 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Wavelet-Based Structural Priors for Controlled Diffusion in Whole-Body Low-Dose PET Denoising
Jan 11, 2026Low-dose Positron Emission Tomography (PET) imaging reduces patient radiation exposure but suffers from increased noise that degrades image quality and diagnostic reliability. Although diffusion models have demonstrated strong denoising capability, their stochastic nature makes it challenging to enforce anatomically consistent structures, particularly in low signal-to-noise regimes and volumetric whole-body imaging. We propose Wavelet-Conditioned ControlNet (WCC-Net), a fully 3D diffusion-based framework that introduces explicit frequency-domain structural priors via wavelet representations to guide volumetric PET denoising. By injecting wavelet-based structural guidance into a frozen pretrained diffusion backbone through a lightweight control branch, WCC-Net decouples anatomical structure from noise while preserving generative expressiveness and 3D structural continuity. Extensive experiments demonstrate that WCC-Net consistently outperforms CNN-, GAN-, and diffusion-based baselines. On the internal 1/20-dose test set, WCC-Net improves PSNR by +1.21 dB and SSIM by +0.008 over a strong diffusion baseline, while reducing structural distortion (GMSD) and intensity error (NMAE). Moreover, WCC-Net generalizes robustly to unseen dose levels (1/50 and 1/4), achieving superior quantitative performance and improved volumetric anatomical consistency.
Decoupling Multi-Contrast Super-Resolution: Pairing Unpaired Synthesis with Implicit Representations
May 09, 2025Magnetic Resonance Imaging (MRI) is critical for clinical diagnostics but is often limited by long acquisition times and low signal-to-noise ratios, especially in modalities like diffusion and functional MRI. The multi-contrast nature of MRI presents a valuable opportunity for cross-modal enhancement, where high-resolution (HR) modalities can serve as references to boost the quality of their low-resolution (LR) counterparts-motivating the development of Multi-Contrast Super-Resolution (MCSR) techniques. Prior work has shown that leveraging complementary contrasts can improve SR performance; however, effective feature extraction and fusion across modalities with varying resolutions remains a major challenge. Moreover, existing MCSR methods often assume fixed resolution settings and all require large, perfectly paired training datasets-conditions rarely met in real-world clinical environments. To address these challenges, we propose a novel Modular Multi-Contrast Super-Resolution (MCSR) framework that eliminates the need for paired training data and supports arbitrary upscaling. Our method decouples the MCSR task into two stages: (1) Unpaired Cross-Modal Synthesis (U-CMS), which translates a high-resolution reference modality into a synthesized version of the target contrast, and (2) Unsupervised Super-Resolution (U-SR), which reconstructs the final output using implicit neural representations (INRs) conditioned on spatial coordinates. This design enables scale-agnostic and anatomically faithful reconstruction by bridging un-paired cross-modal synthesis with unsupervised resolution enhancement. Experiments show that our method achieves superior performance at 4x and 8x upscaling, with improved fidelity and anatomical consistency over existing baselines. Our framework demonstrates strong potential for scalable, subject-specific, and data-efficient MCSR in real-world clinical settings.
CT-SDM: A Sampling Diffusion Model for Sparse-View CT Reconstruction across All Sampling Rates
Sep 03, 2024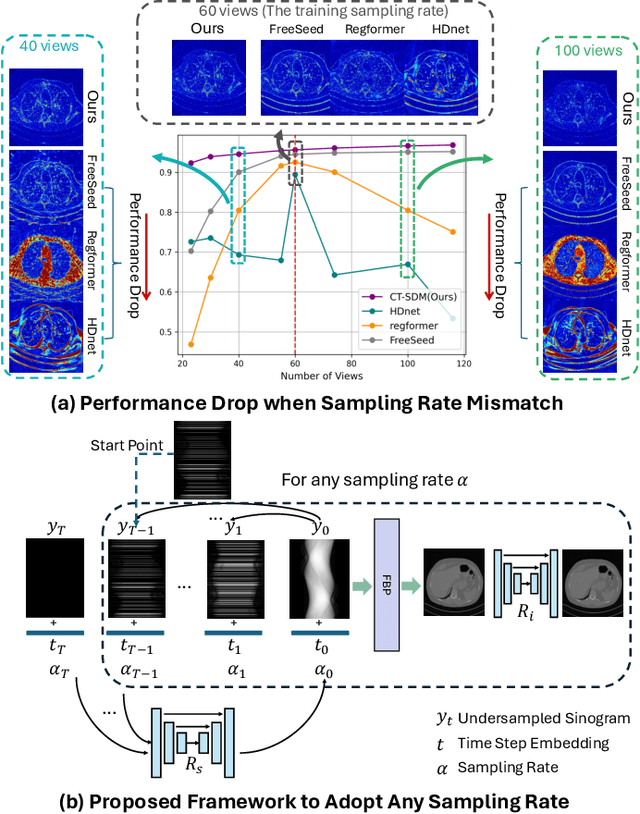



Sparse views X-ray computed tomography has emerged as a contemporary technique to mitigate radiation dose. Because of the reduced number of projection views, traditional reconstruction methods can lead to severe artifacts. Recently, research studies utilizing deep learning methods has made promising progress in removing artifacts for Sparse-View Computed Tomography (SVCT). However, given the limitations on the generalization capability of deep learning models, current methods usually train models on fixed sampling rates, affecting the usability and flexibility of model deployment in real clinical settings. To address this issue, our study proposes a adaptive reconstruction method to achieve high-performance SVCT reconstruction at any sampling rate. Specifically, we design a novel imaging degradation operator in the proposed sampling diffusion model for SVCT (CT-SDM) to simulate the projection process in the sinogram domain. Thus, the CT-SDM can gradually add projection views to highly undersampled measurements to generalize the full-view sinograms. By choosing an appropriate starting point in diffusion inference, the proposed model can recover the full-view sinograms from any sampling rate with only one trained model. Experiments on several datasets have verified the effectiveness and robustness of our approach, demonstrating its superiority in reconstructing high-quality images from sparse-view CT scans across various sampling rates.
Learning Task-Specific Sampling Strategy for Sparse-View CT Reconstruction
Sep 03, 2024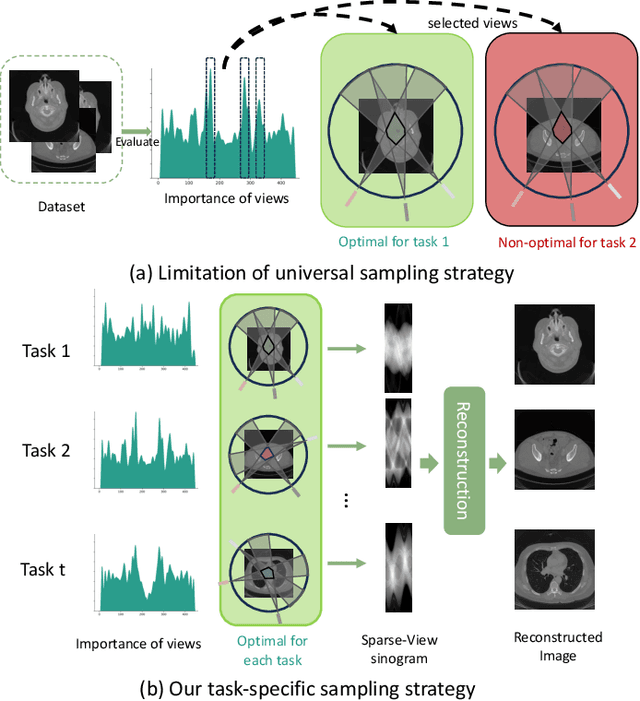
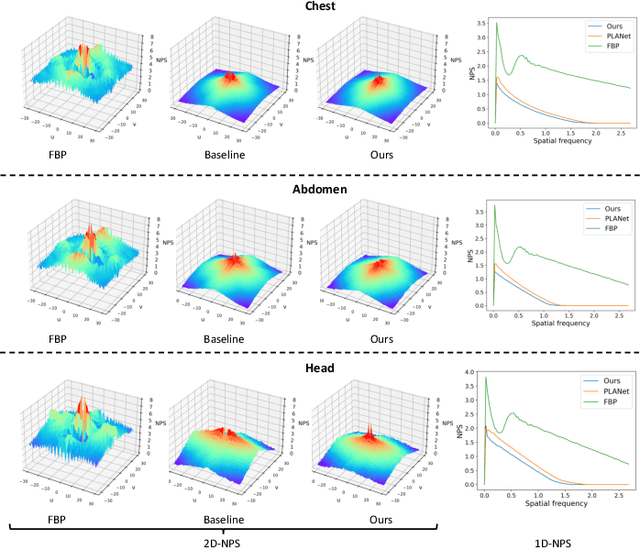

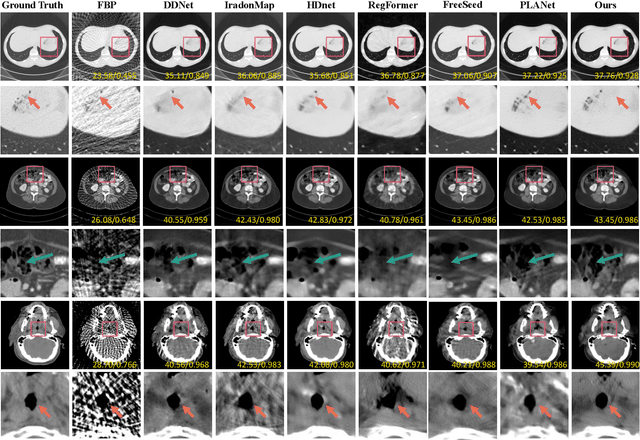
Sparse-View Computed Tomography (SVCT) offers low-dose and fast imaging but suffers from severe artifacts. Optimizing the sampling strategy is an essential approach to improving the imaging quality of SVCT. However, current methods typically optimize a universal sampling strategy for all types of scans, overlooking the fact that the optimal strategy may vary depending on the specific scanning task, whether it involves particular body scans (e.g., chest CT scans) or downstream clinical applications (e.g., disease diagnosis). The optimal strategy for one scanning task may not perform as well when applied to other tasks. To address this problem, we propose a deep learning framework that learns task-specific sampling strategies with a multi-task approach to train a unified reconstruction network while tailoring optimal sampling strategies for each individual task. Thus, a task-specific sampling strategy can be applied for each type of scans to improve the quality of SVCT imaging and further assist in performance of downstream clinical usage. Extensive experiments across different scanning types provide validation for the effectiveness of task-specific sampling strategies in enhancing imaging quality. Experiments involving downstream tasks verify the clinical value of learned sampling strategies, as evidenced by notable improvements in downstream task performance. Furthermore, the utilization of a multi-task framework with a shared reconstruction network facilitates deployment on current imaging devices with switchable task-specific modules, and allows for easily integrate new tasks without retraining the entire model.
Enhancing Global Sensitivity and Uncertainty Quantification in Medical Image Reconstruction with Monte Carlo Arbitrary-Masked Mamba
May 27, 2024Deep learning has been extensively applied in medical image reconstruction, where Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) represent the predominant paradigms, each possessing distinct advantages and inherent limitations: CNNs exhibit linear complexity with local sensitivity, whereas ViTs demonstrate quadratic complexity with global sensitivity. The emerging Mamba has shown superiority in learning visual representation, which combines the advantages of linear scalability and global sensitivity. In this study, we introduce MambaMIR, an Arbitrary-Masked Mamba-based model with wavelet decomposition for joint medical image reconstruction and uncertainty estimation. A novel Arbitrary Scan Masking (ASM) mechanism ``masks out'' redundant information to introduce randomness for further uncertainty estimation. Compared to the commonly used Monte Carlo (MC) dropout, our proposed MC-ASM provides an uncertainty map without the need for hyperparameter tuning and mitigates the performance drop typically observed when applying dropout to low-level tasks. For further texture preservation and better perceptual quality, we employ the wavelet transformation into MambaMIR and explore its variant based on the Generative Adversarial Network, namely MambaMIR-GAN. Comprehensive experiments have been conducted for multiple representative medical image reconstruction tasks, demonstrating that the proposed MambaMIR and MambaMIR-GAN outperform other baseline and state-of-the-art methods in different reconstruction tasks, where MambaMIR achieves the best reconstruction fidelity and MambaMIR-GAN has the best perceptual quality. In addition, our MC-ASM provides uncertainty maps as an additional tool for clinicians, while mitigating the typical performance drop caused by the commonly used dropout.
MambaMIR: An Arbitrary-Masked Mamba for Joint Medical Image Reconstruction and Uncertainty Estimation
Feb 28, 2024


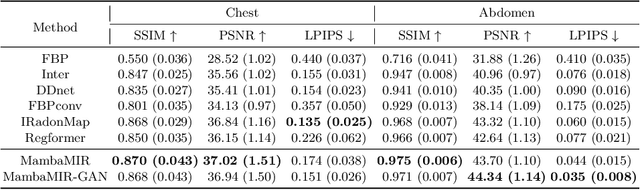
The recent Mamba model has shown remarkable adaptability for visual representation learning, including in medical imaging tasks. This study introduces MambaMIR, a Mamba-based model for medical image reconstruction, as well as its Generative Adversarial Network-based variant, MambaMIR-GAN. Our proposed MambaMIR inherits several advantages, such as linear complexity, global receptive fields, and dynamic weights, from the original Mamba model. The innovated arbitrary-mask mechanism effectively adapt Mamba to our image reconstruction task, providing randomness for subsequent Monte Carlo-based uncertainty estimation. Experiments conducted on various medical image reconstruction tasks, including fast MRI and SVCT, which cover anatomical regions such as the knee, chest, and abdomen, have demonstrated that MambaMIR and MambaMIR-GAN achieve comparable or superior reconstruction results relative to state-of-the-art methods. Additionally, the estimated uncertainty maps offer further insights into the reliability of the reconstruction quality. The code is publicly available at https://github.com/ayanglab/MambaMIR.
Learning from Positive and Unlabeled Data with Augmented Classes
Jul 27, 2022
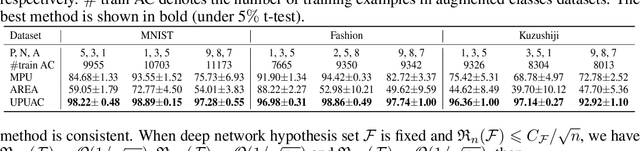
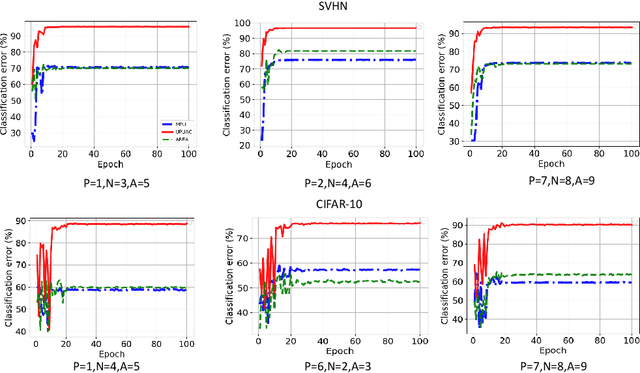
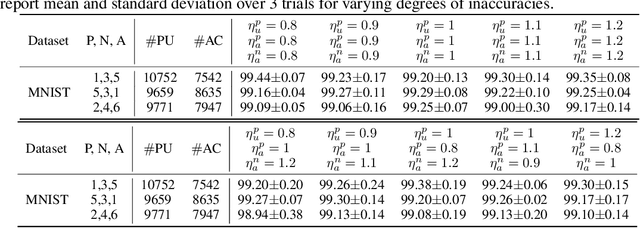
Positive Unlabeled (PU) learning aims to learn a binary classifier from only positive and unlabeled data, which is utilized in many real-world scenarios. However, existing PU learning algorithms cannot deal with the real-world challenge in an open and changing scenario, where examples from unobserved augmented classes may emerge in the testing phase. In this paper, we propose an unbiased risk estimator for PU learning with Augmented Classes (PUAC) by utilizing unlabeled data from the augmented classes distribution, which can be easily collected in many real-world scenarios. Besides, we derive the estimation error bound for the proposed estimator, which provides a theoretical guarantee for its convergence to the optimal solution. Experiments on multiple realistic datasets demonstrate the effectiveness of proposed approach.
Low-Dose CT Denoising via Sinogram Inner-Structure Transformer
Apr 18, 2022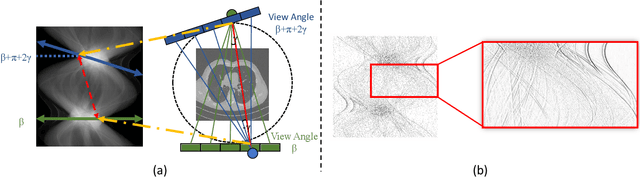
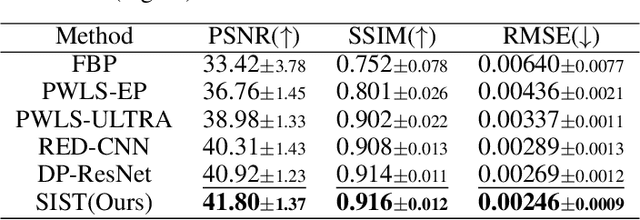
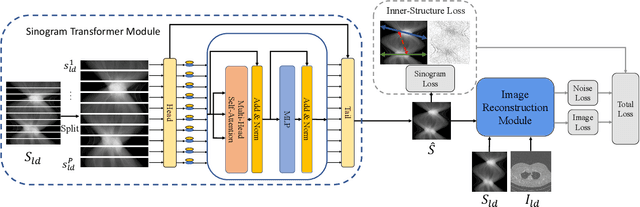

Low-Dose Computed Tomography (LDCT) technique, which reduces the radiation harm to human bodies, is now attracting increasing interest in the medical imaging field. As the image quality is degraded by low dose radiation, LDCT exams require specialized reconstruction methods or denoising algorithms. However, most of the recent effective methods overlook the inner-structure of the original projection data (sinogram) which limits their denoising ability. The inner-structure of the sinogram represents special characteristics of the data in the sinogram domain. By maintaining this structure while denoising, the noise can be obviously restrained. Therefore, we propose an LDCT denoising network namely Sinogram Inner-Structure Transformer (SIST) to reduce the noise by utilizing the inner-structure in the sinogram domain. Specifically, we study the CT imaging mechanism and statistical characteristics of sinogram to design the sinogram inner-structure loss including the global and local inner-structure for restoring high-quality CT images. Besides, we propose a sinogram transformer module to better extract sinogram features. The transformer architecture using a self-attention mechanism can exploit interrelations between projections of different view angles, which achieves an outstanding performance in sinogram denoising. Furthermore, in order to improve the performance in the image domain, we propose the image reconstruction module to complementarily denoise both in the sinogram and image domain.