 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Structure Preserving Contrastive Embedding for Multi-Label Learning with Missing Labels
Sep 03, 2022



Contrastive learning (CL) has shown impressive advances in image representation learning in whichever supervised multi-class classification or unsupervised learning. However, these CL methods fail to be directly adapted to multi-label image classification due to the difficulty in defining the positive and negative instances to contrast a given anchor image in multi-label scenario, let the label missing one alone, implying that borrowing a commonly-used way from contrastive multi-class learning to define them will incur a lot of false negative instances unfavorable for learning. In this paper, with the introduction of a label correction mechanism to identify missing labels, we first elegantly generate positives and negatives for individual semantic labels of an anchor image, then define a unique contrastive loss for multi-label image classification with missing labels (CLML), the loss is able to accurately bring images close to their true positive images and false negative images, far away from their true negative images. Different from existing multi-label CL losses, CLML also preserves low-rank global and local label dependencies in the latent representation space where such dependencies have been shown to be helpful in dealing with missing labels. To the best of our knowledge, this is the first general multi-label CL loss in the missing-label scenario and thus can seamlessly be paired with those losses of any existing multi-label learning methods just via a single hyperparameter. The proposed strategy has been shown to improve the classification performance of the Resnet101 model by margins of 1.2%, 1.6%, and 1.3% respectively on three standard datasets, MSCOCO, VOC, and NUS-WIDE. Code is available at https://github.com/chuangua/ContrastiveLossMLML.
Learning from Positive and Unlabeled Data with Augmented Classes
Jul 27, 2022
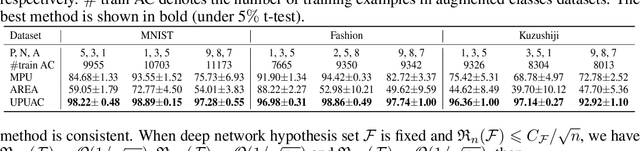
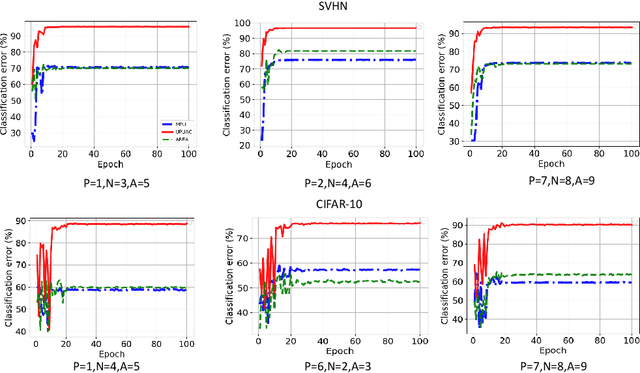
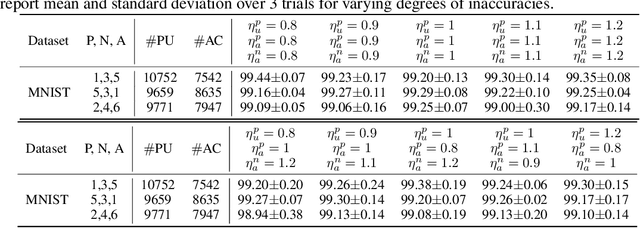
Positive Unlabeled (PU) learning aims to learn a binary classifier from only positive and unlabeled data, which is utilized in many real-world scenarios. However, existing PU learning algorithms cannot deal with the real-world challenge in an open and changing scenario, where examples from unobserved augmented classes may emerge in the testing phase. In this paper, we propose an unbiased risk estimator for PU learning with Augmented Classes (PUAC) by utilizing unlabeled data from the augmented classes distribution, which can be easily collected in many real-world scenarios. Besides, we derive the estimation error bound for the proposed estimator, which provides a theoretical guarantee for its convergence to the optimal solution. Experiments on multiple realistic datasets demonstrate the effectiveness of proposed approach.
A Similarity-based Framework for Classification Task
Mar 05, 2022
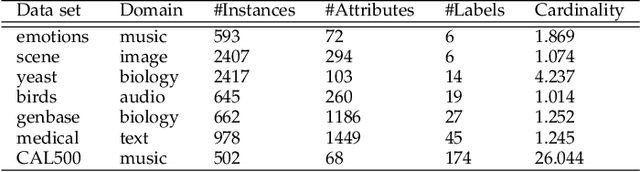
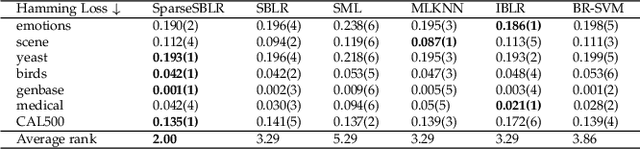
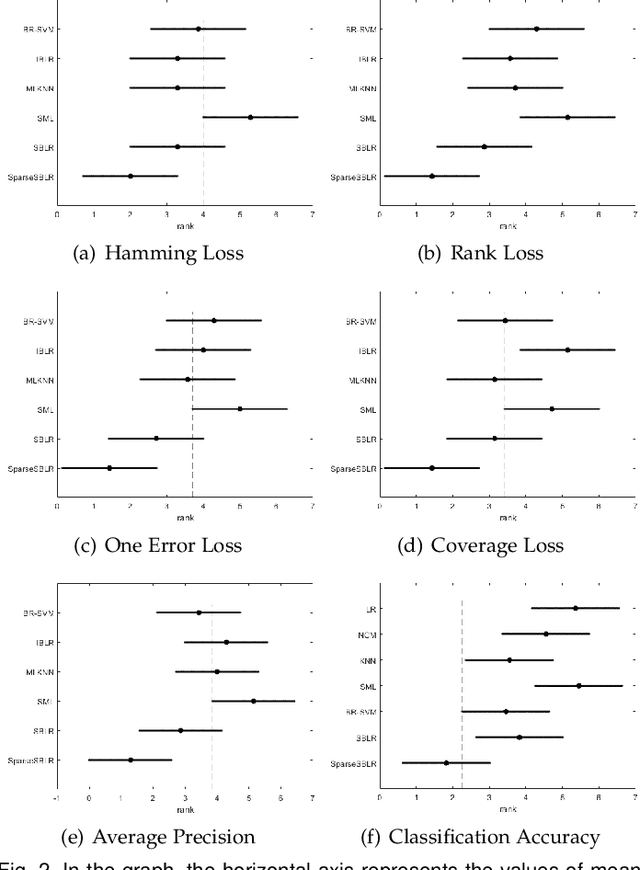
Similarity-based method gives rise to a new class of methods for multi-label learning and also achieves promising performance. In this paper, we generalize this method, resulting in a new framework for classification task. Specifically, we unite similarity-based learning and generalized linear models to achieve the best of both worlds. This allows us to capture interdependencies between classes and prevent from impairing performance of noisy classes. Each learned parameter of the model can reveal the contribution of one class to another, providing interpretability to some extent. Experiment results show the effectiveness of the proposed approach on multi-class and multi-label datasets
Global Expanding, Local Shrinking: Discriminant Multi-label Learning with Missing Labels
Apr 08, 2020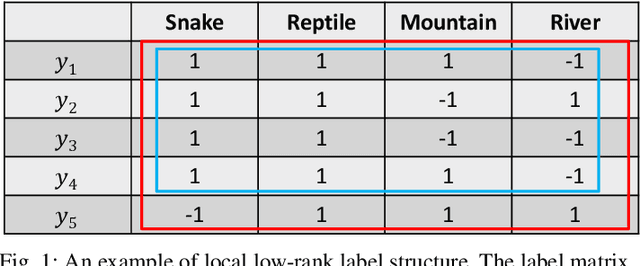
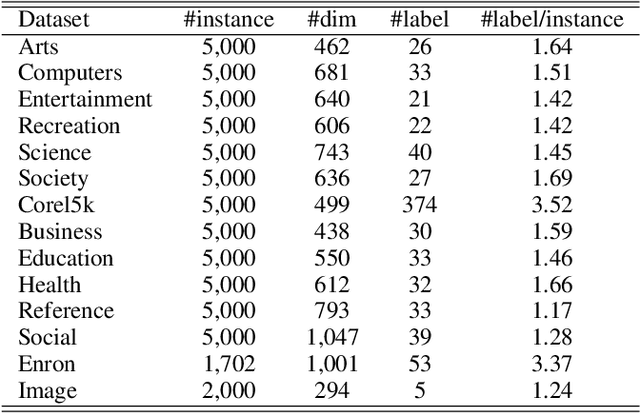
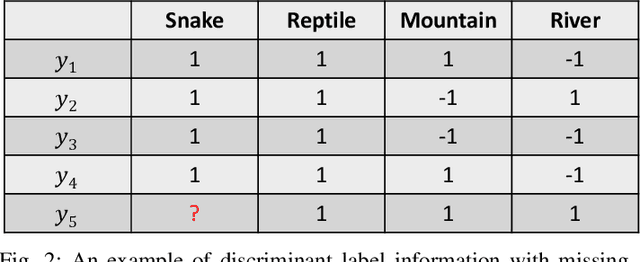

In multi-label learning, the issue of missing labels brings a major challenge. Many methods attempt to recovery missing labels by exploiting low-rank structure of label matrix. However, these methods just utilize global low-rank label structure, ignore both local low-rank label structures and label discriminant information to some extent, leaving room for further performance improvement. In this paper, we develop a simple yet effective discriminant multi-label learning (DM2L) method for multi-label learning with missing labels. Specifically, we impose the low-rank structures on all the predictions of instances from the same labels (local shrinking of rank), and a maximally separated structure (high-rank structure) on the predictions of instances from different labels (global expanding of rank). In this way, these imposed low-rank structures can help modeling both local and global low-rank label structures, while the imposed high-rank structure can help providing more underlying discriminability. Our subsequent theoretical analysis also supports these intuitions. In addition, we provide a nonlinear extension via using kernel trick to enhance DM2L and establish a concave-convex objective to learn these models. Compared to the other methods, our method involves the fewest assumptions and only one hyper-parameter. Even so, extensive experiments show that our method still outperforms the state-of-the-art methods.