 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-based Facial Aesthetics Enhancement with 3D Structure Guidance
Mar 18, 2025Facial Aesthetics Enhancement (FAE) aims to improve facial attractiveness by adjusting the structure and appearance of a facial image while preserving its identity as much as possible. Most existing methods adopted deep feature-based or score-based guidance for generation models to conduct FAE. Although these methods achieved promising results, they potentially produced excessively beautified results with lower identity consistency or insufficiently improved facial attractiveness. To enhance facial aesthetics with less loss of identity, we propose the Nearest Neighbor Structure Guidance based on Diffusion (NNSG-Diffusion), a diffusion-based FAE method that beautifies a 2D facial image with 3D structure guidance. Specifically, we propose to extract FAE guidance from a nearest neighbor reference face. To allow for less change of facial structures in the FAE process, a 3D face model is recovered by referring to both the matched 2D reference face and the 2D input face, so that the depth and contour guidance can be extracted from the 3D face model. Then the depth and contour clues can provide effective guidance to Stable Diffusion with ControlNet for FAE. Extensive experiments demonstrate that our method is superior to previous relevant methods in enhancing facial aesthetics while preserving facial identity.
Label Structure Preserving Contrastive Embedding for Multi-Label Learning with Missing Labels
Sep 03, 2022



Contrastive learning (CL) has shown impressive advances in image representation learning in whichever supervised multi-class classification or unsupervised learning. However, these CL methods fail to be directly adapted to multi-label image classification due to the difficulty in defining the positive and negative instances to contrast a given anchor image in multi-label scenario, let the label missing one alone, implying that borrowing a commonly-used way from contrastive multi-class learning to define them will incur a lot of false negative instances unfavorable for learning. In this paper, with the introduction of a label correction mechanism to identify missing labels, we first elegantly generate positives and negatives for individual semantic labels of an anchor image, then define a unique contrastive loss for multi-label image classification with missing labels (CLML), the loss is able to accurately bring images close to their true positive images and false negative images, far away from their true negative images. Different from existing multi-label CL losses, CLML also preserves low-rank global and local label dependencies in the latent representation space where such dependencies have been shown to be helpful in dealing with missing labels. To the best of our knowledge, this is the first general multi-label CL loss in the missing-label scenario and thus can seamlessly be paired with those losses of any existing multi-label learning methods just via a single hyperparameter. The proposed strategy has been shown to improve the classification performance of the Resnet101 model by margins of 1.2%, 1.6%, and 1.3% respectively on three standard datasets, MSCOCO, VOC, and NUS-WIDE. Code is available at https://github.com/chuangua/ContrastiveLossMLML.
Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization
Jun 18, 2018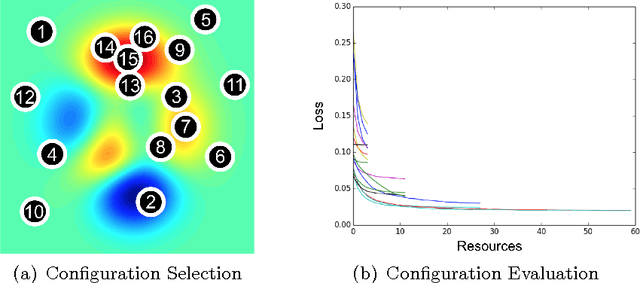



Performance of machine learning algorithms depends critically on identifying a good set of hyperparameters. While recent approaches use Bayesian optimization to adaptively select configurations, we focus on speeding up random search through adaptive resource allocation and early-stopping. We formulate hyperparameter optimization as a pure-exploration non-stochastic infinite-armed bandit problem where a predefined resource like iterations, data samples, or features is allocated to randomly sampled configurations. We introduce a novel algorithm, Hyperband, for this framework and analyze its theoretical properties, providing several desirable guarantees. Furthermore, we compare Hyperband with popular Bayesian optimization methods on a suite of hyperparameter optimization problems. We observe that Hyperband can provide over an order-of-magnitude speedup over our competitor set on a variety of deep-learning and kernel-based learning problems.
* Changes: - Updated to JMLR version