 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeMOCA: Memory-Free Continual Learning for Malicious Code Analysis
May 10, 2026As over 200 million new malware samples are identified each year, antivirus systems must continuously adapt to the evolving threat landscape. However, retraining solely on new samples leads to catastrophic forgetting and exploitable blind spots, while retraining on the entire dataset incurs substantial computational cost. We propose FreeMOCA, a memory- and compute-efficient continual learning framework for malicious code analysis that preserves prior knowledge via adaptive layer-wise interpolation between consecutive task updates, leveraging the fact that warm-started task optima are connected by low-loss paths in parameter space. We evaluate FreeMOCA in both class-incremental (Class-IL) and domain-incremental (Domain-IL) settings on large-scale Windows (EMBER) and Android (AZ) malware benchmarks. FreeMOCA achieves substantial gains in Class-IL, outperforming 11 baselines on both EMBER and AZ benchmarks. It also significantly reduces forgetting, achieving the best retention across baselines, and improving accuracy by up to 42% and 37% on EMBER and AZ, respectively. These results demonstrate that warm-started interpolation in parameter space provides a scalable and effective alternative to replay for continual malware detection. Code is available at: https://github.com/IQSeC-Lab/FreeMOCA.
Towards Quantum Machine Learning for Malicious Code Analysis
Aug 26, 2025Classical machine learning (CML) has been extensively studied for malware classification. With the emergence of quantum computing, quantum machine learning (QML) presents a paradigm-shifting opportunity to improve malware detection, though its application in this domain remains largely unexplored. In this study, we investigate two hybrid quantum-classical models -- a Quantum Multilayer Perceptron (QMLP) and a Quantum Convolutional Neural Network (QCNN), for malware classification. Both models utilize angle embedding to encode malware features into quantum states. QMLP captures complex patterns through full qubit measurement and data re-uploading, while QCNN achieves faster training via quantum convolution and pooling layers that reduce active qubits. We evaluate both models on five widely used malware datasets -- API-Graph, EMBER-Domain, EMBER-Class, AZ-Domain, and AZ-Class, across binary and multiclass classification tasks. Our results show high accuracy for binary classification -- 95-96% on API-Graph, 91-92% on AZ-Domain, and 77% on EMBER-Domain. In multiclass settings, accuracy ranges from 91.6-95.7% on API-Graph, 41.7-93.6% on AZ-Class, and 60.7-88.1% on EMBER-Class. Overall, QMLP outperforms QCNN in complex multiclass tasks, while QCNN offers improved training efficiency at the cost of reduced accuracy.
LAMDA: A Longitudinal Android Malware Benchmark for Concept Drift Analysis
May 24, 2025Machine learning (ML)-based malware detection systems often fail to account for the dynamic nature of real-world training and test data distributions. In practice, these distributions evolve due to frequent changes in the Android ecosystem, adversarial development of new malware families, and the continuous emergence of both benign and malicious applications. Prior studies have shown that such concept drift -- distributional shifts in benign and malicious samples, leads to significant degradation in detection performance over time. Despite the practical importance of this issue, existing datasets are often outdated and limited in temporal scope, diversity of malware families, and sample scale, making them insufficient for the systematic evaluation of concept drift in malware detection. To address this gap, we present LAMDA, the largest and most temporally diverse Android malware benchmark to date, designed specifically for concept drift analysis. LAMDA spans 12 years (2013-2025, excluding 2015), includes over 1 million samples (approximately 37% labeled as malware), and covers 1,380 malware families and 150,000 singleton samples, reflecting the natural distribution and evolution of real-world Android applications. We empirically demonstrate LAMDA's utility by quantifying the performance degradation of standard ML models over time and analyzing feature stability across years. As the most comprehensive Android malware dataset to date, LAMDA enables in-depth research into temporal drift, generalization, explainability, and evolving detection challenges. The dataset and code are available at: https://iqsec-lab.github.io/LAMDA/.
MalCL: Leveraging GAN-Based Generative Replay to Combat Catastrophic Forgetting in Malware Classification
Jan 02, 2025



Continual Learning (CL) for malware classification tackles the rapidly evolving nature of malware threats and the frequent emergence of new types. Generative Replay (GR)-based CL systems utilize a generative model to produce synthetic versions of past data, which are then combined with new data to retrain the primary model. Traditional machine learning techniques in this domain often struggle with catastrophic forgetting, where a model's performance on old data degrades over time. In this paper, we introduce a GR-based CL system that employs Generative Adversarial Networks (GANs) with feature matching loss to generate high-quality malware samples. Additionally, we implement innovative selection schemes for replay samples based on the model's hidden representations. Our comprehensive evaluation across Windows and Android malware datasets in a class-incremental learning scenario -- where new classes are introduced continuously over multiple tasks -- demonstrates substantial performance improvements over previous methods. For example, our system achieves an average accuracy of 55% on Windows malware samples, significantly outperforming other GR-based models by 28%. This study provides practical insights for advancing GR-based malware classification systems. The implementation is available at \url {https://github.com/MalwareReplayGAN/MalCL}\footnote{The code will be made public upon the presentation of the paper}.
* Accepted paper at AAAI 2025. 9 pages, Figure 6, Table 1
Privacy-Preserving Ensemble Infused Enhanced Deep Neural Network Framework for Edge Cloud Convergence
May 16, 2023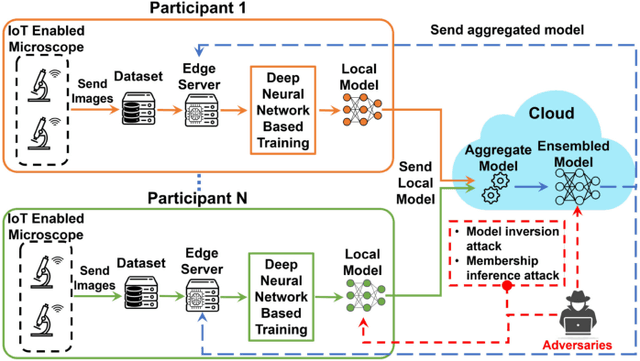
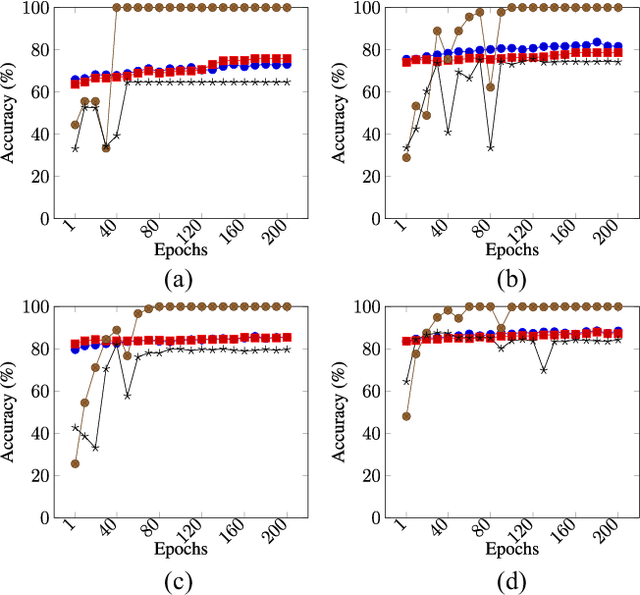
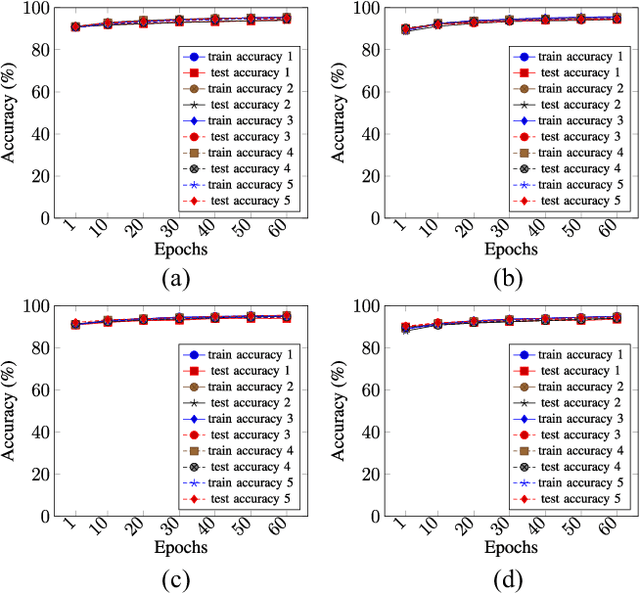
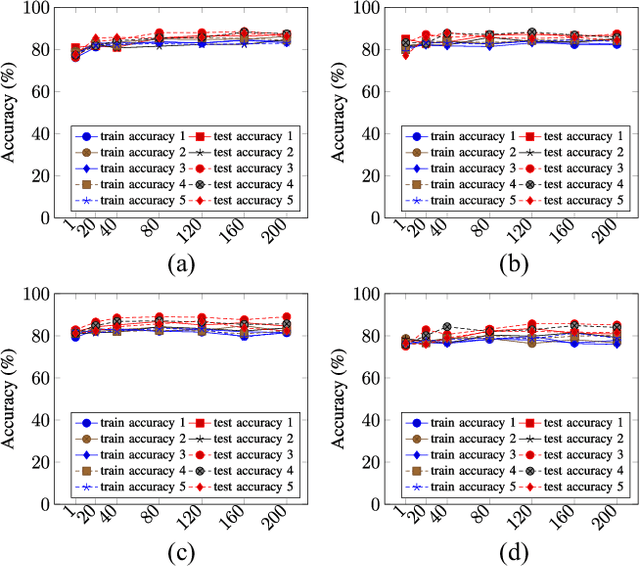
We propose a privacy-preserving ensemble infused enhanced Deep Neural Network (DNN) based learning framework in this paper for Internet-of-Things (IoT), edge, and cloud convergence in the context of healthcare. In the convergence, edge server is used for both storing IoT produced bioimage and hosting DNN algorithm for local model training. The cloud is used for ensembling local models. The DNN-based training process of a model with a local dataset suffers from low accuracy, which can be improved by the aforementioned convergence and Ensemble Learning. The ensemble learning allows multiple participants to outsource their local model for producing a generalized final model with high accuracy. Nevertheless, Ensemble Learning elevates the risk of leaking sensitive private data from the final model. The proposed framework presents a Differential Privacy-based privacy-preserving DNN with Transfer Learning for a local model generation to ensure minimal loss and higher efficiency at edge server. We conduct several experiments to evaluate the performance of our proposed framework.
Blockchain-based Access Control for Secure Smart Industry Management Systems
Apr 26, 2023Smart manufacturing systems involve a large number of interconnected devices resulting in massive data generation. Cloud computing technology has recently gained increasing attention in smart manufacturing systems for facilitating cost-effective service provisioning and massive data management. In a cloud-based manufacturing system, ensuring authorized access to the data is crucial. A cloud platform is operated under a single authority. Hence, a cloud platform is prone to a single point of failure and vulnerable to adversaries. An internal or external adversary can easily modify users' access to allow unauthorized users to access the data. This paper proposes a role-based access control to prevent modification attacks by leveraging blockchain and smart contracts in a cloud-based smart manufacturing system. The role-based access control is developed to determine users' roles and rights in smart contracts. The smart contracts are then deployed to the private blockchain network. We evaluate our solution by utilizing Ethereum private blockchain network to deploy the smart contract. The experimental results demonstrate the feasibility and evaluation of the proposed framework's performance.
Blockchain-based Federated Learning with Secure Aggregation in Trusted Execution Environment for Internet-of-Things
Apr 25, 2023



This paper proposes a blockchain-based Federated Learning (FL) framework with Intel Software Guard Extension (SGX)-based Trusted Execution Environment (TEE) to securely aggregate local models in Industrial Internet-of-Things (IIoTs). In FL, local models can be tampered with by attackers. Hence, a global model generated from the tampered local models can be erroneous. Therefore, the proposed framework leverages a blockchain network for secure model aggregation. Each blockchain node hosts an SGX-enabled processor that securely performs the FL-based aggregation tasks to generate a global model. Blockchain nodes can verify the authenticity of the aggregated model, run a blockchain consensus mechanism to ensure the integrity of the model, and add it to the distributed ledger for tamper-proof storage. Each cluster can obtain the aggregated model from the blockchain and verify its integrity before using it. We conducted several experiments with different CNN models and datasets to evaluate the performance of the proposed framework.
Transformers for End-to-End InfoSec Tasks: A Feasibility Study
Dec 05, 2022In this paper, we assess the viability of transformer models in end-to-end InfoSec settings, in which no intermediate feature representations or processing steps occur outside the model. We implement transformer models for two distinct InfoSec data formats - specifically URLs and PE files - in a novel end-to-end approach, and explore a variety of architectural designs, training regimes, and experimental settings to determine the ingredients necessary for performant detection models. We show that in contrast to conventional transformers trained on more standard NLP-related tasks, our URL transformer model requires a different training approach to reach high performance levels. Specifically, we show that 1) pre-training on a massive corpus of unlabeled URL data for an auto-regressive task does not readily transfer to binary classification of malicious or benign URLs, but 2) that using an auxiliary auto-regressive loss improves performance when training from scratch. We introduce a method for mixed objective optimization, which dynamically balances contributions from both loss terms so that neither one of them dominates. We show that this method yields quantitative evaluation metrics comparable to that of several top-performing benchmark classifiers. Unlike URLs, binary executables contain longer and more distributed sequences of information-rich bytes. To accommodate such lengthy byte sequences, we introduce additional context length into the transformer by providing its self-attention layers with an adaptive span similar to Sukhbaatar et al. We demonstrate that this approach performs comparably to well-established malware detection models on benchmark PE file datasets, but also point out the need for further exploration into model improvements in scalability and compute efficiency.
* Post-print of a manuscript accepted to ACM Asia-CCS Workshop on Robust Malware Analysis (WoRMA) 2022. 11 Pages total. arXiv admin note: substantial text overlap with arXiv:2011.03040
On the Limitations of Continual Learning for Malware Classification
Aug 13, 2022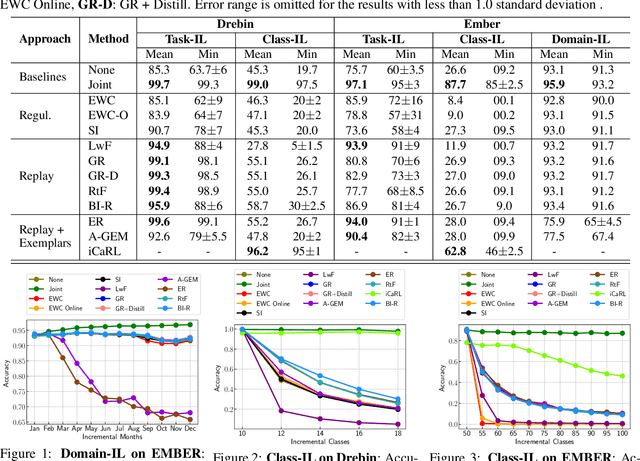

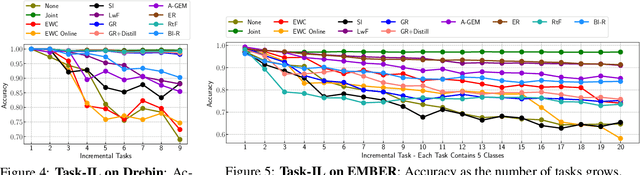
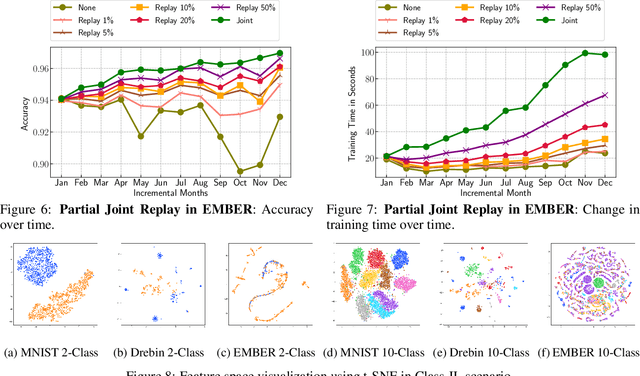
Malicious software (malware) classification offers a unique challenge for continual learning (CL) regimes due to the volume of new samples received on a daily basis and the evolution of malware to exploit new vulnerabilities. On a typical day, antivirus vendors receive hundreds of thousands of unique pieces of software, both malicious and benign, and over the course of the lifetime of a malware classifier, more than a billion samples can easily accumulate. Given the scale of the problem, sequential training using continual learning techniques could provide substantial benefits in reducing training and storage overhead. To date, however, there has been no exploration of CL applied to malware classification tasks. In this paper, we study 11 CL techniques applied to three malware tasks covering common incremental learning scenarios, including task, class, and domain incremental learning (IL). Specifically, using two realistic, large-scale malware datasets, we evaluate the performance of the CL methods on both binary malware classification (Domain-IL) and multi-class malware family classification (Task-IL and Class-IL) tasks. To our surprise, continual learning methods significantly underperformed naive Joint replay of the training data in nearly all settings -- in some cases reducing accuracy by more than 70 percentage points. A simple approach of selectively replaying 20% of the stored data achieves better performance, with 50% of the training time compared to Joint replay. Finally, we discuss potential reasons for the unexpectedly poor performance of the CL techniques, with the hope that it spurs further research on developing techniques that are more effective in the malware classification domain.