 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Scalable Terminal Task Synthesis via Skill Graphs
Apr 28, 2026Terminal agents have demonstrated strong potential for autonomous command-line execution, yet their training remains constrained by the scarcity of high-quality and diverse execution trajectories. Existing approaches mitigate this bottleneck by synthesizing large-scale terminal task instances for trajectory sampling. However, they primarily focus on scaling the number of tasks while providing limited control over the diversity of execution trajectories that agents actually experience during training. In this paper, we present SkillSynth, an automated framework for terminal task synthesis built on a scenario-mediated skill graph. SkillSynth first constructs a large-scale skill graph, where scenarios serve as intermediate transition nodes that connect diverse command-line skills. It then samples paths from this graph as abstractions of real-world workflows, and uses a multi-agent harness to instantiate them into executable task instances. By grounding task synthesis in graph-sampled workflow paths, SkillSynth explicitly controls the diversity of minimal execution trajectories required to solve the synthesized tasks. Experiments on Terminal-Bench demonstrate the effectiveness of SkillSynth. Moreover, task instances synthesized by SkillSynth have been adopted to train Hy3 Preview, contributing to its enhanced agentic capabilities in terminal-based settings.
TA-GGAD: Testing-time Adaptive Graph Model for Generalist Graph Anomaly Detection
Mar 10, 2026A significant number of anomalous nodes in the real world, such as fake news, noncompliant users, malicious transactions, and malicious posts, severely compromises the health of the graph data ecosystem and urgently requires effective identification and processing. With anomalies that span multiple data domains yet exhibit vast differences in features, cross-domain detection models face severe domain shift issues, which limit their generalizability across all domains. This study identifies and quantitatively analyzes a specific feature mismatch pattern exhibited by domain shift in graph anomaly detection, which we define as the \emph{Anomaly Disassortativity} issue ($\mathcal{AD}$). Based on the modeling of the issue $\mathcal{AD}$, we introduce a novel graph foundation model for anomaly detection. It achieves cross-domain generalization in different graphs, requiring only a single training phase to perform effectively across diverse domains. The experimental findings, based on fourteen diverse real-world graphs, confirm a breakthrough in the model's cross-domain adaptation, achieving a pioneering state-of-the-art (SOTA) level in terms of detection accuracy. In summary, the proposed theory of $\mathcal{AD}$ provides a novel theoretical perspective and a practical route for future research in generalist graph anomaly detection (GGAD). The code is available at https://anonymous.4open.science/r/Anonymization-TA-GGAD/.
SERM: Self-Evolving Relevance Model with Agent-Driven Learning from Massive Query Streams
Jan 14, 2026Due to the dynamically evolving nature of real-world query streams, relevance models struggle to generalize to practical search scenarios. A sophisticated solution is self-evolution techniques. However, in large-scale industrial settings with massive query streams, this technique faces two challenges: (1) informative samples are often sparse and difficult to identify, and (2) pseudo-labels generated by the current model could be unreliable. To address these challenges, in this work, we propose a Self-Evolving Relevance Model approach (SERM), which comprises two complementary multi-agent modules: a multi-agent sample miner, designed to detect distributional shifts and identify informative training samples, and a multi-agent relevance annotator, which provides reliable labels through a two-level agreement framework. We evaluate SERM in a large-scale industrial setting, which serves billions of user requests daily. Experimental results demonstrate that SERM can achieve significant performance gains through iterative self-evolution, as validated by extensive offline multilingual evaluations and online testing.
Simulation-based Inference via Langevin Dynamics with Score Matching
Sep 04, 2025Simulation-based inference (SBI) enables Bayesian analysis when the likelihood is intractable but model simulations are available. Recent advances in statistics and machine learning, including Approximate Bayesian Computation and deep generative models, have expanded the applicability of SBI, yet these methods often face challenges in moderate to high-dimensional parameter spaces. Motivated by the success of gradient-based Monte Carlo methods in Bayesian sampling, we propose a novel SBI method that integrates score matching with Langevin dynamics to explore complex posterior landscapes more efficiently in such settings. Our approach introduces tailored score-matching procedures for SBI, including a localization scheme that reduces simulation costs and an architectural regularization that embeds the statistical structure of log-likelihood scores to improve score-matching accuracy. We provide theoretical analysis of the method and illustrate its practical benefits on benchmark tasks and on more challenging problems in moderate to high dimensions, where it performs favorably compared to existing approaches.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Embedding Empirical Distributions for Computing Optimal Transport Maps
Apr 24, 2025Distributional data have become increasingly prominent in modern signal processing, highlighting the necessity of computing optimal transport (OT) maps across multiple probability distributions. Nevertheless, recent studies on neural OT methods predominantly focused on the efficient computation of a single map between two distributions. To address this challenge, we introduce a novel approach to learning transport maps for new empirical distributions. Specifically, we employ the transformer architecture to produce embeddings from distributional data of varying length; these embeddings are then fed into a hypernetwork to generate neural OT maps. Various numerical experiments were conducted to validate the embeddings and the generated OT maps. The model implementation and the code are provided on https://github.com/jiangmingchen/HOTET.
Unveiling Contrastive Learning's Capability of Neighborhood Aggregation for Collaborative Filtering
Apr 14, 2025



Personalized recommendation is widely used in the web applications, and graph contrastive learning (GCL) has gradually become a dominant approach in recommender systems, primarily due to its ability to extract self-supervised signals from raw interaction data, effectively alleviating the problem of data sparsity. A classic GCL-based method typically uses data augmentation during graph convolution to generates more contrastive views, and performs contrast on these new views to obtain rich self-supervised signals. Despite this paradigm is effective, the reasons behind the performance gains remain a mystery. In this paper, we first reveal via theoretical derivation that the gradient descent process of the CL objective is formally equivalent to graph convolution, which implies that CL objective inherently supports neighborhood aggregation on interaction graphs. We further substantiate this capability through experimental validation and identify common misconceptions in the selection of positive samples in previous methods, which limit the potential of CL objective. Based on this discovery, we propose the Light Contrastive Collaborative Filtering (LightCCF) method, which introduces a novel neighborhood aggregation objective to bring users closer to all interacted items while pushing them away from other positive pairs, thus achieving high-quality neighborhood aggregation with very low time complexity. On three highly sparse public datasets, the proposed method effectively aggregate neighborhood information while preventing graph over-smoothing, demonstrating significant improvements over existing GCL-based counterparts in both training efficiency and recommendation accuracy. Our implementations are publicly accessible.
NuWa: Deriving Lightweight Task-Specific Vision Transformers for Edge Devices
Apr 04, 2025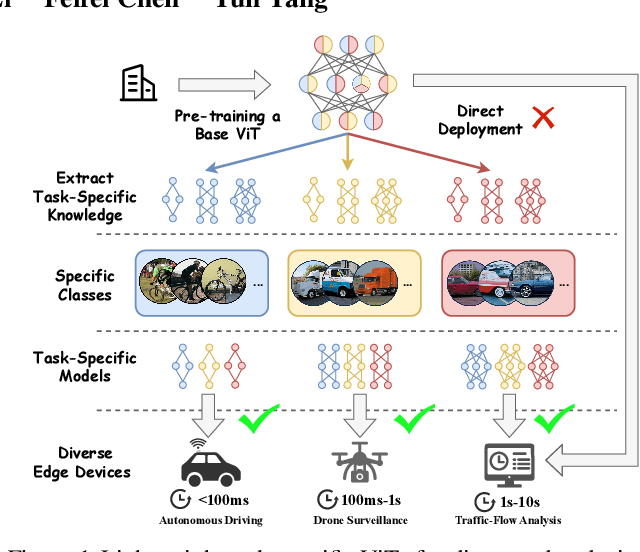



Vision Transformers (ViTs) excel in computer vision tasks but lack flexibility for edge devices' diverse needs. A vital issue is that ViTs pre-trained to cover a broad range of tasks are \textit{over-qualified} for edge devices that usually demand only part of a ViT's knowledge for specific tasks. Their task-specific accuracy on these edge devices is suboptimal. We discovered that small ViTs that focus on device-specific tasks can improve model accuracy and in the meantime, accelerate model inference. This paper presents NuWa, an approach that derives small ViTs from the base ViT for edge devices with specific task requirements. NuWa can transfer task-specific knowledge extracted from the base ViT into small ViTs that fully leverage constrained resources on edge devices to maximize model accuracy with inference latency assurance. Experiments with three base ViTs on three public datasets demonstrate that compared with state-of-the-art solutions, NuWa improves model accuracy by up to $\text{11.83}\%$ and accelerates model inference by 1.29$\times$ - 2.79$\times$. Code for reproduction is available at https://anonymous.4open.science/r/Task_Specific-3A5E.
Testing Conditional Mean Independence Using Generative Neural Networks
Jan 28, 2025Conditional mean independence (CMI) testing is crucial for statistical tasks including model determination and variable importance evaluation. In this work, we introduce a novel population CMI measure and a bootstrap-based testing procedure that utilizes deep generative neural networks to estimate the conditional mean functions involved in the population measure. The test statistic is thoughtfully constructed to ensure that even slowly decaying nonparametric estimation errors do not affect the asymptotic accuracy of the test. Our approach demonstrates strong empirical performance in scenarios with high-dimensional covariates and response variable, can handle multivariate responses, and maintains nontrivial power against local alternatives outside an $n^{-1/2}$ neighborhood of the null hypothesis. We also use numerical simulations and real-world imaging data applications to highlight the efficacy and versatility of our testing procedure.
A Likelihood Based Approach to Distribution Regression Using Conditional Deep Generative Models
Oct 02, 2024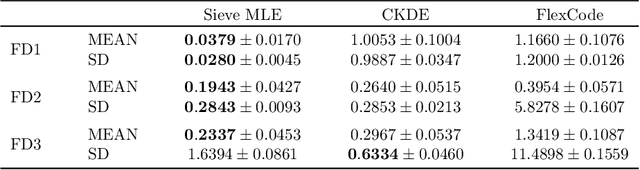
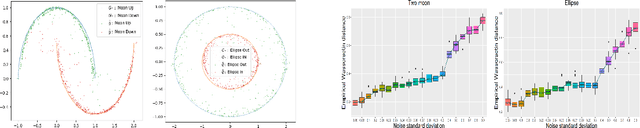

In this work, we explore the theoretical properties of conditional deep generative models under the statistical framework of distribution regression where the response variable lies in a high-dimensional ambient space but concentrates around a potentially lower-dimensional manifold. More specifically, we study the large-sample properties of a likelihood-based approach for estimating these models. Our results lead to the convergence rate of a sieve maximum likelihood estimator (MLE) for estimating the conditional distribution (and its devolved counterpart) of the response given predictors in the Hellinger (Wasserstein) metric. Our rates depend solely on the intrinsic dimension and smoothness of the true conditional distribution. These findings provide an explanation of why conditional deep generative models can circumvent the curse of dimensionality from the perspective of statistical foundations and demonstrate that they can learn a broader class of nearly singular conditional distributions. Our analysis also emphasizes the importance of introducing a small noise perturbation to the data when they are supported sufficiently close to a manifold. Finally, in our numerical studies, we demonstrate the effective implementation of the proposed approach using both synthetic and real-world datasets, which also provide complementary validation to our theoretical findings.