 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE-5GC: Security-Aware Guidelines for Evaluating Anomaly Detection in the 5G Core Network
Feb 03, 2026Machine learning-based anomaly detection systems are increasingly being adopted in 5G Core networks to monitor complex, high-volume traffic. However, most existing approaches are evaluated under strong assumptions that rarely hold in operational environments, notably the availability of independent and identically distributed (IID) data and the absence of adaptive attackers.In this work, we study the problem of detecting 5G attacks \textit{in the wild}, focusing on realistic deployment settings. We propose a set of Security-Aware Guidelines for Evaluating anomaly detectors in 5G Core Network (SAGE-5GC), driven by domain knowledge and consideration of potential adversarial threats. Using a realistic 5G Core dataset, we first train several anomaly detectors and assess their baseline performance against standard 5GC control-plane cyberattacks targeting PFCP-based network services.We then extend the evaluation to adversarial settings, where an attacker tries to manipulate the observable features of the network traffic to evade detection, under the constraint that the intended functionality of the malicious traffic is preserved. Starting from a selected set of controllable features, we analyze model sensitivity and adversarial robustness through randomized perturbations. Finally, we introduce a practical optimization strategy based on genetic algorithms that operates exclusively on attacker-controllable features and does not require prior knowledge of the underlying detection model. Our experimental results show that adversarially crafted attacks can substantially degrade detection performance, underscoring the need for robust, security-aware evaluation methodologies for anomaly detection in 5G networks deployed in the wild.
Out-of-Distribution Detection for Continual Learning: Design Principles and Benchmarking
Dec 16, 2025



Recent years have witnessed significant progress in the development of machine learning models across a wide range of fields, fueled by increased computational resources, large-scale datasets, and the rise of deep learning architectures. From malware detection to enabling autonomous navigation, modern machine learning systems have demonstrated remarkable capabilities. However, as these models are deployed in ever-changing real-world scenarios, their ability to remain reliable and adaptive over time becomes increasingly important. For example, in the real world, new malware families are continuously developed, whereas autonomous driving cars are employed in many different cities and weather conditions. Models trained in fixed settings can not respond effectively to novel conditions encountered post-deployment. In fact, most machine learning models are still developed under the assumption that training and test data are independent and identically distributed (i.i.d.), i.e., sampled from the same underlying (unknown) distribution. While this assumption simplifies model development and evaluation, it does not hold in many real-world applications, where data changes over time and unexpected inputs frequently occur. Retraining models from scratch whenever new data appears is computationally expensive, time-consuming, and impractical in resource-constrained environments. These limitations underscore the need for Continual Learning (CL), which enables models to incrementally learn from evolving data streams without forgetting past knowledge, and Out-of-Distribution (OOD) detection, which allows systems to identify and respond to novel or anomalous inputs. Jointly addressing both challenges is critical to developing robust, efficient, and adaptive AI systems.
SOM Directions are Better than One: Multi-Directional Refusal Suppression in Language Models
Nov 13, 2025Refusal refers to the functional behavior enabling safety-aligned language models to reject harmful or unethical prompts. Following the growing scientific interest in mechanistic interpretability, recent work encoded refusal behavior as a single direction in the model's latent space; e.g., computed as the difference between the centroids of harmful and harmless prompt representations. However, emerging evidence suggests that concepts in LLMs often appear to be encoded as a low-dimensional manifold embedded in the high-dimensional latent space. Motivated by these findings, we propose a novel method leveraging Self-Organizing Maps (SOMs) to extract multiple refusal directions. To this end, we first prove that SOMs generalize the prior work's difference-in-means technique. We then train SOMs on harmful prompt representations to identify multiple neurons. By subtracting the centroid of harmless representations from each neuron, we derive a set of multiple directions expressing the refusal concept. We validate our method on an extensive experimental setup, demonstrating that ablating multiple directions from models' internals outperforms not only the single-direction baseline but also specialized jailbreak algorithms, leading to an effective suppression of refusal. Finally, we conclude by analyzing the mechanistic implications of our approach.
Exploiting Edge Features for Transferable Adversarial Attacks in Distributed Machine Learning
Jul 09, 2025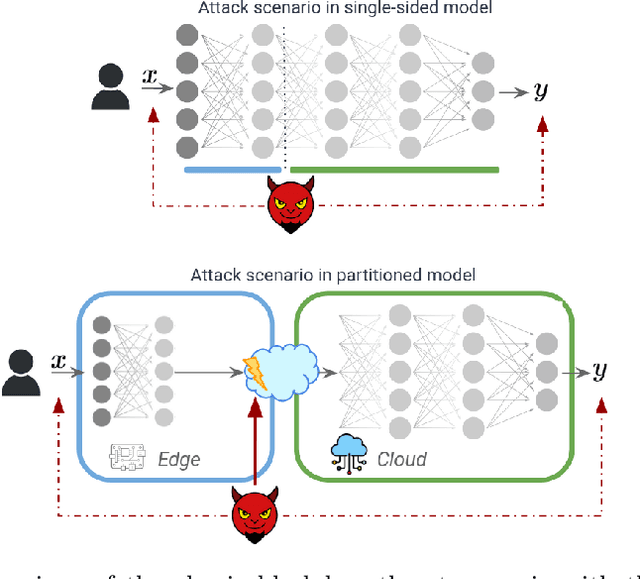
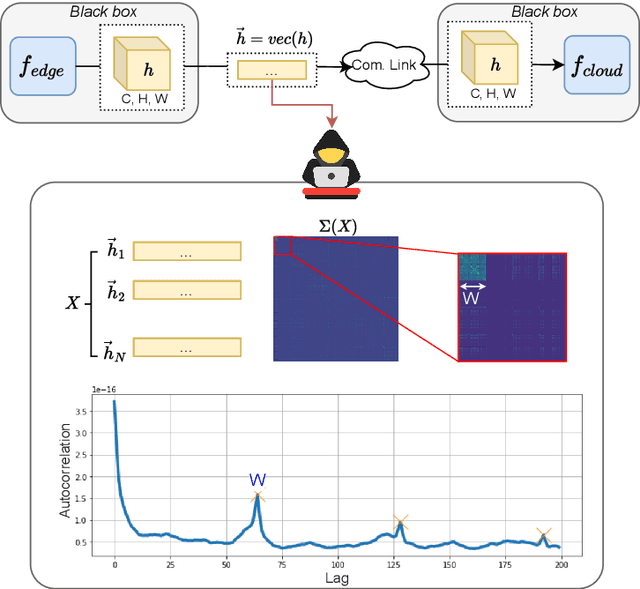
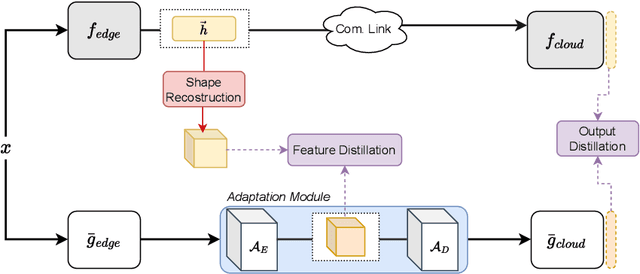
As machine learning models become increasingly deployed across the edge of internet of things environments, a partitioned deep learning paradigm in which models are split across multiple computational nodes introduces a new dimension of security risk. Unlike traditional inference setups, these distributed pipelines span the model computation across heterogeneous nodes and communication layers, thereby exposing a broader attack surface to potential adversaries. Building on these motivations, this work explores a previously overlooked vulnerability: even when both the edge and cloud components of the model are inaccessible (i.e., black-box), an adversary who intercepts the intermediate features transmitted between them can still pose a serious threat. We demonstrate that, under these mild and realistic assumptions, an attacker can craft highly transferable proxy models, making the entire deep learning system significantly more vulnerable to evasion attacks. In particular, the intercepted features can be effectively analyzed and leveraged to distill surrogate models capable of crafting highly transferable adversarial examples against the target model. To this end, we propose an exploitation strategy specifically designed for distributed settings, which involves reconstructing the original tensor shape from vectorized transmitted features using simple statistical analysis, and adapting surrogate architectures accordingly to enable effective feature distillation. A comprehensive and systematic experimental evaluation has been conducted to demonstrate that surrogate models trained with the proposed strategy, i.e., leveraging intermediate features, tremendously improve the transferability of adversarial attacks. These findings underscore the urgent need to account for intermediate feature leakage in the design of secure distributed deep learning systems.
RAID: A Dataset for Testing the Adversarial Robustness of AI-Generated Image Detectors
Jun 09, 2025AI-generated images have reached a quality level at which humans are incapable of reliably distinguishing them from real images. To counteract the inherent risk of fraud and disinformation, the detection of AI-generated images is a pressing challenge and an active research topic. While many of the presented methods claim to achieve high detection accuracy, they are usually evaluated under idealized conditions. In particular, the adversarial robustness is often neglected, potentially due to a lack of awareness or the substantial effort required to conduct a comprehensive robustness analysis. In this work, we tackle this problem by providing a simpler means to assess the robustness of AI-generated image detectors. We present RAID (Robust evaluation of AI-generated image Detectors), a dataset of 72k diverse and highly transferable adversarial examples. The dataset is created by running attacks against an ensemble of seven state-of-the-art detectors and images generated by four different text-to-image models. Extensive experiments show that our methodology generates adversarial images that transfer with a high success rate to unseen detectors, which can be used to quickly provide an approximate yet still reliable estimate of a detector's adversarial robustness. Our findings indicate that current state-of-the-art AI-generated image detectors can be easily deceived by adversarial examples, highlighting the critical need for the development of more robust methods. We release our dataset at https://huggingface.co/datasets/aimagelab/RAID and evaluation code at https://github.com/pralab/RAID.
Buffer-free Class-Incremental Learning with Out-of-Distribution Detection
May 29, 2025Class-incremental learning (CIL) poses significant challenges in open-world scenarios, where models must not only learn new classes over time without forgetting previous ones but also handle inputs from unknown classes that a closed-set model would misclassify. Recent works address both issues by (i)~training multi-head models using the task-incremental learning framework, and (ii) predicting the task identity employing out-of-distribution (OOD) detectors. While effective, the latter mainly relies on joint training with a memory buffer of past data, raising concerns around privacy, scalability, and increased training time. In this paper, we present an in-depth analysis of post-hoc OOD detection methods and investigate their potential to eliminate the need for a memory buffer. We uncover that these methods, when applied appropriately at inference time, can serve as a strong substitute for buffer-based OOD detection. We show that this buffer-free approach achieves comparable or superior performance to buffer-based methods both in terms of class-incremental learning and the rejection of unknown samples. Experimental results on CIFAR-10, CIFAR-100 and Tiny ImageNet datasets support our findings, offering new insights into the design of efficient and privacy-preserving CIL systems for open-world settings.
On the Robustness of Adversarial Training Against Uncertainty Attacks
Oct 29, 2024


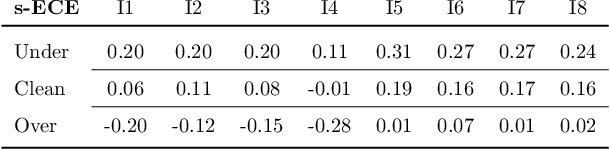
In learning problems, the noise inherent to the task at hand hinders the possibility to infer without a certain degree of uncertainty. Quantifying this uncertainty, regardless of its wide use, assumes high relevance for security-sensitive applications. Within these scenarios, it becomes fundamental to guarantee good (i.e., trustworthy) uncertainty measures, which downstream modules can securely employ to drive the final decision-making process. However, an attacker may be interested in forcing the system to produce either (i) highly uncertain outputs jeopardizing the system's availability or (ii) low uncertainty estimates, making the system accept uncertain samples that would instead require a careful inspection (e.g., human intervention). Therefore, it becomes fundamental to understand how to obtain robust uncertainty estimates against these kinds of attacks. In this work, we reveal both empirically and theoretically that defending against adversarial examples, i.e., carefully perturbed samples that cause misclassification, additionally guarantees a more secure, trustworthy uncertainty estimate under common attack scenarios without the need for an ad-hoc defense strategy. To support our claims, we evaluate multiple adversarial-robust models from the publicly available benchmark RobustBench on the CIFAR-10 and ImageNet datasets.
Adversarial Pruning: A Survey and Benchmark of Pruning Methods for Adversarial Robustness
Sep 02, 2024Recent work has proposed neural network pruning techniques to reduce the size of a network while preserving robustness against adversarial examples, i.e., well-crafted inputs inducing a misclassification. These methods, which we refer to as adversarial pruning methods, involve complex and articulated designs, making it difficult to analyze the differences and establish a fair and accurate comparison. In this work, we overcome these issues by surveying current adversarial pruning methods and proposing a novel taxonomy to categorize them based on two main dimensions: the pipeline, defining when to prune; and the specifics, defining how to prune. We then highlight the limitations of current empirical analyses and propose a novel, fair evaluation benchmark to address them. We finally conduct an empirical re-evaluation of current adversarial pruning methods and discuss the results, highlighting the shared traits of top-performing adversarial pruning methods, as well as common issues. We welcome contributions in our publicly-available benchmark at https://github.com/pralab/AdversarialPruningBenchmark
Sonic: Fast and Transferable Data Poisoning on Clustering Algorithms
Aug 14, 2024



Data poisoning attacks on clustering algorithms have received limited attention, with existing methods struggling to scale efficiently as dataset sizes and feature counts increase. These attacks typically require re-clustering the entire dataset multiple times to generate predictions and assess the attacker's objectives, significantly hindering their scalability. This paper addresses these limitations by proposing Sonic, a novel genetic data poisoning attack that leverages incremental and scalable clustering algorithms, e.g., FISHDBC, as surrogates to accelerate poisoning attacks against graph-based and density-based clustering methods, such as HDBSCAN. We empirically demonstrate the effectiveness and efficiency of Sonic in poisoning the target clustering algorithms. We then conduct a comprehensive analysis of the factors affecting the scalability and transferability of poisoning attacks against clustering algorithms, and we conclude by examining the robustness of hyperparameters in our attack strategy Sonic.
HO-FMN: Hyperparameter Optimization for Fast Minimum-Norm Attacks
Jul 11, 2024



Gradient-based attacks are a primary tool to evaluate robustness of machine-learning models. However, many attacks tend to provide overly-optimistic evaluations as they use fixed loss functions, optimizers, step-size schedulers, and default hyperparameters. In this work, we tackle these limitations by proposing a parametric variation of the well-known fast minimum-norm attack algorithm, whose loss, optimizer, step-size scheduler, and hyperparameters can be dynamically adjusted. We re-evaluate 12 robust models, showing that our attack finds smaller adversarial perturbations without requiring any additional tuning. This also enables reporting adversarial robustness as a function of the perturbation budget, providing a more complete evaluation than that offered by fixed-budget attacks, while remaining efficient. We release our open-source code at https://github.com/pralab/HO-FMN.