 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Analysis of a Byte-Based Deep Neural Network for Malware Classification
Paper and Code
Mar 20, 2019
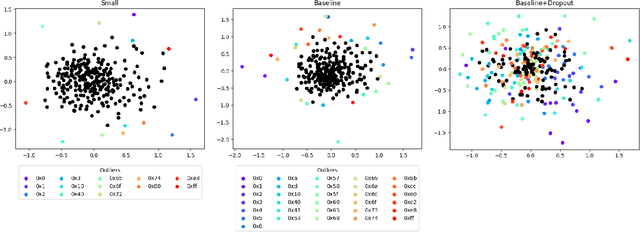
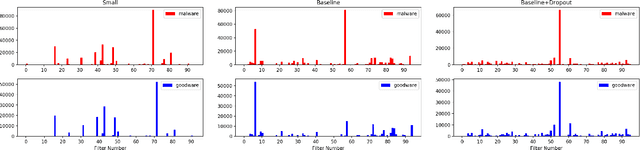
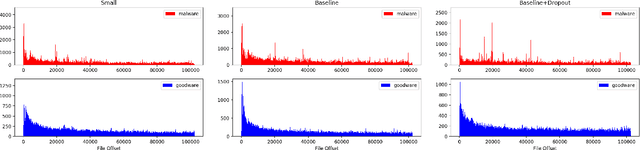
Feature engineering is one of the most costly aspects of developing effective machine learning models, and that cost is even greater in specialized problem domains, like malware classification, where expert skills are necessary to identify useful features. Recent work, however, has shown that deep learning models can be used to automatically learn feature representations directly from the raw, unstructured bytes of the binaries themselves. In this paper, we explore what these models are learning about malware. To do so, we examine the learned features at multiple levels of resolution, from individual byte embeddings to end-to-end analysis of the model. At each step, we connect these byte-oriented activations to their original semantics through parsing and disassembly of the binary to arrive at human-understandable features. Through our results, we identify several interesting features learned by the model and their connection to manually-derived features typically used by traditional machine learning models. Additionally, we explore the impact of training data volume and regularization on the quality of the learned features and the efficacy of the classifiers, revealing the somewhat paradoxical insight that better generalization does not necessarily result in better performance for byte-based malware classifiers.