 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Guided Metric-Aware Temporal Consistency for Monocular Video Human Mesh Recovery
Feb 04, 2026Monocular video human mesh recovery faces fundamental challenges in maintaining metric consistency and temporal stability due to inherent depth ambiguities and scale uncertainties. While existing methods rely primarily on RGB features and temporal smoothing, they struggle with depth ordering, scale drift, and occlusion-induced instabilities. We propose a comprehensive depth-guided framework that achieves metric-aware temporal consistency through three synergistic components: A Depth-Guided Multi-Scale Fusion module that adaptively integrates geometric priors with RGB features via confidence-aware gating; A Depth-guided Metric-Aware Pose and Shape (D-MAPS) estimator that leverages depth-calibrated bone statistics for scale-consistent initialization; A Motion-Depth Aligned Refinement (MoDAR) module that enforces temporal coherence through cross-modal attention between motion dynamics and geometric cues. Our method achieves superior results on three challenging benchmarks, demonstrating significant improvements in robustness against heavy occlusion and spatial accuracy while maintaining computational efficiency.
CLIP-DQA: Blindly Evaluating Dehazed Images from Global and Local Perspectives Using CLIP
Feb 03, 2025Blind dehazed image quality assessment (BDQA), which aims to accurately predict the visual quality of dehazed images without any reference information, is essential for the evaluation, comparison, and optimization of image dehazing algorithms. Existing learning-based BDQA methods have achieved remarkable success, while the small scale of DQA datasets limits their performance. To address this issue, in this paper, we propose to adapt Contrastive Language-Image Pre-Training (CLIP), pre-trained on large-scale image-text pairs, to the BDQA task. Specifically, inspired by the fact that the human visual system understands images based on hierarchical features, we take global and local information of the dehazed image as the input of CLIP. To accurately map the input hierarchical information of dehazed images into the quality score, we tune both the vision branch and language branch of CLIP with prompt learning. Experimental results on two authentic DQA datasets demonstrate that our proposed approach, named CLIP-DQA, achieves more accurate quality predictions over existing BDQA methods. The code is available at https://github.com/JunFu1995/CLIP-DQA.
Enhancing Incomplete Multi-modal Brain Tumor Segmentation with Intra-modal Asymmetry and Inter-modal Dependency
Jun 14, 2024



Deep learning-based brain tumor segmentation (BTS) models for multi-modal MRI images have seen significant advancements in recent years. However, a common problem in practice is the unavailability of some modalities due to varying scanning protocols and patient conditions, making segmentation from incomplete MRI modalities a challenging issue. Previous methods have attempted to address this by fusing accessible multi-modal features, leveraging attention mechanisms, and synthesizing missing modalities using generative models. However, these methods ignore the intrinsic problems of medical image segmentation, such as the limited availability of training samples, particularly for cases with tumors. Furthermore, these methods require training and deploying a specific model for each subset of missing modalities. To address these issues, we propose a novel approach that enhances the BTS model from two perspectives. Firstly, we introduce a pre-training stage that generates a diverse pre-training dataset covering a wide range of different combinations of tumor shapes and brain anatomy. Secondly, we propose a post-training stage that enables the model to reconstruct missing modalities in the prediction results when only partial modalities are available. To achieve the pre-training stage, we conceptually decouple the MRI image into two parts: `anatomy' and `tumor'. We pre-train the BTS model using synthesized data generated from the anatomy and tumor parts across different training samples. ... Extensive experiments demonstrate that our proposed method significantly improves the performance over the baseline and achieves new state-of-the-art results on three brain tumor segmentation datasets: BRATS2020, BRATS2018, and BRATS2015.
Adaptive Mixed-Scale Feature Fusion Network for Blind AI-Generated Image Quality Assessment
Apr 23, 2024With the increasing maturity of the text-to-image and image-to-image generative models, AI-generated images (AGIs) have shown great application potential in advertisement, entertainment, education, social media, etc. Although remarkable advancements have been achieved in generative models, very few efforts have been paid to design relevant quality assessment models. In this paper, we propose a novel blind image quality assessment (IQA) network, named AMFF-Net, for AGIs. AMFF-Net evaluates AGI quality from three dimensions, i.e., "visual quality", "authenticity", and "consistency". Specifically, inspired by the characteristics of the human visual system and motivated by the observation that "visual quality" and "authenticity" are characterized by both local and global aspects, AMFF-Net scales the image up and down and takes the scaled images and original-sized image as the inputs to obtain multi-scale features. After that, an Adaptive Feature Fusion (AFF) block is used to adaptively fuse the multi-scale features with learnable weights. In addition, considering the correlation between the image and prompt, AMFF-Net compares the semantic features from text encoder and image encoder to evaluate the text-to-image alignment. We carry out extensive experiments on three AGI quality assessment databases, and the experimental results show that our AMFF-Net obtains better performance than nine state-of-the-art blind IQA methods. The results of ablation experiments further demonstrate the effectiveness of the proposed multi-scale input strategy and AFF block.
Isotropic Gaussian Splatting for Real-Time Radiance Field Rendering
Mar 21, 2024



The 3D Gaussian splatting method has drawn a lot of attention, thanks to its high performance in training and high quality of the rendered image. However, it uses anisotropic Gaussian kernels to represent the scene. Although such anisotropic kernels have advantages in representing the geometry, they lead to difficulties in terms of computation, such as splitting or merging two kernels. In this paper, we propose to use isotropic Gaussian kernels to avoid such difficulties in the computation, leading to a higher performance method. The experiments confirm that the proposed method is about {\bf 100X} faster without losing the geometry representation accuracy. The proposed method can be applied in a large range applications where the radiance field is needed, such as 3D reconstruction, view synthesis, and dynamic object modeling.
GCFAgg: Global and Cross-view Feature Aggregation for Multi-view Clustering
May 11, 2023Multi-view clustering can partition data samples into their categories by learning a consensus representation in unsupervised way and has received more and more attention in recent years. However, most existing deep clustering methods learn consensus representation or view-specific representations from multiple views via view-wise aggregation way, where they ignore structure relationship of all samples. In this paper, we propose a novel multi-view clustering network to address these problems, called Global and Cross-view Feature Aggregation for Multi-View Clustering (GCFAggMVC). Specifically, the consensus data presentation from multiple views is obtained via cross-sample and cross-view feature aggregation, which fully explores the complementary ofsimilar samples. Moreover, we align the consensus representation and the view-specific representation by the structure-guided contrastive learning module, which makes the view-specific representations from different samples with high structure relationship similar. The proposed module is a flexible multi-view data representation module, which can be also embedded to the incomplete multi-view data clustering task via plugging our module into other frameworks. Extensive experiments show that the proposed method achieves excellent performance in both complete multi-view data clustering tasks and incomplete multi-view data clustering tasks.
Reduced-Reference Quality Assessment of Point Clouds via Content-Oriented Saliency Projection
Jan 18, 2023Many dense 3D point clouds have been exploited to represent visual objects instead of traditional images or videos. To evaluate the perceptual quality of various point clouds, in this letter, we propose a novel and efficient Reduced-Reference quality metric for point clouds, which is based on Content-oriented sAliency Projection (RR-CAP). Specifically, we make the first attempt to simplify reference and distorted point clouds into projected saliency maps with a downsampling operation. Through this process, we tackle the issue of transmitting large-volume original point clouds to user-ends for quality assessment. Then, motivated by the characteristics of the human visual system (HVS), the objective quality scores of distorted point clouds are produced by combining content-oriented similarity and statistical correlation measurements. Finally, extensive experiments are conducted on SJTU-PCQA and WPC databases. The experimental results demonstrate that our proposed algorithm outperforms existing reduced-reference and no-reference quality metrics, and significantly reduces the performance gap between state-of-the-art full-reference quality assessment methods. In addition, we show the performance variation of each proposed technical component by ablation tests.
PSNet: Parallel Symmetric Network for Video Salient Object Detection
Oct 12, 2022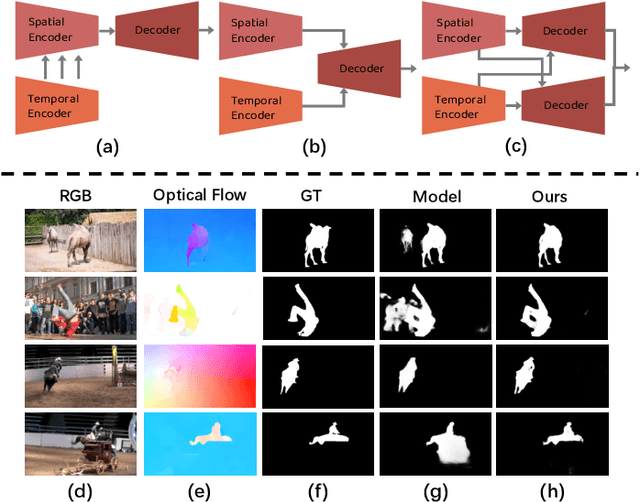
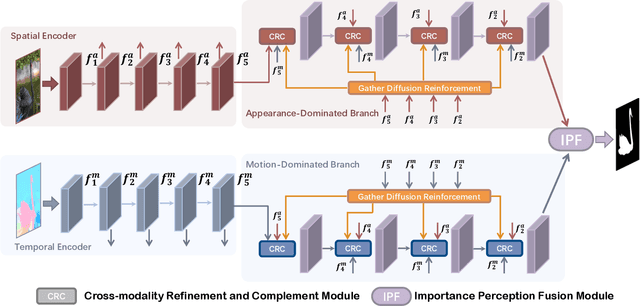
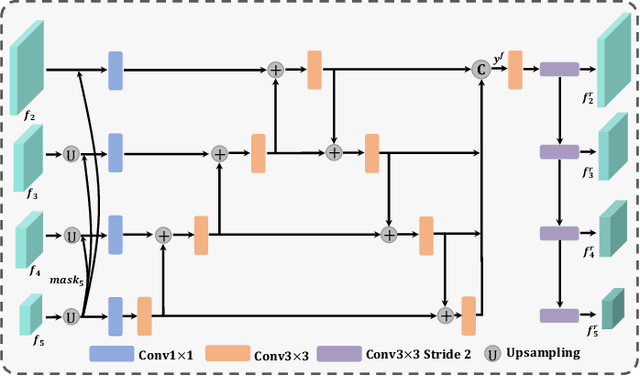
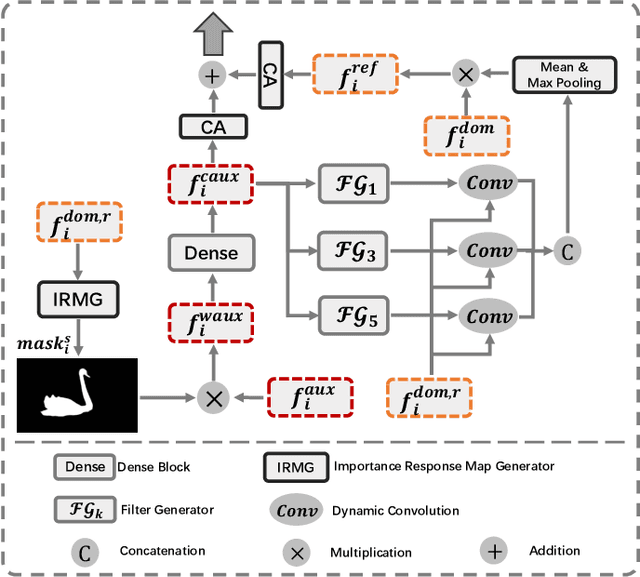
For the video salient object detection (VSOD) task, how to excavate the information from the appearance modality and the motion modality has always been a topic of great concern. The two-stream structure, including an RGB appearance stream and an optical flow motion stream, has been widely used as a typical pipeline for VSOD tasks, but the existing methods usually only use motion features to unidirectionally guide appearance features or adaptively but blindly fuse two modality features. However, these methods underperform in diverse scenarios due to the uncomprehensive and unspecific learning schemes. In this paper, following a more secure modeling philosophy, we deeply investigate the importance of appearance modality and motion modality in a more comprehensive way and propose a VSOD network with up and down parallel symmetry, named PSNet. Two parallel branches with different dominant modalities are set to achieve complete video saliency decoding with the cooperation of the Gather Diffusion Reinforcement (GDR) module and Cross-modality Refinement and Complement (CRC) module. Finally, we use the Importance Perception Fusion (IPF) module to fuse the features from two parallel branches according to their different importance in different scenarios. Experiments on four dataset benchmarks demonstrate that our method achieves desirable and competitive performance.