 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Disentanglement for Full-Reference Image Quality Assessment
Apr 23, 2026Existing deep network-based full-reference image quality assessment (FR-IQA) models typically work by performing pairwise comparisons of deep features from the reference and distorted images. In this paper, we approach this problem from a different perspective and propose a novel FR-IQA paradigm based on causal inference and decoupled representation learning. Unlike typical feature comparison-based FR-IQA models, our approach formulates degradation estimation as a causal disentanglement process guided by intervention on latent representations. We first decouple degradation and content representations by exploiting the content invariance between the reference and distorted images. Second, inspired by the human visual masking effect, we design a masking module to model the causal relationship between image content and degradation features, thereby extracting content-influenced degradation features from distorted images. Finally, quality scores are predicted from these degradation features using either supervised regression or label-free dimensionality reduction. Extensive experiments demonstrate that our method achieves highly competitive performance on standard IQA benchmarks across fully supervised, few-label, and label-free settings. Furthermore, we evaluate the approach on diverse non-standard natural image domains with scarce data, including underwater, radiographic, medical, neutron, and screen-content images. Benefiting from its ability to perform scenario-specific training and prediction without labeled IQA data, our method exhibits superior cross-domain generalization compared to existing training-free FR-IQA models.
Spatio-Temporal Attention Enhanced Multi-Agent DRL for UAV-Assisted Wireless Networks with Limited Communications
Mar 23, 2026In this paper, we employ multiple UAVs to accelerate data transmissions from ground users (GUs) to a remote base station (BS) via the UAVs' relay communications. The UAVs' intermittent information exchanges typically result in delays in acquiring the complete system state and hinder their effective collaboration. To maximize the overall throughput, we first propose a delay-tolerant multi-agent deep reinforcement learning (MADRL) algorithm that integrates a delay-penalized reward to encourage information sharing among UAVs, while jointly optimizing the UAVs' trajectory planning, network formation, and transmission control strategies. Additionally, considering information loss due to unreliable channel conditions, we further propose a spatio-temporal attention based prediction approach to recover the lost information and enhance each UAV's awareness of the network state. These two designs are envisioned to enhance the network capacity in UAV-assisted wireless networks with limited communications. The simulation results reveal that our new approach achieves over 50\% reduction in information delay and 75% throughput gain compared to the conventional MADRL. Interestingly, it is shown that improving the UAVs' information sharing will not sacrifice the network capacity. Instead, it significantly improves the learning performance and throughput simultaneously. It is also effective in reducing the need for UAVs' information exchange and thus fostering practical deployment of MADRL in UAV-assisted wireless networks.
From Global to Granular: Revealing IQA Model Performance via Correlation Surface
Jan 29, 2026Evaluation of Image Quality Assessment (IQA) models has long been dominated by global correlation metrics, such as Pearson Linear Correlation Coefficient (PLCC) and Spearman Rank-Order Correlation Coefficient (SRCC). While widely adopted, these metrics reduce performance to a single scalar, failing to capture how ranking consistency varies across the local quality spectrum. For example, two IQA models may achieve identical SRCC values, yet one ranks high-quality images (related to high Mean Opinion Score, MOS) more reliably, while the other better discriminates image pairs with small quality/MOS differences (related to $|Δ$MOS$|$). Such complementary behaviors are invisible under global metrics. Moreover, SRCC and PLCC are sensitive to test-sample quality distributions, yielding unstable comparisons across test sets. To address these limitations, we propose \textbf{Granularity-Modulated Correlation (GMC)}, which provides a structured, fine-grained analysis of IQA performance. GMC includes: (1) a \textbf{Granularity Modulator} that applies Gaussian-weighted correlations conditioned on absolute MOS values and pairwise MOS differences ($|Δ$MOS$|$) to examine local performance variations, and (2) a \textbf{Distribution Regulator} that regularizes correlations to mitigate biases from non-uniform quality distributions. The resulting \textbf{correlation surface} maps correlation values as a joint function of MOS and $|Δ$MOS$|$, providing a 3D representation of IQA performance. Experiments on standard benchmarks show that GMC reveals performance characteristics invisible to scalar metrics, offering a more informative and reliable paradigm for analyzing, comparing, and deploying IQA models. Codes are available at https://github.com/Dniaaa/GMC.
Towards Realistic Low-Light Image Enhancement via ISP Driven Data Modeling
Apr 16, 2025
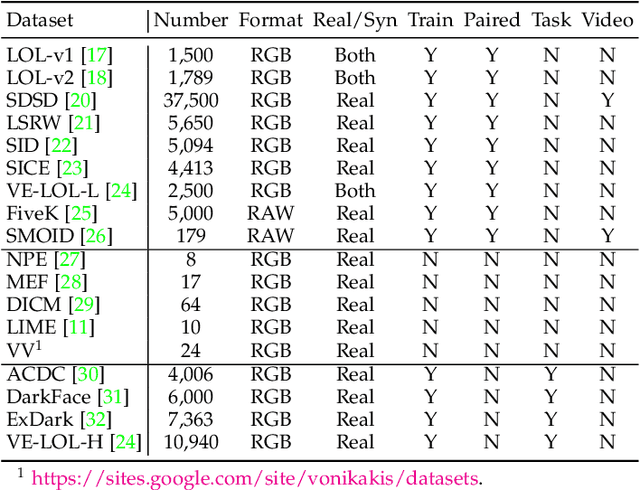
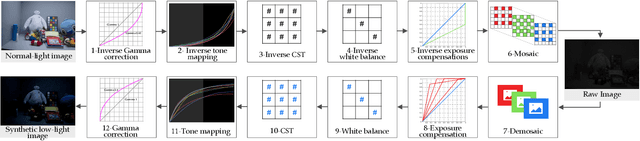
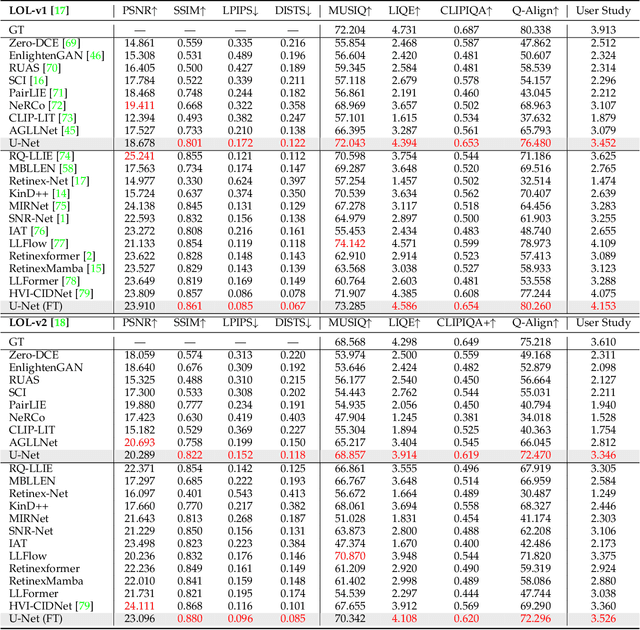
Deep neural networks (DNNs) have recently become the leading method for low-light image enhancement (LLIE). However, despite significant progress, their outputs may still exhibit issues such as amplified noise, incorrect white balance, or unnatural enhancements when deployed in real world applications. A key challenge is the lack of diverse, large scale training data that captures the complexities of low-light conditions and imaging pipelines. In this paper, we propose a novel image signal processing (ISP) driven data synthesis pipeline that addresses these challenges by generating unlimited paired training data. Specifically, our pipeline begins with easily collected high-quality normal-light images, which are first unprocessed into the RAW format using a reverse ISP. We then synthesize low-light degradations directly in the RAW domain. The resulting data is subsequently processed through a series of ISP stages, including white balance adjustment, color space conversion, tone mapping, and gamma correction, with controlled variations introduced at each stage. This broadens the degradation space and enhances the diversity of the training data, enabling the generated data to capture a wide range of degradations and the complexities inherent in the ISP pipeline. To demonstrate the effectiveness of our synthetic pipeline, we conduct extensive experiments using a vanilla UNet model consisting solely of convolutional layers, group normalization, GeLU activation, and convolutional block attention modules (CBAMs). Extensive testing across multiple datasets reveals that the vanilla UNet model trained with our data synthesis pipeline delivers high fidelity, visually appealing enhancement results, surpassing state-of-the-art (SOTA) methods both quantitatively and qualitatively.
Recurrent Feature Mining and Keypoint Mixup Padding for Category-Agnostic Pose Estimation
Mar 27, 2025



Category-agnostic pose estimation aims to locate keypoints on query images according to a few annotated support images for arbitrary novel classes. Existing methods generally extract support features via heatmap pooling, and obtain interacted features from support and query via cross-attention. Hence, these works neglect to mine fine-grained and structure-aware (FGSA) features from both support and query images, which are crucial for pixel-level keypoint localization. To this end, we propose a novel yet concise framework, which recurrently mines FGSA features from both support and query images. Specifically, we design a FGSA mining module based on deformable attention mechanism. On the one hand, we mine fine-grained features by applying deformable attention head over multi-scale feature maps. On the other hand, we mine structure-aware features by offsetting the reference points of keypoints to their linked keypoints. By means of above module, we recurrently mine FGSA features from support and query images, and thus obtain better support features and query estimations. In addition, we propose to use mixup keypoints to pad various classes to a unified keypoint number, which could provide richer supervision than the zero padding used in existing works. We conduct extensive experiments and in-depth studies on large-scale MP-100 dataset, and outperform SOTA method dramatically (+3.2\%PCK@0.05). Code is avaiable at https://github.com/chenbys/FMMP.
Diffusion-based Facial Aesthetics Enhancement with 3D Structure Guidance
Mar 18, 2025Facial Aesthetics Enhancement (FAE) aims to improve facial attractiveness by adjusting the structure and appearance of a facial image while preserving its identity as much as possible. Most existing methods adopted deep feature-based or score-based guidance for generation models to conduct FAE. Although these methods achieved promising results, they potentially produced excessively beautified results with lower identity consistency or insufficiently improved facial attractiveness. To enhance facial aesthetics with less loss of identity, we propose the Nearest Neighbor Structure Guidance based on Diffusion (NNSG-Diffusion), a diffusion-based FAE method that beautifies a 2D facial image with 3D structure guidance. Specifically, we propose to extract FAE guidance from a nearest neighbor reference face. To allow for less change of facial structures in the FAE process, a 3D face model is recovered by referring to both the matched 2D reference face and the 2D input face, so that the depth and contour guidance can be extracted from the 3D face model. Then the depth and contour clues can provide effective guidance to Stable Diffusion with ControlNet for FAE. Extensive experiments demonstrate that our method is superior to previous relevant methods in enhancing facial aesthetics while preserving facial identity.
Viewport-Unaware Blind Omnidirectional Image Quality Assessment: A Flexible and Effective Paradigm
Mar 08, 2025Most of existing blind omnidirectional image quality assessment (BOIQA) models rely on viewport generation by modeling user viewing behavior or transforming omnidirectional images (OIs) into varying formats; however, these methods are either computationally expensive or less scalable. To solve these issues, in this paper, we present a flexible and effective paradigm, which is viewport-unaware and can be easily adapted to 2D plane image quality assessment (2D-IQA). Specifically, the proposed BOIQA model includes an adaptive prior-equator sampling module for extracting a patch sequence from the equirectangular projection (ERP) image in a resolution-agnostic manner, a progressive deformation-unaware feature fusion module which is able to capture patch-wise quality degradation in a deformation-immune way, and a local-to-global quality aggregation module to adaptively map local perception to global quality. Extensive experiments across four OIQA databases (including uniformly distorted OIs and non-uniformly distorted OIs) demonstrate that the proposed model achieves competitive performance with low complexity against other state-of-the-art models, and we also verify its adaptive capacity to 2D-IQA.
Computational Analysis of Degradation Modeling in Blind Panoramic Image Quality Assessment
Mar 05, 2025



Blind panoramic image quality assessment (BPIQA) has recently brought new challenge to the visual quality community, due to the complex interaction between immersive content and human behavior. Although many efforts have been made to advance BPIQA from both conducting psychophysical experiments and designing performance-driven objective algorithms, \textit{limited content} and \textit{few samples} in those closed sets inevitably would result in shaky conclusions, thereby hindering the development of BPIQA, we refer to it as the \textit{easy-database} issue. In this paper, we present a sufficient computational analysis of degradation modeling in BPIQA to thoroughly explore the \textit{easy-database issue}, where we carefully design three types of experiments via investigating the gap between BPIQA and blind image quality assessment (BIQA), the necessity of specific design in BPIQA models, and the generalization ability of BPIQA models. From extensive experiments, we find that easy databases narrow the gap between the performance of BPIQA and BIQA models, which is unconducive to the development of BPIQA. And the easy databases make the BPIQA models be closed to saturation, therefore the effectiveness of the associated specific designs can not be well verified. Besides, the BPIQA models trained on our recently proposed databases with complicated degradation show better generalization ability. Thus, we believe that much more efforts are highly desired to put into BPIQA from both subjective viewpoint and objective viewpoint.
Max360IQ: Blind Omnidirectional Image Quality Assessment with Multi-axis Attention
Feb 26, 2025Omnidirectional image, also called 360-degree image, is able to capture the entire 360-degree scene, thereby providing more realistic immersive feelings for users than general 2D image and stereoscopic image. Meanwhile, this feature brings great challenges to measuring the perceptual quality of omnidirectional images, which is closely related to users' quality of experience, especially when the omnidirectional images suffer from non-uniform distortion. In this paper, we propose a novel and effective blind omnidirectional image quality assessment (BOIQA) model with multi-axis attention (Max360IQ), which can proficiently measure not only the quality of uniformly distorted omnidirectional images but also the quality of non-uniformly distorted omnidirectional images. Specifically, the proposed Max360IQ is mainly composed of a backbone with stacked multi-axis attention modules for capturing both global and local spatial interactions of extracted viewports, a multi-scale feature integration (MSFI) module to fuse multi-scale features and a quality regression module with deep semantic guidance for predicting the quality of omnidirectional images. Experimental results demonstrate that the proposed Max360IQ outperforms the state-of-the-art Assessor360 by 3.6\% in terms of SRCC on the JUFE database with non-uniform distortion, and gains improvement of 0.4\% and 0.8\% in terms of SRCC on the OIQA and CVIQ databases, respectively. The source code is available at https://github.com/WenJuing/Max360IQ.
Omnidirectional Image Quality Captioning: A Large-scale Database and A New Model
Feb 21, 2025



The fast growing application of omnidirectional images calls for effective approaches for omnidirectional image quality assessment (OIQA). Existing OIQA methods have been developed and tested on homogeneously distorted omnidirectional images, but it is hard to transfer their success directly to the heterogeneously distorted omnidirectional images. In this paper, we conduct the largest study so far on OIQA, where we establish a large-scale database called OIQ-10K containing 10,000 omnidirectional images with both homogeneous and heterogeneous distortions. A comprehensive psychophysical study is elaborated to collect human opinions for each omnidirectional image, together with the spatial distributions (within local regions or globally) of distortions, and the head and eye movements of the subjects. Furthermore, we propose a novel multitask-derived adaptive feature-tailoring OIQA model named IQCaption360, which is capable of generating a quality caption for an omnidirectional image in a manner of textual template. Extensive experiments demonstrate the effectiveness of IQCaption360, which outperforms state-of-the-art methods by a significant margin on the proposed OIQ-10K database. The OIQ-10K database and the related source codes are available at https://github.com/WenJuing/IQCaption360.