 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Contrastive Unlearning for Language Models
Mar 19, 2025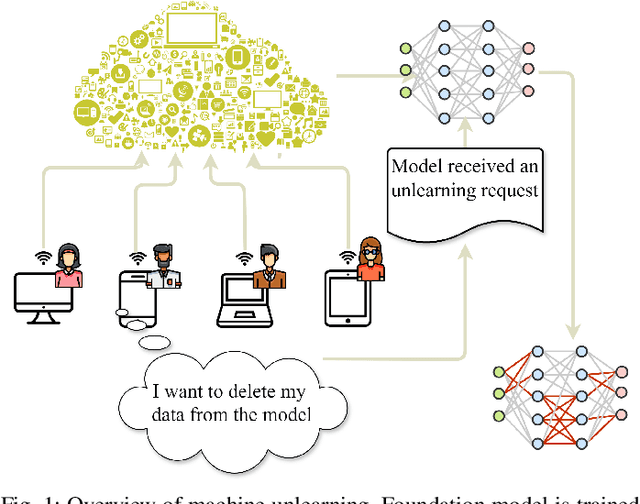
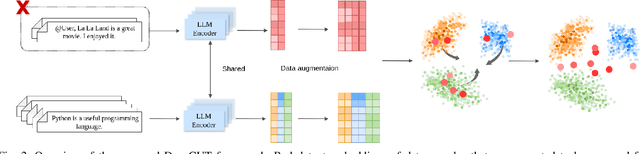
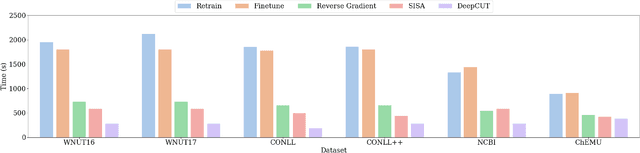
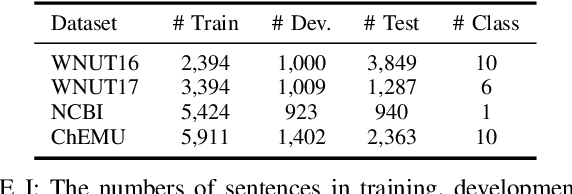
The past a few years have witnessed the great success of large language models, demonstrating powerful capabilities in comprehending textual data and generating human-like languages. Large language models achieve success by being trained on vast amounts of textual data, including online sources with copyrighted content and user-generated knowledge. However, this comes at a cost: the potential risk of exposing users' privacy and violating copyright protections. Thus, to safeguard individuals' "right to be forgotten", there has been increasing interests in machine unlearning -- the process of removing information carried by particular training samples from a model while not deteriorating its predictive quality. This is a challenging task due to the black-box nature of language models. Most existing studies focus on mitigating the impact of those forgot samples upon a model's outputs, and do not explicitly consider the geometric distributions of samples in the latent space of a model. To address this issue, we propose a machine unlearning framework, named Deep Contrastive Unlearning for fine-Tuning (DeepCUT) language models. Our proposed model achieves machine unlearning by directly optimizing the latent space of a model. Comprehensive experiments on real-world datasets demonstrate the effectiveness and efficiency of DeepCUT with consistent and significant improvement over baseline methods.
Enhancing DP-SGD through Non-monotonous Adaptive Scaling Gradient Weight
Nov 05, 2024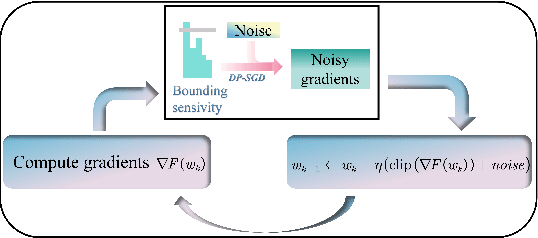
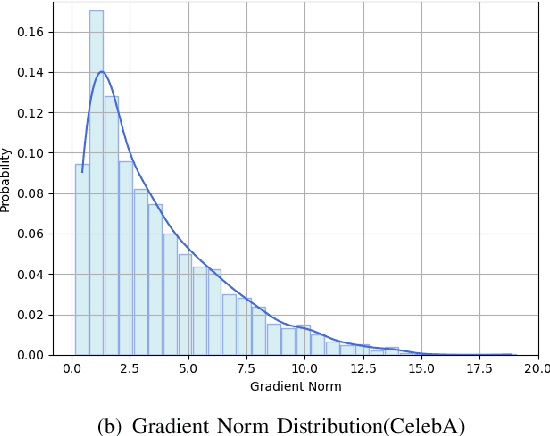
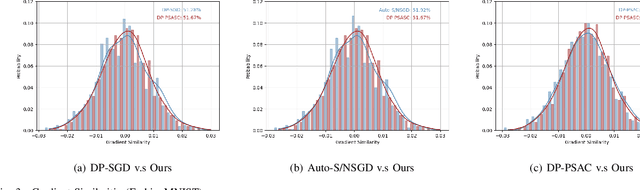
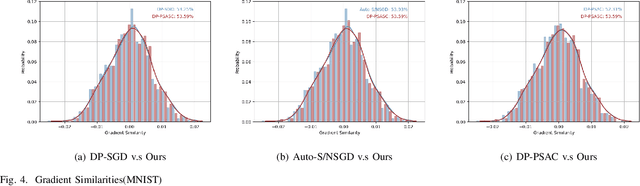
In the domain of deep learning, the challenge of protecting sensitive data while maintaining model utility is significant. Traditional Differential Privacy (DP) techniques such as Differentially Private Stochastic Gradient Descent (DP-SGD) typically employ strategies like direct or per-sample adaptive gradient clipping. These methods, however, compromise model accuracy due to their critical influence on gradient handling, particularly neglecting the significant contribution of small gradients during later training stages. In this paper, we introduce an enhanced version of DP-SGD, named Differentially Private Per-sample Adaptive Scaling Clipping (DP-PSASC). This approach replaces traditional clipping with non-monotonous adaptive gradient scaling, which alleviates the need for intensive threshold setting and rectifies the disproportionate weighting of smaller gradients. Our contribution is twofold. First, we develop a novel gradient scaling technique that effectively assigns proper weights to gradients, particularly small ones, thus improving learning under differential privacy. Second, we integrate a momentum-based method into DP-PSASC to reduce bias from stochastic sampling, enhancing convergence rates. Our theoretical and empirical analyses confirm that DP-PSASC preserves privacy and delivers superior performance across diverse datasets, setting new standards for privacy-sensitive applications.
Gradient-Guided Conditional Diffusion Models for Private Image Reconstruction: Analyzing Adversarial Impacts of Differential Privacy and Denoising
Nov 05, 2024
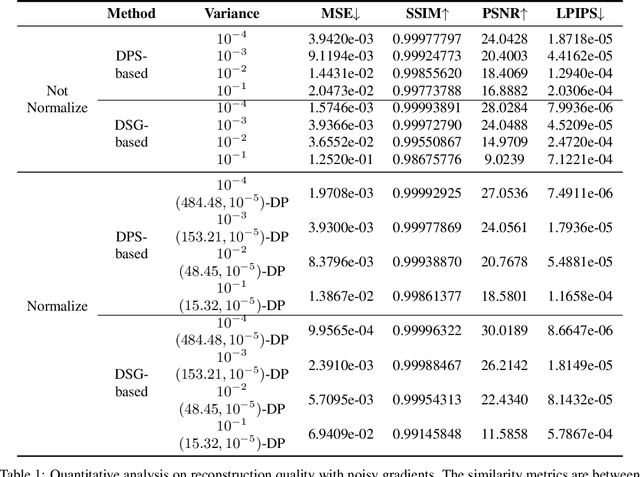
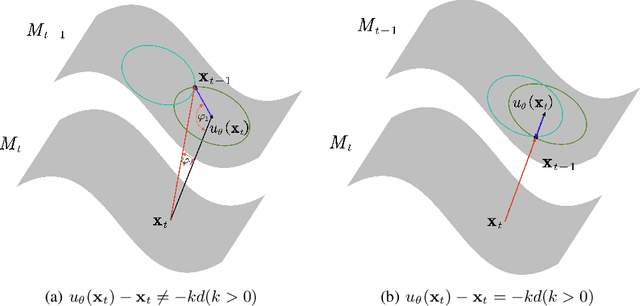
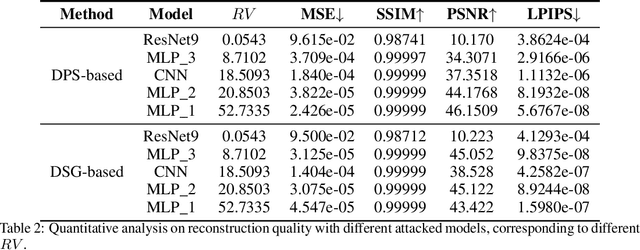
We investigate the construction of gradient-guided conditional diffusion models for reconstructing private images, focusing on the adversarial interplay between differential privacy noise and the denoising capabilities of diffusion models. While current gradient-based reconstruction methods struggle with high-resolution images due to computational complexity and prior knowledge requirements, we propose two novel methods that require minimal modifications to the diffusion model's generation process and eliminate the need for prior knowledge. Our approach leverages the strong image generation capabilities of diffusion models to reconstruct private images starting from randomly generated noise, even when a small amount of differentially private noise has been added to the gradients. We also conduct a comprehensive theoretical analysis of the impact of differential privacy noise on the quality of reconstructed images, revealing the relationship among noise magnitude, the architecture of attacked models, and the attacker's reconstruction capability. Additionally, extensive experiments validate the effectiveness of our proposed methods and the accuracy of our theoretical findings, suggesting new directions for privacy risk auditing using conditional diffusion models.
Cloned Identity Detection in Social-Sensor Clouds based on Incomplete Profiles
Nov 02, 2024

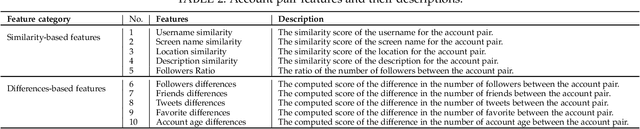

We propose a novel approach to effectively detect cloned identities of social-sensor cloud service providers (i.e. social media users) in the face of incomplete non-privacy-sensitive profile data. Named ICD-IPD, the proposed approach first extracts account pairs with similar usernames or screen names from a given set of user accounts collected from a social media. It then learns a multi-view representation associated with a given account and extracts two categories of features for every single account. These two categories of features include profile and Weighted Generalised Canonical Correlation Analysis (WGCCA)-based features that may potentially contain missing values. To counter the impact of such missing values, a missing value imputer will next impute the missing values of the aforementioned profile and WGCCA-based features. After that, the proposed approach further extracts two categories of augmented features for each account pair identified previously, namely, 1) similarity and 2) differences-based features. Finally, these features are concatenated and fed into a Light Gradient Boosting Machine classifier to detect identity cloning. We evaluated and compared the proposed approach against the existing state-of-the-art identity cloning approaches and other machine or deep learning models atop a real-world dataset. The experimental results show that the proposed approach outperforms the state-of-the-art approaches and models in terms of Precision, Recall and F1-score.
Machine Unlearning with Minimal Gradient Dependence for High Unlearning Ratios
Jun 24, 2024


In the context of machine unlearning, the primary challenge lies in effectively removing traces of private data from trained models while maintaining model performance and security against privacy attacks like membership inference attacks. Traditional gradient-based unlearning methods often rely on extensive historical gradients, which becomes impractical with high unlearning ratios and may reduce the effectiveness of unlearning. Addressing these limitations, we introduce Mini-Unlearning, a novel approach that capitalizes on a critical observation: unlearned parameters correlate with retrained parameters through contraction mapping. Our method, Mini-Unlearning, utilizes a minimal subset of historical gradients and leverages this contraction mapping to facilitate scalable, efficient unlearning. This lightweight, scalable method significantly enhances model accuracy and strengthens resistance to membership inference attacks. Our experiments demonstrate that Mini-Unlearning not only works under higher unlearning ratios but also outperforms existing techniques in both accuracy and security, offering a promising solution for applications requiring robust unlearning capabilities.
Trustworthy Privacy-preserving Hierarchical Ensemble and Federated Learning in Healthcare 4.0 with Blockchain
May 16, 2023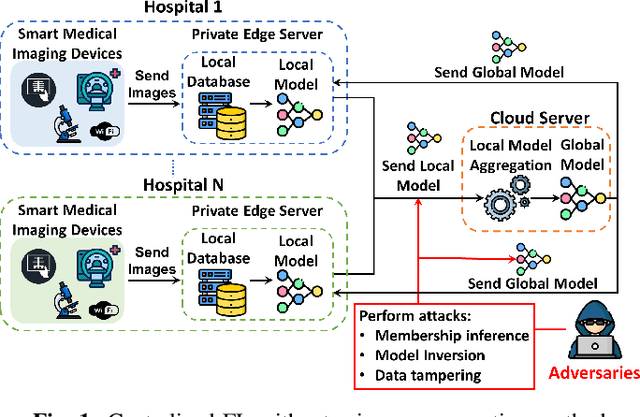
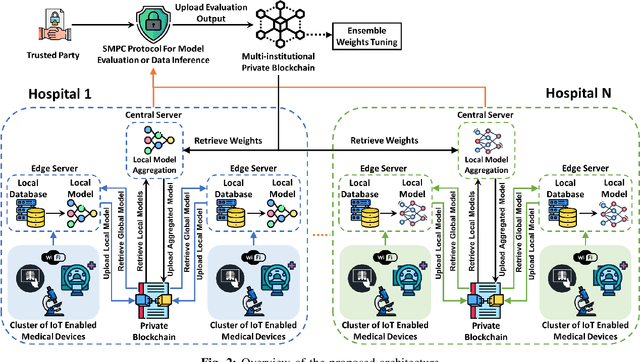
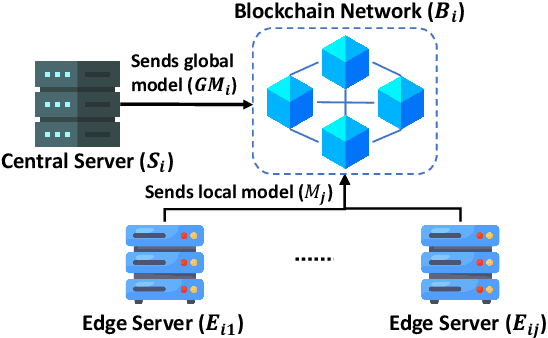
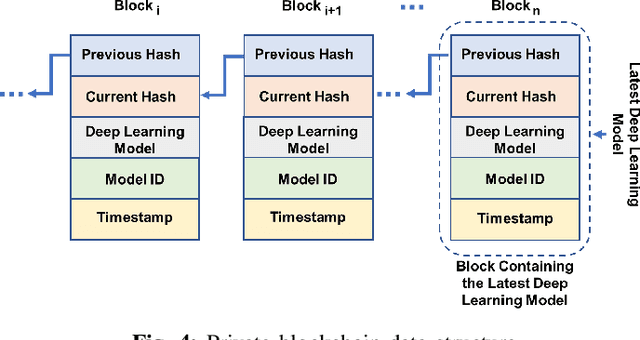
The advancement of Internet and Communication Technologies (ICTs) has led to the era of Industry 4.0. This shift is followed by healthcare industries creating the term Healthcare 4.0. In Healthcare 4.0, the use of IoT-enabled medical imaging devices for early disease detection has enabled medical practitioners to increase healthcare institutions' quality of service. However, Healthcare 4.0 is still lagging in Artificial Intelligence and big data compared to other Industry 4.0 due to data privacy concerns. In addition, institutions' diverse storage and computing capabilities restrict institutions from incorporating the same training model structure. This paper presents a secure multi-party computation-based ensemble federated learning with blockchain that enables heterogeneous models to collaboratively learn from healthcare institutions' data without violating users' privacy. Blockchain properties also allow the party to enjoy data integrity without trust in a centralized server while also providing each healthcare institution with auditability and version control capability.
Blockchain-based Federated Learning with Secure Aggregation in Trusted Execution Environment for Internet-of-Things
Apr 25, 2023



This paper proposes a blockchain-based Federated Learning (FL) framework with Intel Software Guard Extension (SGX)-based Trusted Execution Environment (TEE) to securely aggregate local models in Industrial Internet-of-Things (IIoTs). In FL, local models can be tampered with by attackers. Hence, a global model generated from the tampered local models can be erroneous. Therefore, the proposed framework leverages a blockchain network for secure model aggregation. Each blockchain node hosts an SGX-enabled processor that securely performs the FL-based aggregation tasks to generate a global model. Blockchain nodes can verify the authenticity of the aggregated model, run a blockchain consensus mechanism to ensure the integrity of the model, and add it to the distributed ledger for tamper-proof storage. Each cluster can obtain the aggregated model from the blockchain and verify its integrity before using it. We conducted several experiments with different CNN models and datasets to evaluate the performance of the proposed framework.
Committed Private Information Retrieval
Feb 03, 2023

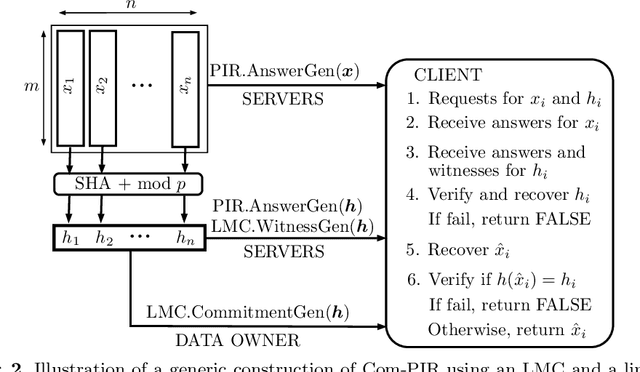

A private information retrieval (PIR) scheme allows a client to retrieve a data item $x_i$ among $n$ items $x_1,x_2,...,x_n$ from $k$ servers, without revealing what $i$ is even when $t < k$ servers collude and try to learn $i$. Such a PIR scheme is said to be $t$-private. A PIR scheme is $v$-verifiable if the client can verify the correctness of the retrieved $x_i$ even when $v \leq k$ servers collude and try to fool the client by sending manipulated data. Most of the previous works in the literature on PIR assumed that $v < k$, leaving the case of all-colluding servers open. We propose a generic construction that combines a linear map commitment (LMC) and an arbitrary linear PIR scheme to produce a $k$-verifiable PIR scheme, termed a committed PIR scheme. Such a scheme guarantees that even in the worst scenario, when all servers are under the control of an attacker, although the privacy is unavoidably lost, the client won't be fooled into accepting an incorrect $x_i$. We demonstrate the practicality of our proposal by implementing the committed PIR schemes based on the Lai-Malavolta LMC and three well-known PIR schemes using the GMP library and \texttt{blst}, the current fastest C library for elliptic curve pairings.
Aggregation Service for Federated Learning: An Efficient, Secure, and More Resilient Realization
Feb 04, 2022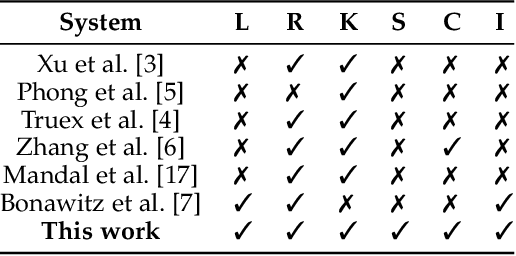
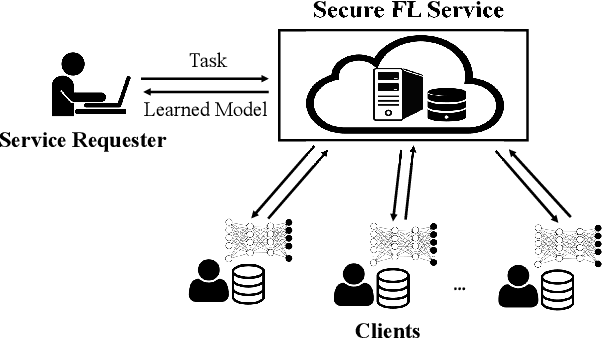

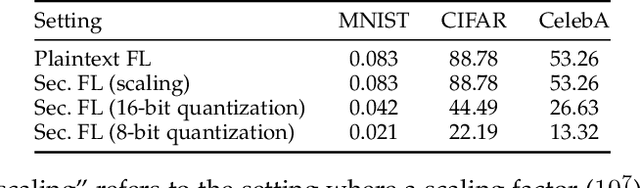
Federated learning has recently emerged as a paradigm promising the benefits of harnessing rich data from diverse sources to train high quality models, with the salient features that training datasets never leave local devices. Only model updates are locally computed and shared for aggregation to produce a global model. While federated learning greatly alleviates the privacy concerns as opposed to learning with centralized data, sharing model updates still poses privacy risks. In this paper, we present a system design which offers efficient protection of individual model updates throughout the learning procedure, allowing clients to only provide obscured model updates while a cloud server can still perform the aggregation. Our federated learning system first departs from prior works by supporting lightweight encryption and aggregation, and resilience against drop-out clients with no impact on their participation in future rounds. Meanwhile, prior work largely overlooks bandwidth efficiency optimization in the ciphertext domain and the support of security against an actively adversarial cloud server, which we also fully explore in this paper and provide effective and efficient mechanisms. Extensive experiments over several benchmark datasets (MNIST, CIFAR-10, and CelebA) show our system achieves accuracy comparable to the plaintext baseline, with practical performance.
Privacy-Aware Identity Cloning Detection based on Deep Forest
Oct 21, 2021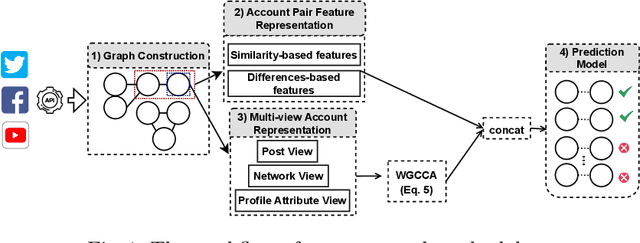
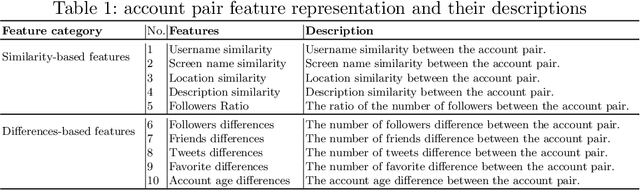

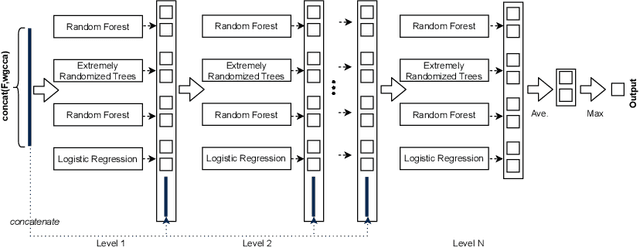
We propose a novel method to detect identity cloning of social-sensor cloud service providers to prevent the detrimental outcomes caused by identity deception. This approach leverages non-privacy-sensitive user profile data gathered from social networks and a powerful deep learning model to perform cloned identity detection. We evaluated the proposed method against the state-of-the-art identity cloning detection techniques and the other popular identity deception detection models atop a real-world dataset. The results show that our method significantly outperforms these techniques/models in terms of Precision and F1-score.