 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Push-Based Asynchronous Federated Learning: A Bias-Correction Aggregation Approach
May 24, 2026Asynchronous decentralized federated learning (ADFL) eliminates central coordination and global synchronization, making it attractive for large-scale and heterogeneous systems. However, frequent peer-to-peer communication, asynchronous updates on directed topologies, and non-IID data jointly lead to excessive communication overhead, biased aggregation and severe model drift. We propose PushCen-ADFL, a communication-efficient ADFL framework that enables stable training under asymmetric communication and delayed client participation. PushCen-ADFL couples communication, aggregation, and local stabilization in a shared centroid representation space, forming a closed loop between compression and optimization. Clients exchange centroid-form messages, apply average-preserving push-sum mixing to correct aggregation bias, and use a lightweight centroid regularization anchored in the same centroid space to mitigate drift under heterogeneity and staleness. A bounded, sender-deduplicated buffer further improves robustness under irregular asynchronous arrivals. Experiments on vision datasets demonstrate that PushCen-ADFL improves accuracy under data heterogeneity by up to 6\% while reducing per-push communication cost by more than 80\%, achieving a favorable accuracy-communication trade-off.
Energy and Memory-Efficient Federated Learning With Ordered Layer Freezing
Dec 29, 2025Federated Learning (FL) has emerged as a privacy-preserving paradigm for training machine learning models across distributed edge devices in the Internet of Things (IoT). By keeping data local and coordinating model training through a central server, FL effectively addresses privacy concerns and reduces communication overhead. However, the limited computational power, memory, and bandwidth of IoT edge devices pose significant challenges to the efficiency and scalability of FL, especially when training deep neural networks. Various FL frameworks have been proposed to reduce computation and communication overheads through dropout or layer freezing. However, these approaches often sacrifice accuracy or neglect memory constraints. To this end, in this work, we introduce Federated Learning with Ordered Layer Freezing (FedOLF). FedOLF consistently freezes layers in a predefined order before training, significantly mitigating computation and memory requirements. To further reduce communication and energy costs, we incorporate Tensor Operation Approximation (TOA), a lightweight alternative to conventional quantization that better preserves model accuracy. Experimental results demonstrate that over non-iid data, FedOLF achieves at least 0.3%, 6.4%, 5.81%, 4.4%, 6.27% and 1.29% higher accuracy than existing works respectively on EMNIST (with CNN), CIFAR-10 (with AlexNet), CIFAR-100 (with ResNet20 and ResNet44), and CINIC-10 (with ResNet20 and ResNet44), along with higher energy efficiency and lower memory footprint.
Data-driven Trust Bootstrapping for Mobile Edge Computing-based Industrial IoT Services
Aug 18, 2025



We propose a data-driven and context-aware approach to bootstrap trustworthiness of homogeneous Internet of Things (IoT) services in Mobile Edge Computing (MEC) based industrial IoT (IIoT) systems. The proposed approach addresses key limitations in adapting existing trust bootstrapping approaches into MEC-based IIoT systems. These key limitations include, the lack of opportunity for a service consumer to interact with a lesser-known service over a prolonged period of time to get a robust measure of its trustworthiness, inability of service consumers to consistently interact with their peers to receive reliable recommendations of the trustworthiness of a lesser-known service as well as the impact of uneven context parameters in different MEC environments causing uneven trust environments for trust evaluation. In addition, the proposed approach also tackles the problem of data sparsity via enabling knowledge sharing among different MEC environments within a given MEC topology. To verify the effectiveness of the proposed approach, we carried out a comprehensive evaluation on two real-world datasets suitably adjusted to exhibit the context-dependent trust information accumulated in MEC environments within a given MEC topology. The experimental results affirmed the effectiveness of our approach and its suitability to bootstrap trustworthiness of services in MEC-based IIoT systems.
Cloned Identity Detection in Social-Sensor Clouds based on Incomplete Profiles
Nov 02, 2024

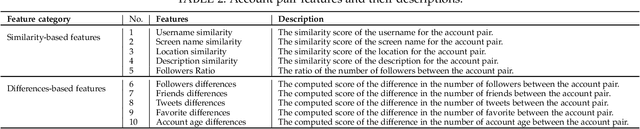

We propose a novel approach to effectively detect cloned identities of social-sensor cloud service providers (i.e. social media users) in the face of incomplete non-privacy-sensitive profile data. Named ICD-IPD, the proposed approach first extracts account pairs with similar usernames or screen names from a given set of user accounts collected from a social media. It then learns a multi-view representation associated with a given account and extracts two categories of features for every single account. These two categories of features include profile and Weighted Generalised Canonical Correlation Analysis (WGCCA)-based features that may potentially contain missing values. To counter the impact of such missing values, a missing value imputer will next impute the missing values of the aforementioned profile and WGCCA-based features. After that, the proposed approach further extracts two categories of augmented features for each account pair identified previously, namely, 1) similarity and 2) differences-based features. Finally, these features are concatenated and fed into a Light Gradient Boosting Machine classifier to detect identity cloning. We evaluated and compared the proposed approach against the existing state-of-the-art identity cloning approaches and other machine or deep learning models atop a real-world dataset. The experimental results show that the proposed approach outperforms the state-of-the-art approaches and models in terms of Precision, Recall and F1-score.
CHASE: A Causal Heterogeneous Graph based Framework for Root Cause Analysis in Multimodal Microservice Systems
Jun 28, 2024In recent years, the widespread adoption of distributed microservice architectures within the industry has significantly increased the demand for enhanced system availability and robustness. Due to the complex service invocation paths and dependencies at enterprise-level microservice systems, it is challenging to locate the anomalies promptly during service invocations, thus causing intractable issues for normal system operations and maintenance. In this paper, we propose a Causal Heterogeneous grAph baSed framEwork for root cause analysis, namely CHASE, for microservice systems with multimodal data, including traces, logs, and system monitoring metrics. Specifically, related information is encoded into representative embeddings and further modeled by a multimodal invocation graph. Following that, anomaly detection is performed on each instance node with attentive heterogeneous message passing from its adjacent metric and log nodes. Finally, CHASE learns from the constructed hypergraph with hyperedges representing the flow of causality and performs root cause localization. We evaluate the proposed framework on two public microservice datasets with distinct attributes and compare with the state-of-the-art methods. The results show that CHASE achieves the average performance gain up to 36.2%(A@1) and 29.4%(Percentage@1), respectively to its best counterpart.
FedSPU: Personalized Federated Learning for Resource-constrained Devices with Stochastic Parameter Update
Mar 18, 2024Personalized Federated Learning (PFL) is widely employed in IoT applications to handle high-volume, non-iid client data while ensuring data privacy. However, heterogeneous edge devices owned by clients may impose varying degrees of resource constraints, causing computation and communication bottlenecks for PFL. Federated Dropout has emerged as a popular strategy to address this challenge, wherein only a subset of the global model, i.e. a \textit{sub-model}, is trained on a client's device, thereby reducing computation and communication overheads. Nevertheless, the dropout-based model-pruning strategy may introduce bias, particularly towards non-iid local data. When biased sub-models absorb highly divergent parameters from other clients, performance degradation becomes inevitable. In response, we propose federated learning with stochastic parameter update (FedSPU). Unlike dropout that tailors the global model to small-size local sub-models, FedSPU maintains the full model architecture on each device but randomly freezes a certain percentage of neurons in the local model during training while updating the remaining neurons. This approach ensures that a portion of the local model remains personalized, thereby enhancing the model's robustness against biased parameters from other clients. Experimental results demonstrate that FedSPU outperforms federated dropout by 7.57\% on average in terms of accuracy. Furthermore, an introduced early stopping scheme leads to a significant reduction of the training time by \(24.8\%\sim70.4\%\) while maintaining high accuracy.
RITFIS: Robust input testing framework for LLMs-based intelligent software
Feb 21, 2024The dependence of Natural Language Processing (NLP) intelligent software on Large Language Models (LLMs) is increasingly prominent, underscoring the necessity for robustness testing. Current testing methods focus solely on the robustness of LLM-based software to prompts. Given the complexity and diversity of real-world inputs, studying the robustness of LLMbased software in handling comprehensive inputs (including prompts and examples) is crucial for a thorough understanding of its performance. To this end, this paper introduces RITFIS, a Robust Input Testing Framework for LLM-based Intelligent Software. To our knowledge, RITFIS is the first framework designed to assess the robustness of LLM-based intelligent software against natural language inputs. This framework, based on given threat models and prompts, primarily defines the testing process as a combinatorial optimization problem. Successful test cases are determined by a goal function, creating a transformation space for the original examples through perturbation means, and employing a series of search methods to filter cases that meet both the testing objectives and language constraints. RITFIS, with its modular design, offers a comprehensive method for evaluating the robustness of LLMbased intelligent software. RITFIS adapts 17 automated testing methods, originally designed for Deep Neural Network (DNN)-based intelligent software, to the LLM-based software testing scenario. It demonstrates the effectiveness of RITFIS in evaluating LLM-based intelligent software through empirical validation. However, existing methods generally have limitations, especially when dealing with lengthy texts and structurally complex threat models. Therefore, we conducted a comprehensive analysis based on five metrics and provided insightful testing method optimization strategies, benefiting both researchers and everyday users.
FLrce: Efficient Federated Learning with Relationship-based Client Selection and Early-Stopping Strategy
Oct 15, 2023Federated learning (FL) achieves great popularity in broad areas as a powerful interface to offer intelligent services to customers while maintaining data privacy. Nevertheless, FL faces communication and computation bottlenecks due to limited bandwidth and resource constraints of edge devices. To comprehensively address the bottlenecks, the technique of dropout is introduced, where resource-constrained edge devices are allowed to collaboratively train a subset of the global model parameters. However, dropout impedes the learning efficiency of FL under unbalanced local data distributions. As a result, FL requires more rounds to achieve appropriate accuracy, consuming more communication and computation resources. In this paper, we present FLrce, an efficient FL framework with a relationship-based client selection and early-stopping strategy. FLrce accelerates the FL process by selecting clients with more significant effects, enabling the global model to converge to a high accuracy in fewer rounds. FLrce also leverages an early stopping mechanism to terminate FL in advance to save communication and computation resources. Experiment results show that FLrce increases the communication and computation efficiency by 6% to 73.9% and 20% to 79.5%, respectively, while maintaining competitive accuracy.
LEAP: Efficient and Automated Test Method for NLP Software
Aug 22, 2023The widespread adoption of DNNs in NLP software has highlighted the need for robustness. Researchers proposed various automatic testing techniques for adversarial test cases. However, existing methods suffer from two limitations: weak error-discovering capabilities, with success rates ranging from 0% to 24.6% for BERT-based NLP software, and time inefficiency, taking 177.8s to 205.28s per test case, making them challenging for time-constrained scenarios. To address these issues, this paper proposes LEAP, an automated test method that uses LEvy flight-based Adaptive Particle swarm optimization integrated with textual features to generate adversarial test cases. Specifically, we adopt Levy flight for population initialization to increase the diversity of generated test cases. We also design an inertial weight adaptive update operator to improve the efficiency of LEAP's global optimization of high-dimensional text examples and a mutation operator based on the greedy strategy to reduce the search time. We conducted a series of experiments to validate LEAP's ability to test NLP software and found that the average success rate of LEAP in generating adversarial test cases is 79.1%, which is 6.1% higher than the next best approach (PSOattack). While ensuring high success rates, LEAP significantly reduces time overhead by up to 147.6s compared to other heuristic-based methods. Additionally, the experimental results demonstrate that LEAP can generate more transferable test cases and significantly enhance the robustness of DNN-based systems.
Towards Stealthy Backdoor Attacks against Speech Recognition via Elements of Sound
Jul 17, 2023Deep neural networks (DNNs) have been widely and successfully adopted and deployed in various applications of speech recognition. Recently, a few works revealed that these models are vulnerable to backdoor attacks, where the adversaries can implant malicious prediction behaviors into victim models by poisoning their training process. In this paper, we revisit poison-only backdoor attacks against speech recognition. We reveal that existing methods are not stealthy since their trigger patterns are perceptible to humans or machine detection. This limitation is mostly because their trigger patterns are simple noises or separable and distinctive clips. Motivated by these findings, we propose to exploit elements of sound ($e.g.$, pitch and timbre) to design more stealthy yet effective poison-only backdoor attacks. Specifically, we insert a short-duration high-pitched signal as the trigger and increase the pitch of remaining audio clips to `mask' it for designing stealthy pitch-based triggers. We manipulate timbre features of victim audios to design the stealthy timbre-based attack and design a voiceprint selection module to facilitate the multi-backdoor attack. Our attacks can generate more `natural' poisoned samples and therefore are more stealthy. Extensive experiments are conducted on benchmark datasets, which verify the effectiveness of our attacks under different settings ($e.g.$, all-to-one, all-to-all, clean-label, physical, and multi-backdoor settings) and their stealthiness. The code for reproducing main experiments are available at \url{https://github.com/HanboCai/BadSpeech_SoE}.