 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Topic Models: Identifiability and Finite-Sample Analysis
Paper and Code
Oct 08, 2021


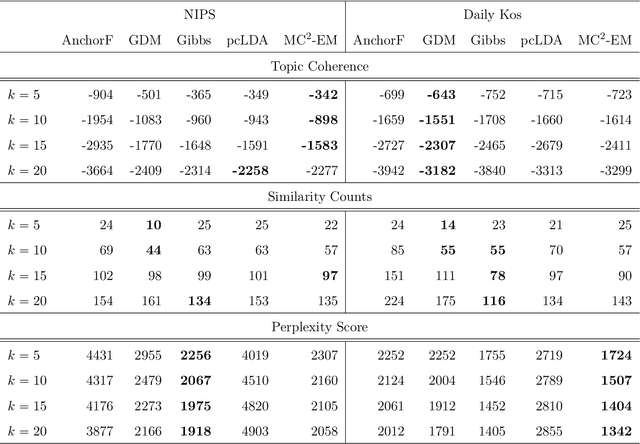
Topic models provide a useful text-mining tool for learning, extracting and discovering latent structures in large text corpora. Although a plethora of methods have been proposed for topic modeling, a formal theoretical investigation on the statistical identifiability and accuracy of latent topic estimation is lacking in the literature. In this paper, we propose a maximum likelihood estimator (MLE) of latent topics based on a specific integrated likelihood, which is naturally connected to the concept of volume minimization in computational geometry. Theoretically, we introduce a new set of geometric conditions for topic model identifiability, which are weaker than conventional separability conditions relying on the existence of anchor words or pure topic documents. We conduct finite-sample error analysis for the proposed estimator and discuss the connection of our results with existing ones. We conclude with empirical studies on both simulated and real datasets.