 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Ultra-Fast Cardiovascular Imaging Across Heterogeneous Clinical Environments with a Generalist Foundation Model and Multimodal Database
Dec 25, 2025Multimodal cardiovascular magnetic resonance (CMR) imaging provides comprehensive and non-invasive insights into cardiovascular disease (CVD) diagnosis and underlying mechanisms. Despite decades of advancements, its widespread clinical adoption remains constrained by prolonged scan times and heterogeneity across medical environments. This underscores the urgent need for a generalist reconstruction foundation model for ultra-fast CMR imaging, one capable of adapting across diverse imaging scenarios and serving as the essential substrate for all downstream analyses. To enable this goal, we curate MMCMR-427K, the largest and most comprehensive multimodal CMR k-space database to date, comprising 427,465 multi-coil k-space data paired with structured metadata across 13 international centers, 12 CMR modalities, 15 scanners, and 17 CVD categories in populations across three continents. Building on this unprecedented resource, we introduce CardioMM, a generalist reconstruction foundation model capable of dynamically adapting to heterogeneous fast CMR imaging scenarios. CardioMM unifies semantic contextual understanding with physics-informed data consistency to deliver robust reconstructions across varied scanners, protocols, and patient presentations. Comprehensive evaluations demonstrate that CardioMM achieves state-of-the-art performance in the internal centers and exhibits strong zero-shot generalization to unseen external settings. Even at imaging acceleration up to 24x, CardioMM reliably preserves key cardiac phenotypes, quantitative myocardial biomarkers, and diagnostic image quality, enabling a substantial increase in CMR examination throughput without compromising clinical integrity. Together, our open-access MMCMR-427K database and CardioMM framework establish a scalable pathway toward high-throughput, high-quality, and clinically accessible cardiovascular imaging.
Error Bound Analysis of Physics-Informed Neural Networks-Driven T2 Quantification in Cardiac Magnetic Resonance Imaging
Dec 16, 2025



Physics-Informed Neural Networks (PINN) are emerging as a promising approach for quantitative parameter estimation of Magnetic Resonance Imaging (MRI). While existing deep learning methods can provide an accurate quantitative estimation of the T2 parameter, they still require large amounts of training data and lack theoretical support and a recognized gold standard. Thus, given the absence of PINN-based approaches for T2 estimation, we propose embedding the fundamental physics of MRI, the Bloch equation, in the loss of PINN, which is solely based on target scan data and does not require a pre-defined training database. Furthermore, by deriving rigorous upper bounds for both the T2 estimation error and the generalization error of the Bloch equation solution, we establish a theoretical foundation for evaluating the PINN's quantitative accuracy. Even without access to the ground truth or a gold standard, this theory enables us to estimate the error with respect to the real quantitative parameter T2. The accuracy of T2 mapping and the validity of the theoretical analysis are demonstrated on a numerical cardiac model and a water phantom, where our method exhibits excellent quantitative precision in the myocardial T2 range. Clinical applicability is confirmed in 94 acute myocardial infarction (AMI) patients, achieving low-error quantitative T2 estimation under the theoretical error bound, highlighting the robustness and potential of PINN.
Towards Universal Learning-based Model for Cardiac Image Reconstruction: Summary of the CMRxRecon2024 Challenge
Mar 05, 2025Cardiovascular magnetic resonance (CMR) offers diverse imaging contrasts for assessment of cardiac function and tissue characterization. However, acquiring each single CMR modality is often time-consuming, and comprehensive clinical protocols require multiple modalities with various sampling patterns, further extending the overall acquisition time and increasing susceptibility to motion artifacts. Existing deep learning-based reconstruction methods are often designed for specific acquisition parameters, which limits their ability to generalize across a variety of scan scenarios. As part of the CMRxRecon Series, the CMRxRecon2024 challenge provides diverse datasets encompassing multi-modality multi-view imaging with various sampling patterns, and a platform for the international community to develop and benchmark reconstruction solutions in two well-crafted tasks. Task 1 is a modality-universal setting, evaluating the out-of-distribution generalization of the reconstructed model, while Task 2 follows sampling-universal setting assessing the one-for-all adaptability of the universal model. Main contributions include providing the first and largest publicly available multi-modality, multi-view cardiac k-space dataset; developing a benchmarking platform that simulates clinical acceleration protocols, with a shared code library and tutorial for various k-t undersampling patterns and data processing; giving technical insights of enhanced data consistency based on physic-informed networks and adaptive prompt-learning embedding to be versatile to different clinical settings; additional finding on evaluation metrics to address the limitations of conventional ground-truth references in universal reconstruction tasks.
Sampling-Pattern-Agnostic MRI Reconstruction through Adaptive Consistency Enforcement with Diffusion Model
Sep 22, 2024Magnetic Resonance Imaging (MRI) is a powerful, non-invasive diagnostic tool; however, its clinical applicability is constrained by prolonged acquisition times. Whilst present deep learning-based approaches have demonstrated potential in expediting MRI processes, these methods usually rely on known sampling patterns and exhibit limited generalisability to novel patterns. In the paper, we propose a sampling-pattern-agnostic MRI reconstruction method via a diffusion model through adaptive consistency enforcement. Our approach effectively reconstructs high-fidelity images with varied under-sampled acquisitions, generalising across contrasts and acceleration factors regardless of sampling trajectories. We train and validate across all contrasts in the MICCAI 2024 Cardiac MRI Reconstruction Challenge (CMRxRecon) dataset for the ``Random sampling CMR reconstruction'' task. Evaluation results indicate that our proposed method significantly outperforms baseline methods.
CMRxRecon2024: A Multi-Modality, Multi-View K-Space Dataset Boosting Universal Machine Learning for Accelerated Cardiac MRI
Jun 27, 2024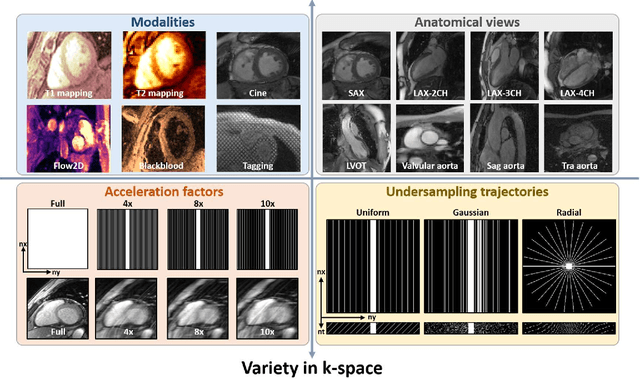
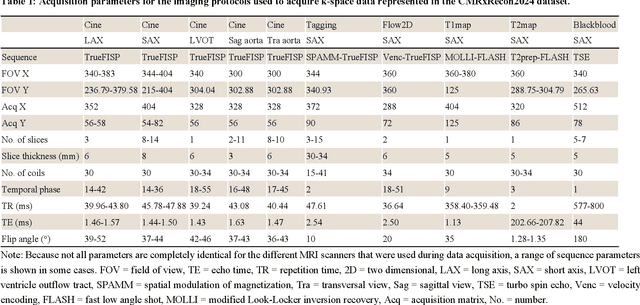

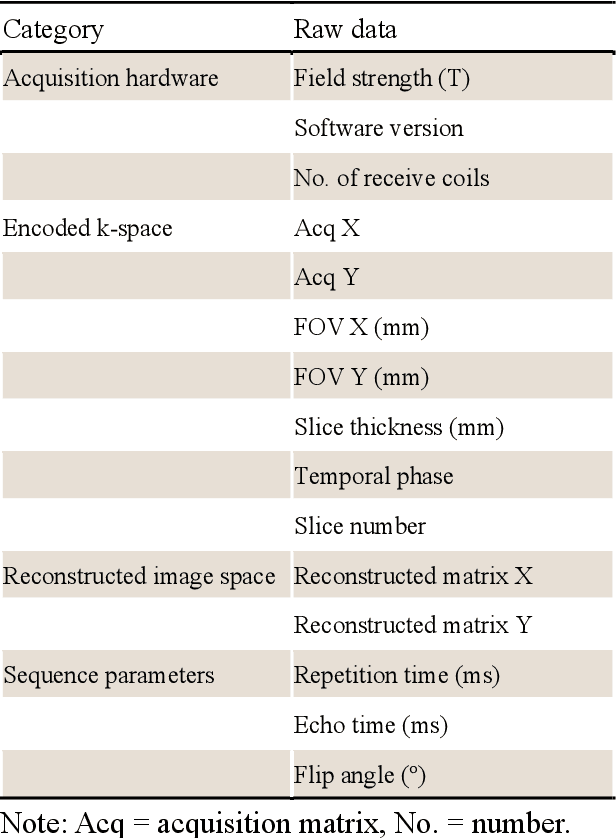
Cardiac magnetic resonance imaging (MRI) has emerged as a clinically gold-standard technique for diagnosing cardiac diseases, thanks to its ability to provide diverse information with multiple modalities and anatomical views. Accelerated cardiac MRI is highly expected to achieve time-efficient and patient-friendly imaging, and then advanced image reconstruction approaches are required to recover high-quality, clinically interpretable images from undersampled measurements. However, the lack of publicly available cardiac MRI k-space dataset in terms of both quantity and diversity has severely hindered substantial technological progress, particularly for data-driven artificial intelligence. Here, we provide a standardized, diverse, and high-quality CMRxRecon2024 dataset to facilitate the technical development, fair evaluation, and clinical transfer of cardiac MRI reconstruction approaches, towards promoting the universal frameworks that enable fast and robust reconstructions across different cardiac MRI protocols in clinical practice. To the best of our knowledge, the CMRxRecon2024 dataset is the largest and most diverse publicly available cardiac k-space dataset. It is acquired from 330 healthy volunteers, covering commonly used modalities, anatomical views, and acquisition trajectories in clinical cardiac MRI workflows. Besides, an open platform with tutorials, benchmarks, and data processing tools is provided to facilitate data usage, advanced method development, and fair performance evaluation.
An Empirical Study on the Fairness of Foundation Models for Multi-Organ Image Segmentation
Jun 18, 2024



The segmentation foundation model, e.g., Segment Anything Model (SAM), has attracted increasing interest in the medical image community. Early pioneering studies primarily concentrated on assessing and improving SAM's performance from the perspectives of overall accuracy and efficiency, yet little attention was given to the fairness considerations. This oversight raises questions about the potential for performance biases that could mirror those found in task-specific deep learning models like nnU-Net. In this paper, we explored the fairness dilemma concerning large segmentation foundation models. We prospectively curate a benchmark dataset of 3D MRI and CT scans of the organs including liver, kidney, spleen, lung and aorta from a total of 1056 healthy subjects with expert segmentations. Crucially, we document demographic details such as gender, age, and body mass index (BMI) for each subject to facilitate a nuanced fairness analysis. We test state-of-the-art foundation models for medical image segmentation, including the original SAM, medical SAM and SAT models, to evaluate segmentation efficacy across different demographic groups and identify disparities. Our comprehensive analysis, which accounts for various confounding factors, reveals significant fairness concerns within these foundational models. Moreover, our findings highlight not only disparities in overall segmentation metrics, such as the Dice Similarity Coefficient but also significant variations in the spatial distribution of segmentation errors, offering empirical evidence of the nuanced challenges in ensuring fairness in medical image segmentation.
Enhancing Global Sensitivity and Uncertainty Quantification in Medical Image Reconstruction with Monte Carlo Arbitrary-Masked Mamba
May 27, 2024Deep learning has been extensively applied in medical image reconstruction, where Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) represent the predominant paradigms, each possessing distinct advantages and inherent limitations: CNNs exhibit linear complexity with local sensitivity, whereas ViTs demonstrate quadratic complexity with global sensitivity. The emerging Mamba has shown superiority in learning visual representation, which combines the advantages of linear scalability and global sensitivity. In this study, we introduce MambaMIR, an Arbitrary-Masked Mamba-based model with wavelet decomposition for joint medical image reconstruction and uncertainty estimation. A novel Arbitrary Scan Masking (ASM) mechanism ``masks out'' redundant information to introduce randomness for further uncertainty estimation. Compared to the commonly used Monte Carlo (MC) dropout, our proposed MC-ASM provides an uncertainty map without the need for hyperparameter tuning and mitigates the performance drop typically observed when applying dropout to low-level tasks. For further texture preservation and better perceptual quality, we employ the wavelet transformation into MambaMIR and explore its variant based on the Generative Adversarial Network, namely MambaMIR-GAN. Comprehensive experiments have been conducted for multiple representative medical image reconstruction tasks, demonstrating that the proposed MambaMIR and MambaMIR-GAN outperform other baseline and state-of-the-art methods in different reconstruction tasks, where MambaMIR achieves the best reconstruction fidelity and MambaMIR-GAN has the best perceptual quality. In addition, our MC-ASM provides uncertainty maps as an additional tool for clinicians, while mitigating the typical performance drop caused by the commonly used dropout.
Simultaneous Deep Learning of Myocardium Segmentation and T2 Quantification for Acute Myocardial Infarction MRI
May 17, 2024



In cardiac Magnetic Resonance Imaging (MRI) analysis, simultaneous myocardial segmentation and T2 quantification are crucial for assessing myocardial pathologies. Existing methods often address these tasks separately, limiting their synergistic potential. To address this, we propose SQNet, a dual-task network integrating Transformer and Convolutional Neural Network (CNN) components. SQNet features a T2-refine fusion decoder for quantitative analysis, leveraging global features from the Transformer, and a segmentation decoder with multiple local region supervision for enhanced accuracy. A tight coupling module aligns and fuses CNN and Transformer branch features, enabling SQNet to focus on myocardium regions. Evaluation on healthy controls (HC) and acute myocardial infarction patients (AMI) demonstrates superior segmentation dice scores (89.3/89.2) compared to state-of-the-art methods (87.7/87.9). T2 quantification yields strong linear correlations (Pearson coefficients: 0.84/0.93) with label values for HC/AMI, indicating accurate mapping. Radiologist evaluations confirm SQNet's superior image quality scores (4.60/4.58 for segmentation, 4.32/4.42 for T2 quantification) over state-of-the-art methods (4.50/4.44 for segmentation, 3.59/4.37 for T2 quantification). SQNet thus offers accurate simultaneous segmentation and quantification, enhancing cardiac disease diagnosis, such as AMI.
The state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 01, 2024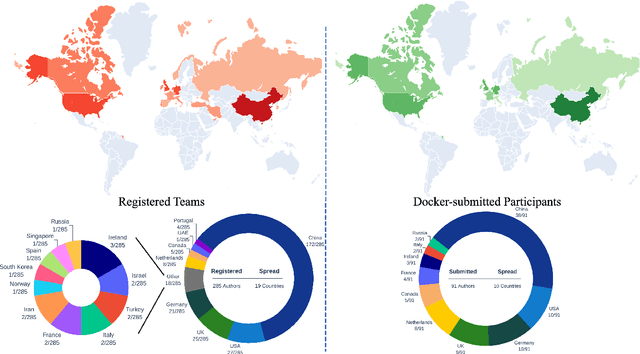
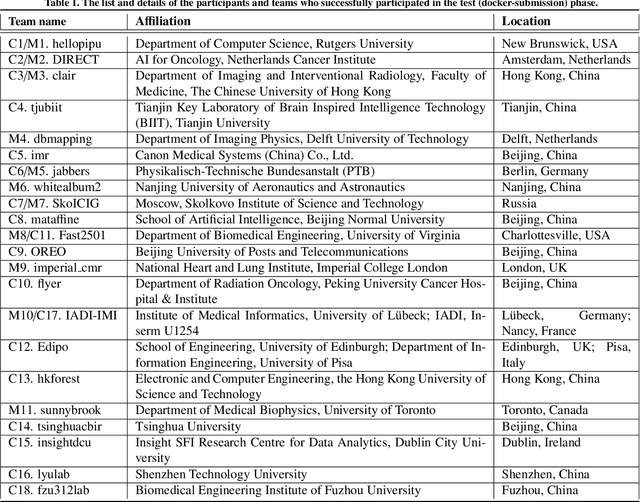
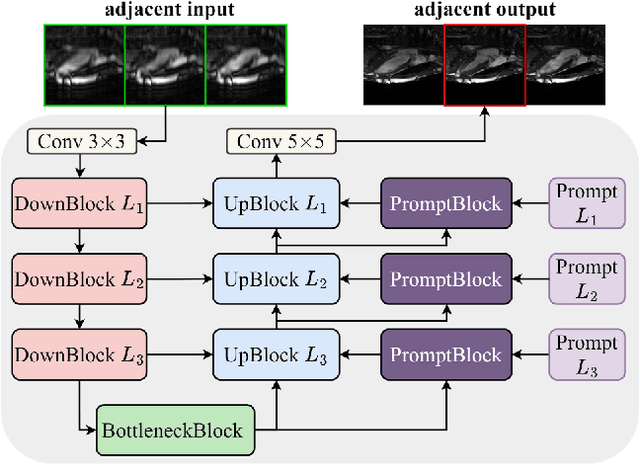
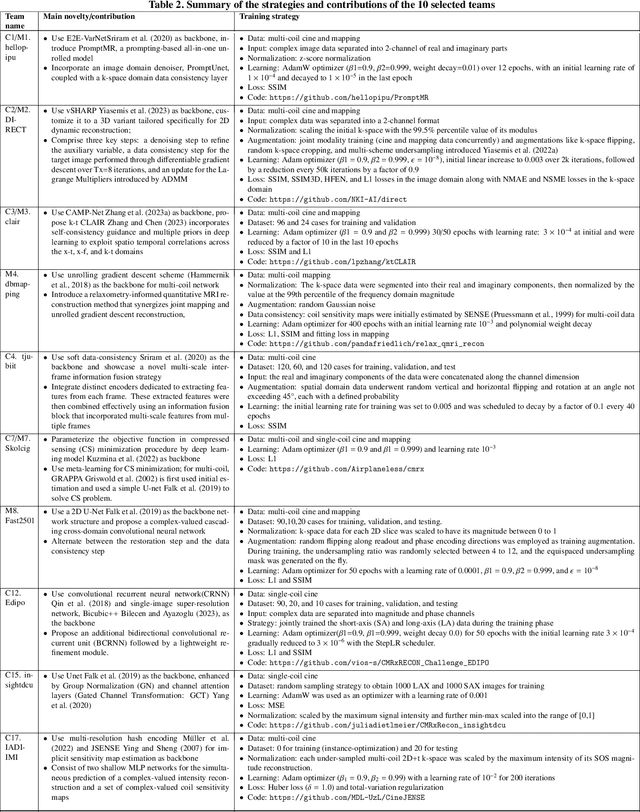
Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
Deep Separable Spatiotemporal Learning for Fast Dynamic Cardiac MRI
Feb 24, 2024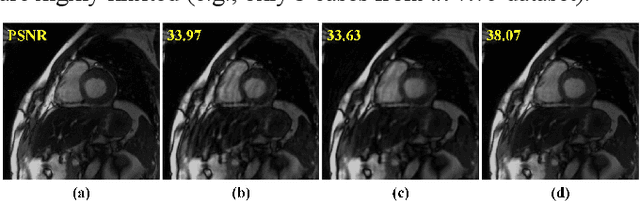
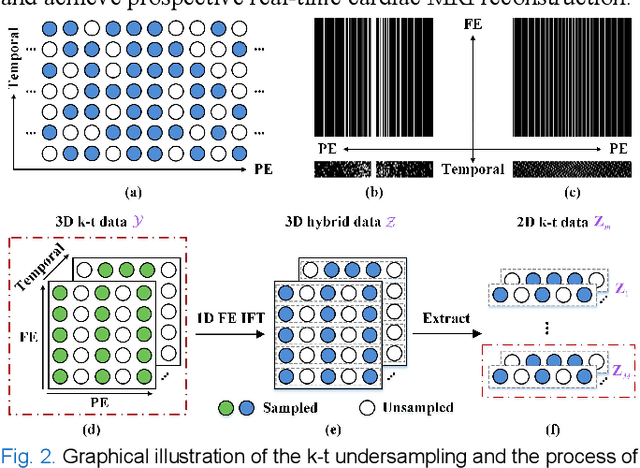
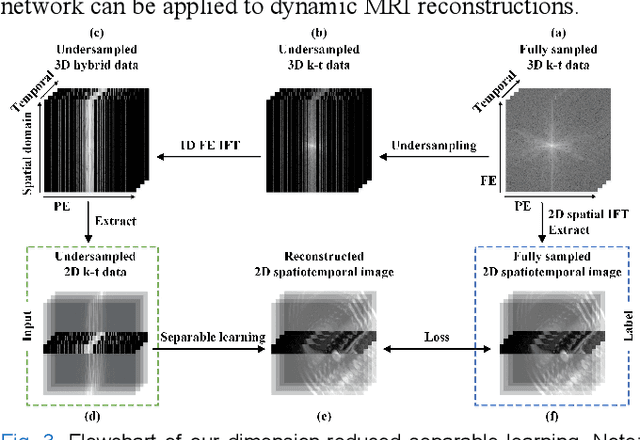
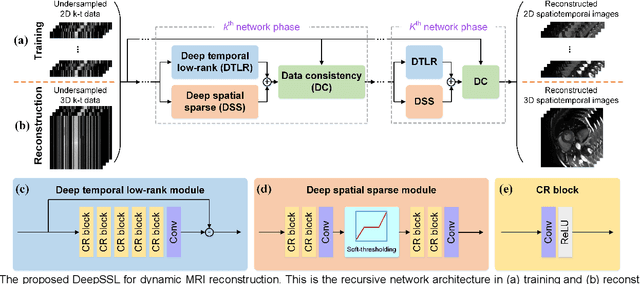
Dynamic magnetic resonance imaging (MRI) plays an indispensable role in cardiac diagnosis. To enable fast imaging, the k-space data can be undersampled but the image reconstruction poses a great challenge of high-dimensional processing. This challenge leads to necessitate extensive training data in many deep learning reconstruction methods. This work proposes a novel and efficient approach, leveraging a dimension-reduced separable learning scheme that excels even with highly limited training data. We further integrate it with spatiotemporal priors to develop a Deep Separable Spatiotemporal Learning network (DeepSSL), which unrolls an iteration process of a reconstruction model with both temporal low-rankness and spatial sparsity. Intermediate outputs are visualized to provide insights into the network's behavior and enhance its interpretability. Extensive results on cardiac cine datasets show that the proposed DeepSSL is superior to the state-of-the-art methods visually and quantitatively, while reducing the demand for training cases by up to 75%. And its preliminary adaptability to cardiac patients has been verified through experienced radiologists' and cardiologists' blind reader study. Additionally, DeepSSL also benefits for achieving the downstream task of cardiac segmentation with higher accuracy and shows robustness in prospective real-time cardiac MRI.