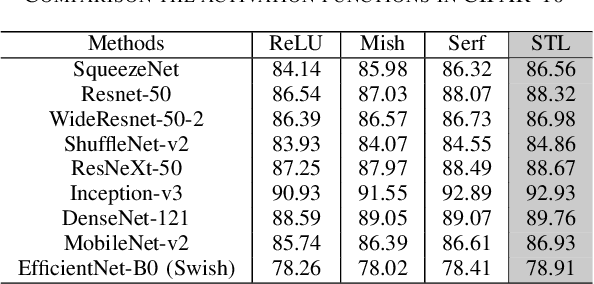
Activation functions play an essential role in neural networks. They provide the non-linearity for the networks. Therefore, their properties are important for neural networks' accuracy and running performance. In this paper, we present a novel signed and truncated logarithm function as activation function. The proposed activation function has significantly better mathematical properties, such as being odd function, monotone, differentiable, having unbounded value range, and a continuous nonzero gradient. These properties make it an excellent choice as an activation function. We compare it with other well-known activation functions in several well-known neural networks. The results confirm that it is the state-of-the-art. The suggested activation function can be applied in a large range of neural networks where activation functions are necessary.
Multilevel Large Language Models for Everyone
Jul 25, 2023

Large language models have made significant progress in the past few years. However, they are either generic {\it or} field specific, splitting the community into different groups. In this paper, we unify these large language models into a larger map, where the generic {\it and} specific models are linked together and can improve each other, based on the user personal input and information from the internet. The idea of linking several large language models together is inspired by the functionality of human brain. The specific regions on the brain cortex are specific for certain low level functionality. And these regions can jointly work together to achieve more complex high level functionality. Such behavior on human brain cortex sheds the light to design the multilevel large language models that contain global level, field level and user level models. The user level models run on local machines to achieve efficient response and protect the user's privacy. Such multilevel models reduce some redundancy and perform better than the single level models. The proposed multilevel idea can be applied in various applications, such as natural language processing, computer vision tasks, professional assistant, business and healthcare.
Dynamic Large Language Models on Blockchains
Jul 20, 2023
Training and deploying the large language models requires a large mount of computational resource because the language models contain billions of parameters and the text has thousands of tokens. Another problem is that the large language models are static. They are fixed after the training process. To tackle these issues, in this paper, we propose to train and deploy the dynamic large language model on blockchains, which have high computation performance and are distributed across a network of computers. A blockchain is a secure, decentralized, and transparent system that allows for the creation of a tamper-proof ledger for transactions without the need for intermediaries. The dynamic large language models can continuously learn from the user input after the training process. Our method provides a new way to develop the large language models and also sheds a light on the next generation artificial intelligence systems.