 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Limitations of Continual Learning for Malware Classification
Aug 13, 2022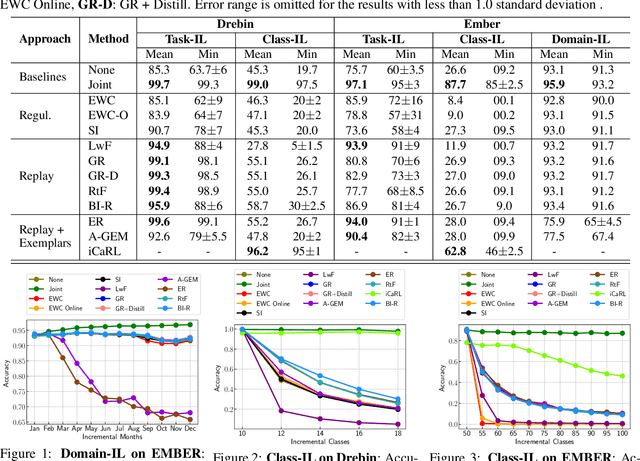

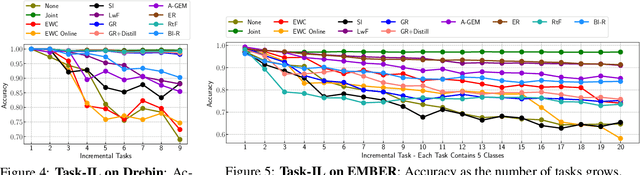
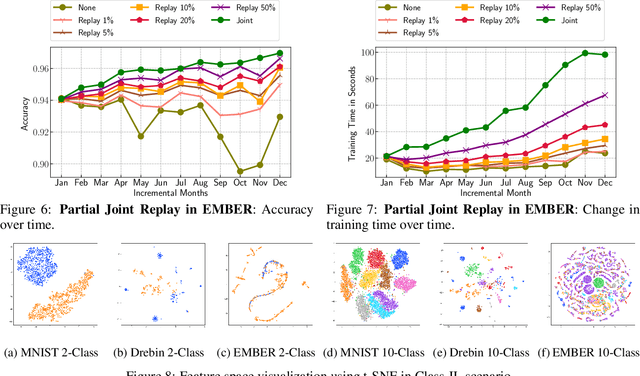
Malicious software (malware) classification offers a unique challenge for continual learning (CL) regimes due to the volume of new samples received on a daily basis and the evolution of malware to exploit new vulnerabilities. On a typical day, antivirus vendors receive hundreds of thousands of unique pieces of software, both malicious and benign, and over the course of the lifetime of a malware classifier, more than a billion samples can easily accumulate. Given the scale of the problem, sequential training using continual learning techniques could provide substantial benefits in reducing training and storage overhead. To date, however, there has been no exploration of CL applied to malware classification tasks. In this paper, we study 11 CL techniques applied to three malware tasks covering common incremental learning scenarios, including task, class, and domain incremental learning (IL). Specifically, using two realistic, large-scale malware datasets, we evaluate the performance of the CL methods on both binary malware classification (Domain-IL) and multi-class malware family classification (Task-IL and Class-IL) tasks. To our surprise, continual learning methods significantly underperformed naive Joint replay of the training data in nearly all settings -- in some cases reducing accuracy by more than 70 percentage points. A simple approach of selectively replaying 20% of the stored data achieves better performance, with 50% of the training time compared to Joint replay. Finally, we discuss potential reasons for the unexpectedly poor performance of the CL techniques, with the hope that it spurs further research on developing techniques that are more effective in the malware classification domain.
Adversarial EXEmples: A Survey and Experimental Evaluation of Practical Attacks on Machine Learning for Windows Malware Detection
Aug 17, 2020
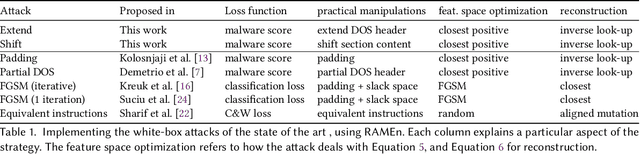

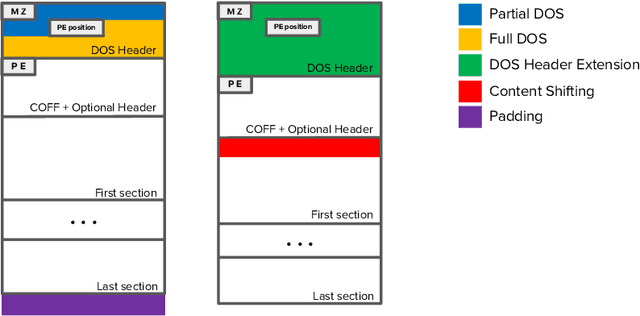
Recent work has shown that adversarial Windows malware samples - also referred to as adversarial EXEmples in this paper - can bypass machine learning-based detection relying on static code analysis by perturbing relatively few input bytes. To preserve malicious functionality, previous attacks either add bytes to existing non-functional areas of the file, potentially limiting their effectiveness, or require running computationally-demanding validation steps to discard malware variants that do not correctly execute in sandbox environments. In this work, we overcome these limitations by developing a unifying framework that not only encompasses and generalizes previous attacks against machine-learning models, but also includes two novel attacks based on practical, functionality-preserving manipulations to the Windows Portable Executable (PE) file format, based on injecting the adversarial payload by respectively extending the DOS header and shifting the content of the first section. Our experimental results show that these attacks outperform existing ones in both white-box and black-box attack scenarios by achieving a better trade-off in terms of evasion rate and size of the injected payload, as well as enabling evasion of models that were shown to be robust to previous attacks. To facilitate reproducibility and future work, we open source our framework and all the corresponding attack implementations. We conclude by discussing the limitations of current machine learning-based malware detectors, along with potential mitigation strategies based on embedding domain knowledge coming from subject-matter experts naturally into the learning process.
Activation Analysis of a Byte-Based Deep Neural Network for Malware Classification
Mar 20, 2019
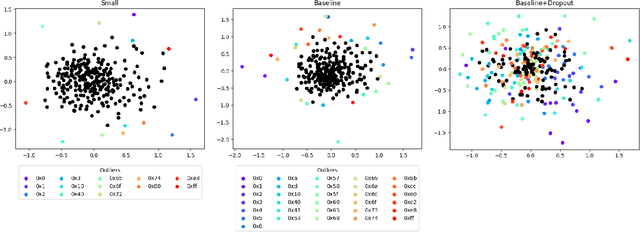
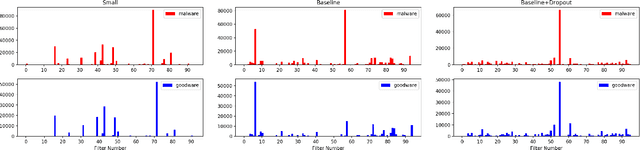
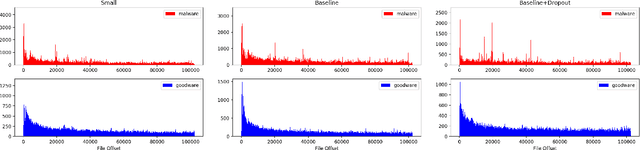
Feature engineering is one of the most costly aspects of developing effective machine learning models, and that cost is even greater in specialized problem domains, like malware classification, where expert skills are necessary to identify useful features. Recent work, however, has shown that deep learning models can be used to automatically learn feature representations directly from the raw, unstructured bytes of the binaries themselves. In this paper, we explore what these models are learning about malware. To do so, we examine the learned features at multiple levels of resolution, from individual byte embeddings to end-to-end analysis of the model. At each step, we connect these byte-oriented activations to their original semantics through parsing and disassembly of the binary to arrive at human-understandable features. Through our results, we identify several interesting features learned by the model and their connection to manually-derived features typically used by traditional machine learning models. Additionally, we explore the impact of training data volume and regularization on the quality of the learned features and the efficacy of the classifiers, revealing the somewhat paradoxical insight that better generalization does not necessarily result in better performance for byte-based malware classifiers.
Exploring Adversarial Examples in Malware Detection
Oct 18, 2018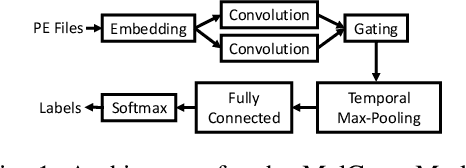

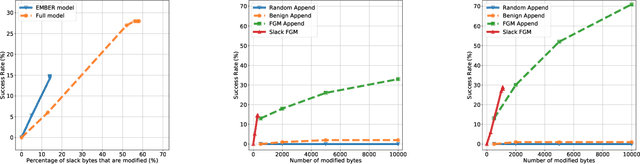

The Convolutional Neural Network (CNN) architecture is increasingly being applied to new domains, such as malware detection, where it is able to learn malicious behavior from raw bytes extracted from executables. These architectures reach impressive performance with no feature engineering effort involved, but their robustness against active attackers is yet to be understood. Such malware detectors could face a new attack vector in the form of adversarial interference with the classification model. Existing evasion attacks intended to cause misclassification on test-time instances, which have been extensively studied for image classifiers, are not applicable because of the input semantics that prevents arbitrary changes to the binaries. This paper explores the area of adversarial examples for malware detection. By training an existing model on a production-scale dataset, we show that some previous attacks are less effective than initially reported, while simultaneously highlighting architectural weaknesses that facilitate new attack strategies for malware classification. Finally, we explore more generalizable attack strategies that increase the potential effectiveness of evasion attacks.