 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing the Chain: Deep Learning for Stepping-Stone Intrusion Detection
Apr 09, 2026Stepping-stone intrusions (SSIs) are a prevalent network evasion technique in which attackers route sessions through chains of compromised intermediate hosts to obscure their origin. Effective SSI detection requires correlating the incoming and outgoing flows at each relay host at extremely low false positive rates -- a stringent requirement that renders classical statistical methods inadequate in operational settings. We apply ESPRESSO, a deep learning flow correlation model combining a transformer-based feature extraction network, time-aligned multi-channel interval features, and online triplet metric learning, to the problem of stepping-stone intrusion detection. To support training and evaluation, we develop a synthetic data collection tool that generates realistic stepping-stone traffic across five tunneling protocols: SSH, SOCAT, ICMP, DNS, and mixed multi-protocol chains. Across all five protocols and in both host-mode and network-mode detection scenarios, ESPRESSO substantially outperforms the state-of-the-art DeepCoFFEA baseline, achieving a true positive rate exceeding 0.99 at a false positive rate of $10^{-3}$ for standard bursty protocols in network-mode. We further demonstrate chain length prediction as a tool for distinguishing malicious from benign pivoting, and conduct a systematic robustness analysis revealing that timing-based perturbations are the primary vulnerability of correlation-based stepping-stone detectors.
On the Limitations of Continual Learning for Malware Classification
Aug 13, 2022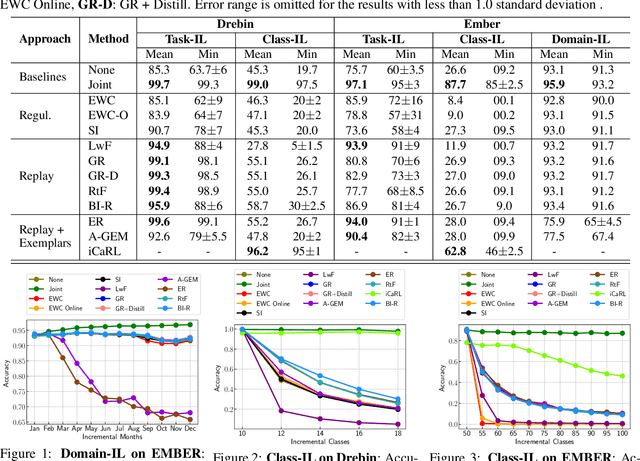

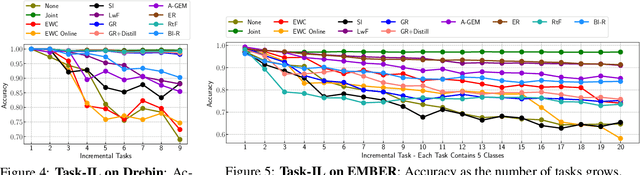
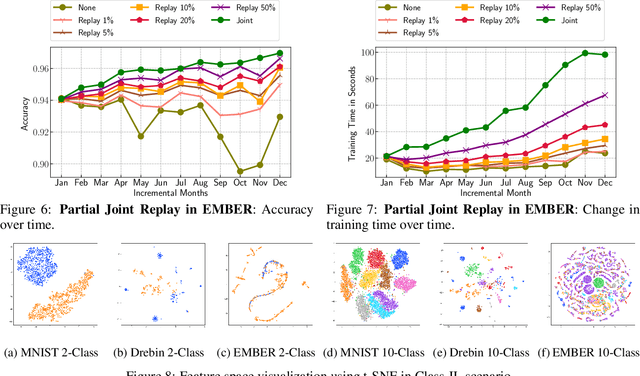
Malicious software (malware) classification offers a unique challenge for continual learning (CL) regimes due to the volume of new samples received on a daily basis and the evolution of malware to exploit new vulnerabilities. On a typical day, antivirus vendors receive hundreds of thousands of unique pieces of software, both malicious and benign, and over the course of the lifetime of a malware classifier, more than a billion samples can easily accumulate. Given the scale of the problem, sequential training using continual learning techniques could provide substantial benefits in reducing training and storage overhead. To date, however, there has been no exploration of CL applied to malware classification tasks. In this paper, we study 11 CL techniques applied to three malware tasks covering common incremental learning scenarios, including task, class, and domain incremental learning (IL). Specifically, using two realistic, large-scale malware datasets, we evaluate the performance of the CL methods on both binary malware classification (Domain-IL) and multi-class malware family classification (Task-IL and Class-IL) tasks. To our surprise, continual learning methods significantly underperformed naive Joint replay of the training data in nearly all settings -- in some cases reducing accuracy by more than 70 percentage points. A simple approach of selectively replaying 20% of the stored data achieves better performance, with 50% of the training time compared to Joint replay. Finally, we discuss potential reasons for the unexpectedly poor performance of the CL techniques, with the hope that it spurs further research on developing techniques that are more effective in the malware classification domain.
Gradient Frequency Modulation for Visually Explaining Video Understanding Models
Nov 30, 2021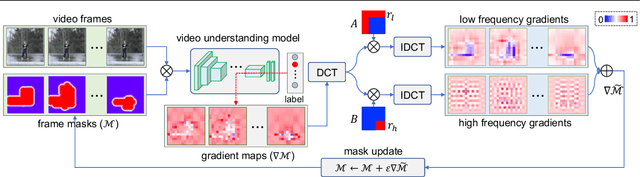



In many applications, it is essential to understand why a machine learning model makes the decisions it does, but this is inhibited by the black-box nature of state-of-the-art neural networks. Because of this, increasing attention has been paid to explainability in deep learning, including in the area of video understanding. Due to the temporal dimension of video data, the main challenge of explaining a video action recognition model is to produce spatiotemporally consistent visual explanations, which has been ignored in the existing literature. In this paper, we propose Frequency-based Extremal Perturbation (F-EP) to explain a video understanding model's decisions. Because the explanations given by perturbation methods are noisy and non-smooth both spatially and temporally, we propose to modulate the frequencies of gradient maps from the neural network model with a Discrete Cosine Transform (DCT). We show in a range of experiments that F-EP provides more spatiotemporally consistent explanations that more faithfully represent the model's decisions compared to the existing state-of-the-art methods.
Weaponizing Unicodes with Deep Learning -- Identifying Homoglyphs with Weakly Labeled Data
Oct 13, 2020



Visually similar characters, or homoglyphs, can be used to perform social engineering attacks or to evade spam and plagiarism detectors. It is thus important to understand the capabilities of an attacker to identify homoglyphs -- particularly ones that have not been previously spotted -- and leverage them in attacks. We investigate a deep-learning model using embedding learning, transfer learning, and augmentation to determine the visual similarity of characters and thereby identify potential homoglyphs. Our approach uniquely takes advantage of weak labels that arise from the fact that most characters are not homoglyphs. Our model drastically outperforms the Normalized Compression Distance approach on pairwise homoglyph identification, for which we achieve an average precision of 0.97. We also present the first attempt at clustering homoglyphs into sets of equivalence classes, which is more efficient than pairwise information for security practitioners to quickly lookup homoglyphs or to normalize confusable string encodings. To measure clustering performance, we propose a metric (mBIOU) building on the classic Intersection-Over-Union (IOU) metric. Our clustering method achieves 0.592 mBIOU, compared to 0.430 for the naive baseline. We also use our model to predict over 8,000 previously unknown homoglyphs, and find good early indications that many of these may be true positives. Source code and list of predicted homoglyphs are uploaded to Github: https://github.com/PerryXDeng/weaponizing_unicode
They Might NOT Be Giants: Crafting Black-Box Adversarial Examples with Fewer Queries Using Particle Swarm Optimization
Sep 16, 2019



Machine learning models have been found to be susceptible to adversarial examples that are often indistinguishable from the original inputs. These adversarial examples are created by applying adversarial perturbations to input samples, which would cause them to be misclassified by the target models. Attacks that search and apply the perturbations to create adversarial examples are performed in both white-box and black-box settings, depending on the information available to the attacker about the target. For black-box attacks, the only capability available to the attacker is the ability to query the target with specially crafted inputs and observing the labels returned by the model. Current black-box attacks either have low success rates, requires a high number of queries, or produce adversarial examples that are easily distinguishable from their sources. In this paper, we present AdversarialPSO, a black-box attack that uses fewer queries to create adversarial examples with high success rates. AdversarialPSO is based on the evolutionary search algorithm Particle Swarm Optimization, a populationbased gradient-free optimization algorithm. It is flexible in balancing the number of queries submitted to the target vs the quality of imperceptible adversarial examples. The attack has been evaluated using the image classification benchmark datasets CIFAR-10, MNIST, and Imagenet, achieving success rates of 99.6%, 96.3%, and 82.0%, respectively, while submitting substantially fewer queries than the state-of-the-art. We also present a black-box method for isolating salient features used by models when making classifications. This method, called Swarms with Individual Search Spaces or SWISS, creates adversarial examples by finding and modifying the most important features in the input.