 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Bound Analysis of Physics-Informed Neural Networks-Driven T2 Quantification in Cardiac Magnetic Resonance Imaging
Dec 16, 2025



Physics-Informed Neural Networks (PINN) are emerging as a promising approach for quantitative parameter estimation of Magnetic Resonance Imaging (MRI). While existing deep learning methods can provide an accurate quantitative estimation of the T2 parameter, they still require large amounts of training data and lack theoretical support and a recognized gold standard. Thus, given the absence of PINN-based approaches for T2 estimation, we propose embedding the fundamental physics of MRI, the Bloch equation, in the loss of PINN, which is solely based on target scan data and does not require a pre-defined training database. Furthermore, by deriving rigorous upper bounds for both the T2 estimation error and the generalization error of the Bloch equation solution, we establish a theoretical foundation for evaluating the PINN's quantitative accuracy. Even without access to the ground truth or a gold standard, this theory enables us to estimate the error with respect to the real quantitative parameter T2. The accuracy of T2 mapping and the validity of the theoretical analysis are demonstrated on a numerical cardiac model and a water phantom, where our method exhibits excellent quantitative precision in the myocardial T2 range. Clinical applicability is confirmed in 94 acute myocardial infarction (AMI) patients, achieving low-error quantitative T2 estimation under the theoretical error bound, highlighting the robustness and potential of PINN.
Simultaneous Deep Learning of Myocardium Segmentation and T2 Quantification for Acute Myocardial Infarction MRI
May 17, 2024



In cardiac Magnetic Resonance Imaging (MRI) analysis, simultaneous myocardial segmentation and T2 quantification are crucial for assessing myocardial pathologies. Existing methods often address these tasks separately, limiting their synergistic potential. To address this, we propose SQNet, a dual-task network integrating Transformer and Convolutional Neural Network (CNN) components. SQNet features a T2-refine fusion decoder for quantitative analysis, leveraging global features from the Transformer, and a segmentation decoder with multiple local region supervision for enhanced accuracy. A tight coupling module aligns and fuses CNN and Transformer branch features, enabling SQNet to focus on myocardium regions. Evaluation on healthy controls (HC) and acute myocardial infarction patients (AMI) demonstrates superior segmentation dice scores (89.3/89.2) compared to state-of-the-art methods (87.7/87.9). T2 quantification yields strong linear correlations (Pearson coefficients: 0.84/0.93) with label values for HC/AMI, indicating accurate mapping. Radiologist evaluations confirm SQNet's superior image quality scores (4.60/4.58 for segmentation, 4.32/4.42 for T2 quantification) over state-of-the-art methods (4.50/4.44 for segmentation, 3.59/4.37 for T2 quantification). SQNet thus offers accurate simultaneous segmentation and quantification, enhancing cardiac disease diagnosis, such as AMI.
Deep Separable Spatiotemporal Learning for Fast Dynamic Cardiac MRI
Feb 24, 2024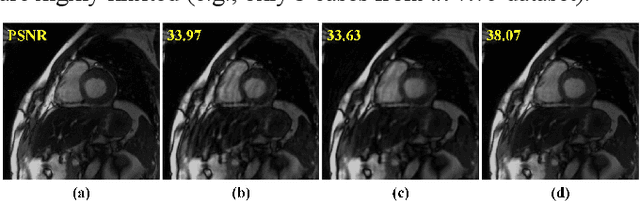
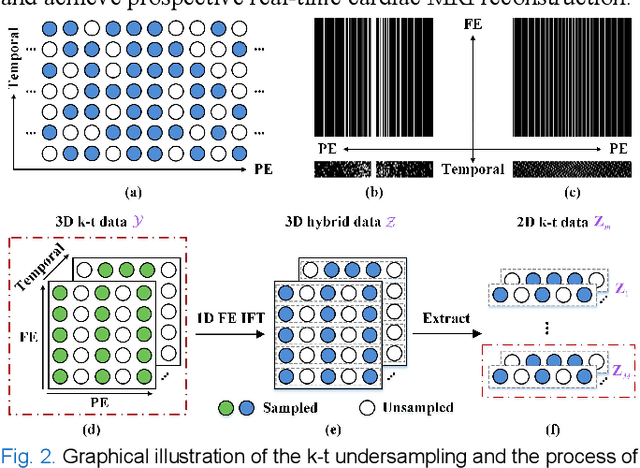
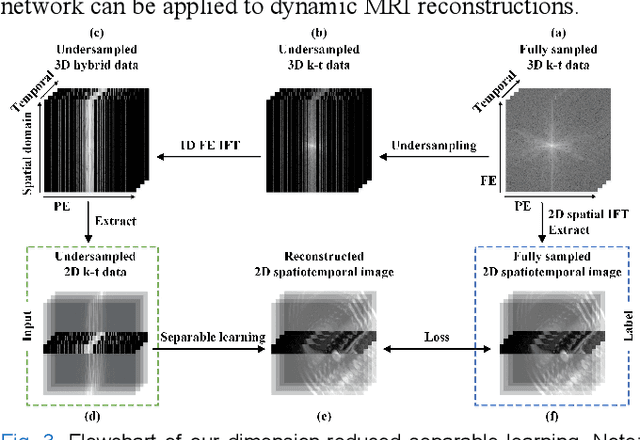
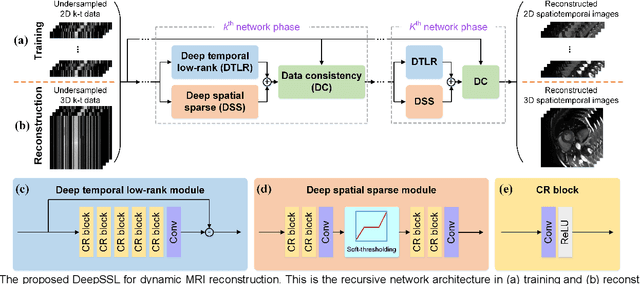
Dynamic magnetic resonance imaging (MRI) plays an indispensable role in cardiac diagnosis. To enable fast imaging, the k-space data can be undersampled but the image reconstruction poses a great challenge of high-dimensional processing. This challenge leads to necessitate extensive training data in many deep learning reconstruction methods. This work proposes a novel and efficient approach, leveraging a dimension-reduced separable learning scheme that excels even with highly limited training data. We further integrate it with spatiotemporal priors to develop a Deep Separable Spatiotemporal Learning network (DeepSSL), which unrolls an iteration process of a reconstruction model with both temporal low-rankness and spatial sparsity. Intermediate outputs are visualized to provide insights into the network's behavior and enhance its interpretability. Extensive results on cardiac cine datasets show that the proposed DeepSSL is superior to the state-of-the-art methods visually and quantitatively, while reducing the demand for training cases by up to 75%. And its preliminary adaptability to cardiac patients has been verified through experienced radiologists' and cardiologists' blind reader study. Additionally, DeepSSL also benefits for achieving the downstream task of cardiac segmentation with higher accuracy and shows robustness in prospective real-time cardiac MRI.
Aligning Multi-Sequence CMR Towards Fully Automated Myocardial Pathology Segmentation
Feb 07, 2023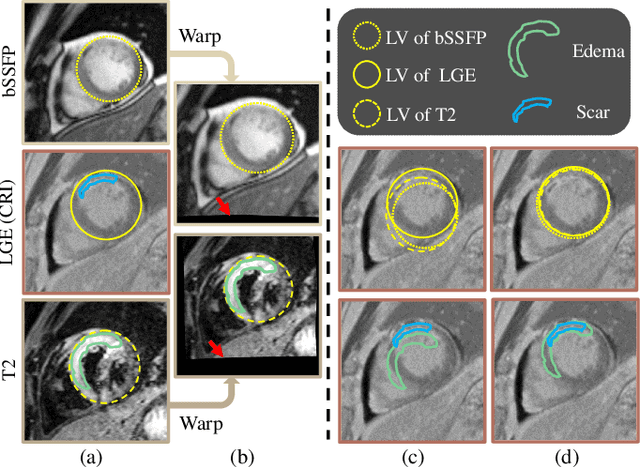
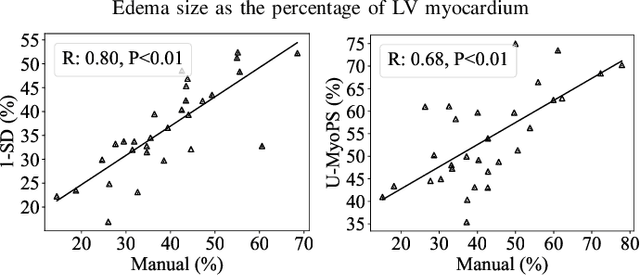
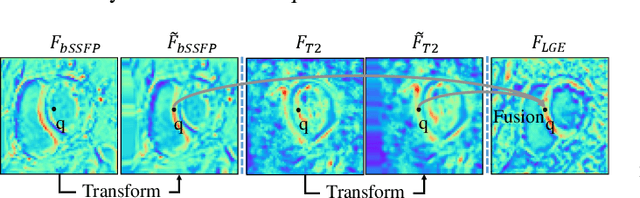
Myocardial pathology segmentation (MyoPS) is critical for the risk stratification and treatment planning of myocardial infarction (MI). Multi-sequence cardiac magnetic resonance (MS-CMR) images can provide valuable information. For instance, balanced steady-state free precession cine sequences present clear anatomical boundaries, while late gadolinium enhancement and T2-weighted CMR sequences visualize myocardial scar and edema of MI, respectively. Existing methods usually fuse anatomical and pathological information from different CMR sequences for MyoPS, but assume that these images have been spatially aligned. However, MS-CMR images are usually unaligned due to the respiratory motions in clinical practices, which poses additional challenges for MyoPS. This work presents an automatic MyoPS framework for unaligned MS-CMR images. Specifically, we design a combined computing model for simultaneous image registration and information fusion, which aggregates multi-sequence features into a common space to extract anatomical structures (i.e., myocardium). Consequently, we can highlight the informative regions in the common space via the extracted myocardium to improve MyoPS performance, considering the spatial relationship between myocardial pathologies and myocardium. Experiments on a private MS-CMR dataset and a public dataset from the MYOPS2020 challenge show that our framework could achieve promising performance for fully automatic MyoPS.
MyoPS-Net: Myocardial Pathology Segmentation with Flexible Combination of Multi-Sequence CMR Images
Nov 06, 2022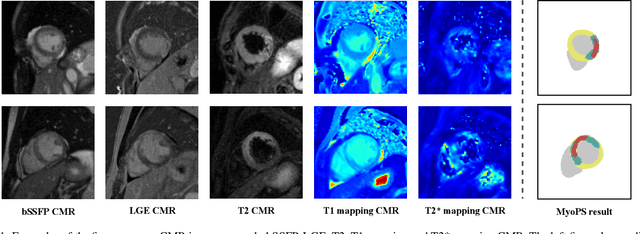



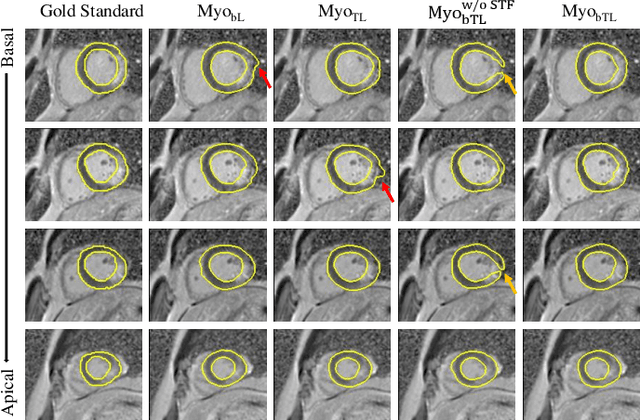
Myocardial pathology segmentation (MyoPS) can be a prerequisite for the accurate diagnosis and treatment planning of myocardial infarction. However, achieving this segmentation is challenging, mainly due to the inadequate and indistinct information from an image. In this work, we develop an end-to-end deep neural network, referred to as MyoPS-Net, to flexibly combine five-sequence cardiac magnetic resonance (CMR) images for MyoPS. To extract precise and adequate information, we design an effective yet flexible architecture to extract and fuse cross-modal features. This architecture can tackle different numbers of CMR images and complex combinations of modalities, with output branches targeting specific pathologies. To impose anatomical knowledge on the segmentation results, we first propose a module to regularize myocardium consistency and localize the pathologies, and then introduce an inclusiveness loss to utilize relations between myocardial scars and edema. We evaluated the proposed MyoPS-Net on two datasets, i.e., a private one consisting of 50 paired multi-sequence CMR images and a public one from MICCAI2020 MyoPS Challenge. Experimental results showed that MyoPS-Net could achieve state-of-the-art performance in various scenarios. Note that in practical clinics, the subjects may not have full sequences, such as missing LGE CMR or mapping CMR scans. We therefore conducted extensive experiments to investigate the performance of the proposed method in dealing with such complex combinations of different CMR sequences. Results proved the superiority and generalizability of MyoPS-Net, and more importantly, indicated a practical clinical application.
Learning Topic Models: Identifiability and Finite-Sample Analysis
Oct 08, 2021


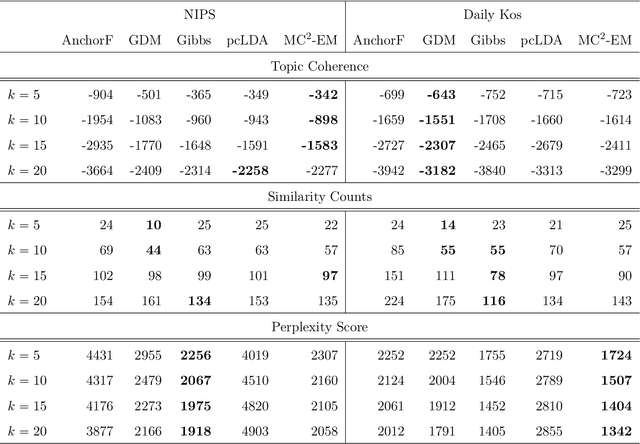
Topic models provide a useful text-mining tool for learning, extracting and discovering latent structures in large text corpora. Although a plethora of methods have been proposed for topic modeling, a formal theoretical investigation on the statistical identifiability and accuracy of latent topic estimation is lacking in the literature. In this paper, we propose a maximum likelihood estimator (MLE) of latent topics based on a specific integrated likelihood, which is naturally connected to the concept of volume minimization in computational geometry. Theoretically, we introduce a new set of geometric conditions for topic model identifiability, which are weaker than conventional separability conditions relying on the existence of anchor words or pure topic documents. We conduct finite-sample error analysis for the proposed estimator and discuss the connection of our results with existing ones. We conclude with empirical studies on both simulated and real datasets.