 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Adversarial Training Against Uncertainty Attacks
Oct 29, 2024


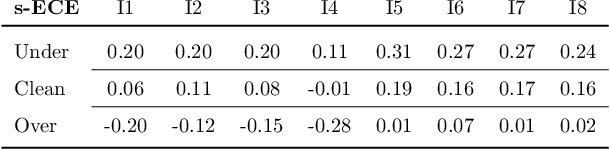
In learning problems, the noise inherent to the task at hand hinders the possibility to infer without a certain degree of uncertainty. Quantifying this uncertainty, regardless of its wide use, assumes high relevance for security-sensitive applications. Within these scenarios, it becomes fundamental to guarantee good (i.e., trustworthy) uncertainty measures, which downstream modules can securely employ to drive the final decision-making process. However, an attacker may be interested in forcing the system to produce either (i) highly uncertain outputs jeopardizing the system's availability or (ii) low uncertainty estimates, making the system accept uncertain samples that would instead require a careful inspection (e.g., human intervention). Therefore, it becomes fundamental to understand how to obtain robust uncertainty estimates against these kinds of attacks. In this work, we reveal both empirically and theoretically that defending against adversarial examples, i.e., carefully perturbed samples that cause misclassification, additionally guarantees a more secure, trustworthy uncertainty estimate under common attack scenarios without the need for an ad-hoc defense strategy. To support our claims, we evaluate multiple adversarial-robust models from the publicly available benchmark RobustBench on the CIFAR-10 and ImageNet datasets.
Adversarial Attacks Against Uncertainty Quantification
Sep 19, 2023Machine-learning models can be fooled by adversarial examples, i.e., carefully-crafted input perturbations that force models to output wrong predictions. While uncertainty quantification has been recently proposed to detect adversarial inputs, under the assumption that such attacks exhibit a higher prediction uncertainty than pristine data, it has been shown that adaptive attacks specifically aimed at reducing also the uncertainty estimate can easily bypass this defense mechanism. In this work, we focus on a different adversarial scenario in which the attacker is still interested in manipulating the uncertainty estimate, but regardless of the correctness of the prediction; in particular, the goal is to undermine the use of machine-learning models when their outputs are consumed by a downstream module or by a human operator. Following such direction, we: \textit{(i)} design a threat model for attacks targeting uncertainty quantification; \textit{(ii)} devise different attack strategies on conceptually different UQ techniques spanning for both classification and semantic segmentation problems; \textit{(iii)} conduct a first complete and extensive analysis to compare the differences between some of the most employed UQ approaches under attack. Our extensive experimental analysis shows that our attacks are more effective in manipulating uncertainty quantification measures than attacks aimed to also induce misclassifications.
Dropout Injection at Test Time for Post Hoc Uncertainty Quantification in Neural Networks
Feb 06, 2023Among Bayesian methods, Monte-Carlo dropout provides principled tools for evaluating the epistemic uncertainty of neural networks. Its popularity recently led to seminal works that proposed activating the dropout layers only during inference for evaluating uncertainty. This approach, which we call dropout injection, provides clear benefits over its traditional counterpart (which we call embedded dropout) since it allows one to obtain a post hoc uncertainty measure for any existing network previously trained without dropout, avoiding an additional, time-consuming training process. Unfortunately, no previous work compared injected and embedded dropout; therefore, we provide the first thorough investigation, focusing on regression problems. The main contribution of our work is to provide guidelines on the effective use of injected dropout so that it can be a practical alternative to the current use of embedded dropout. In particular, we show that its effectiveness strongly relies on a suitable scaling of the corresponding uncertainty measure, and we discuss the trade-off between negative log-likelihood and calibration error as a function of the scale factor. Experimental results on UCI data sets and crowd counting benchmarks support our claim that dropout injection can effectively behave as a competitive post hoc uncertainty quantification technique.
Deep Neural Rejection against Adversarial Examples
Oct 01, 2019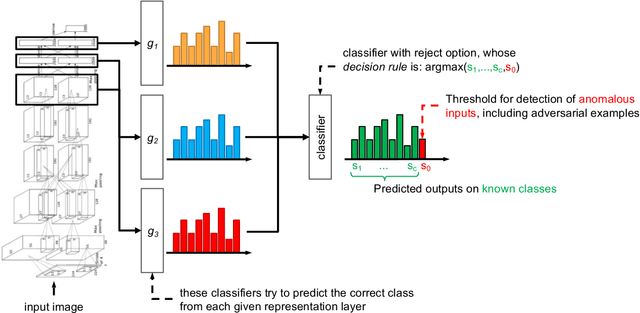
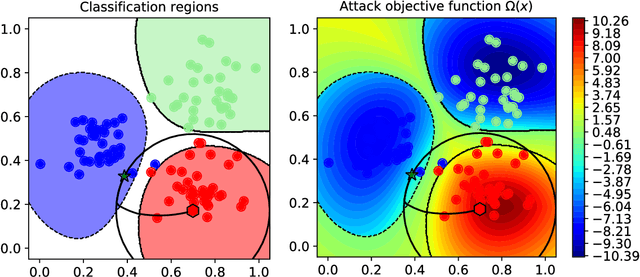
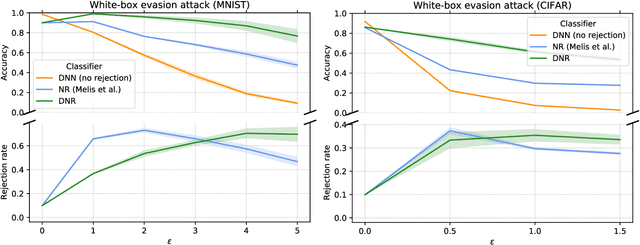
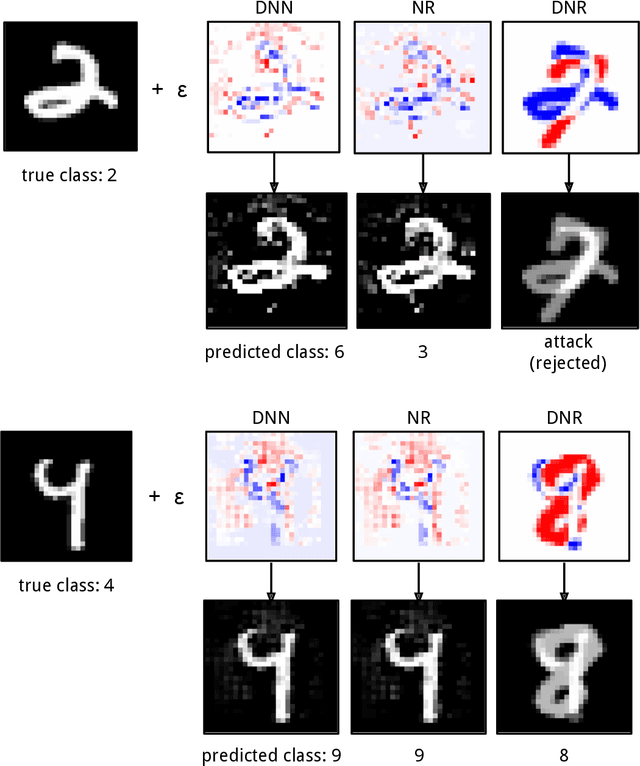
Despite the impressive performances reported by deep neural networks in different application domains, they remain largely vulnerable to adversarial examples, i.e., input samples that are carefully perturbed to cause misclassification at test time. In this work, we propose a deep neural rejection mechanism to detect adversarial examples, based on the idea of rejecting samples that exhibit anomalous feature representations at different network layers. With respect to competing approaches, our method does not require generating adversarial examples at training time, and it is less computationally demanding. To properly evaluate our method, we define an adaptive white-box attack that is aware of the defense mechanism and aims to bypass it. Under this worst-case setting, we empirically show that our approach outperforms previously-proposed methods that detect adversarial examples by only analyzing the feature representation provided by the output network layer.
Is feature selection secure against training data poisoning?
Apr 21, 2018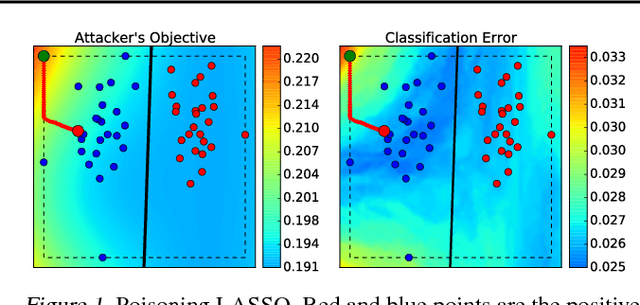
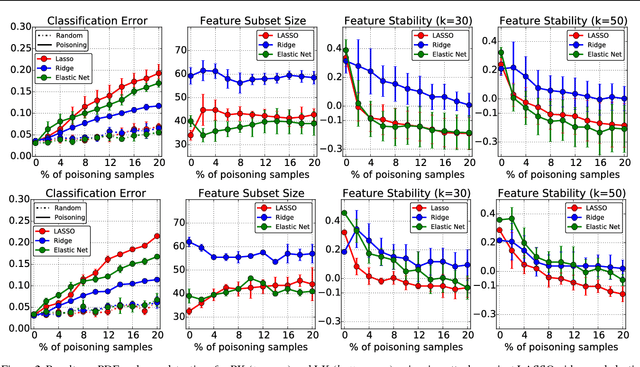
Learning in adversarial settings is becoming an important task for application domains where attackers may inject malicious data into the training set to subvert normal operation of data-driven technologies. Feature selection has been widely used in machine learning for security applications to improve generalization and computational efficiency, although it is not clear whether its use may be beneficial or even counterproductive when training data are poisoned by intelligent attackers. In this work, we shed light on this issue by providing a framework to investigate the robustness of popular feature selection methods, including LASSO, ridge regression and the elastic net. Our results on malware detection show that feature selection methods can be significantly compromised under attack (we can reduce LASSO to almost random choices of feature sets by careful insertion of less than 5% poisoned training samples), highlighting the need for specific countermeasures.
Super-sparse Learning in Similarity Spaces
Dec 17, 2017

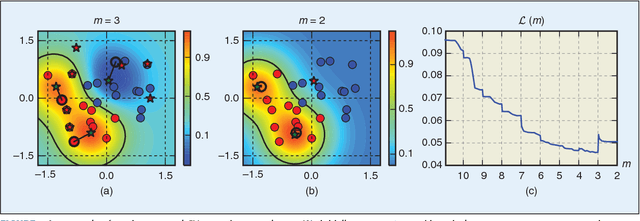

In several applications, input samples are more naturally represented in terms of similarities between each other, rather than in terms of feature vectors. In these settings, machine-learning algorithms can become very computationally demanding, as they may require matching the test samples against a very large set of reference prototypes. To mitigate this issue, different approaches have been developed to reduce the number of required reference prototypes. Current reduction approaches select a small subset of representative prototypes in the space induced by the similarity measure, and then separately train the classification function on the reduced subset. However, decoupling these two steps may not allow reducing the number of prototypes effectively without compromising accuracy. We overcome this limitation by jointly learning the classification function along with an optimal set of virtual prototypes, whose number can be either fixed a priori or optimized according to application-specific criteria. Creating a super-sparse set of virtual prototypes provides much sparser solutions, drastically reducing complexity at test time, at the expense of a slightly increased complexity during training. A much smaller set of prototypes also results in easier-to-interpret decisions. We empirically show that our approach can reduce up to ten times the complexity of Support Vector Machines, LASSO and ridge regression at test time, without almost affecting their classification accuracy.
Is Deep Learning Safe for Robot Vision? Adversarial Examples against the iCub Humanoid
Aug 23, 2017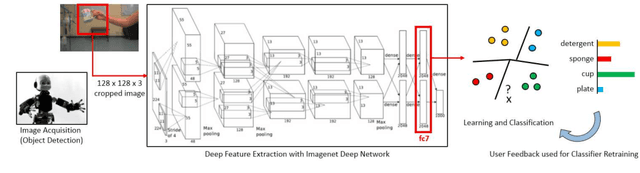



Deep neural networks have been widely adopted in recent years, exhibiting impressive performances in several application domains. It has however been shown that they can be fooled by adversarial examples, i.e., images altered by a barely-perceivable adversarial noise, carefully crafted to mislead classification. In this work, we aim to evaluate the extent to which robot-vision systems embodying deep-learning algorithms are vulnerable to adversarial examples, and propose a computationally efficient countermeasure to mitigate this threat, based on rejecting classification of anomalous inputs. We then provide a clearer understanding of the safety properties of deep networks through an intuitive empirical analysis, showing that the mapping learned by such networks essentially violates the smoothness assumption of learning algorithms. We finally discuss the main limitations of this work, including the creation of real-world adversarial examples, and sketch promising research directions.
Progressive Boosting for Class Imbalance
Jun 05, 2017
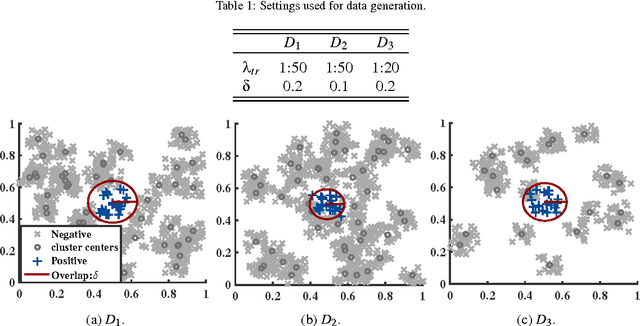


Pattern recognition applications often suffer from skewed data distributions between classes, which may vary during operations w.r.t. the design data. Two-class classification systems designed using skewed data tend to recognize the majority class better than the minority class of interest. Several data-level techniques have been proposed to alleviate this issue by up-sampling minority samples or under-sampling majority samples. However, some informative samples may be neglected by random under-sampling and adding synthetic positive samples through up-sampling adds to training complexity. In this paper, a new ensemble learning algorithm called Progressive Boosting (PBoost) is proposed that progressively inserts uncorrelated groups of samples into a Boosting procedure to avoid loss of information while generating a diverse pool of classifiers. Base classifiers in this ensemble are generated from one iteration to the next, using subsets from a validation set that grows gradually in size and imbalance. Consequently, PBoost is more robust to unknown and variable levels of skew in operational data, and has lower computation complexity than Boosting ensembles in literature. In PBoost, a new loss factor is proposed to avoid bias of performance towards the negative class. Using this loss factor, the weight update of samples and classifier contribution in final predictions are set based on the ability to recognize both classes. Using the proposed loss factor instead of standard accuracy can avoid biasing performance in any Boosting ensemble. The proposed approach was validated and compared using synthetic data, videos from the FIA dataset that emulates face re-identification applications, and KEEL collection of datasets. Results show that PBoost can outperform state of the art techniques in terms of both accuracy and complexity over different levels of imbalance and overlap between classes.
Statistical Meta-Analysis of Presentation Attacks for Secure Multibiometric Systems
Sep 06, 2016
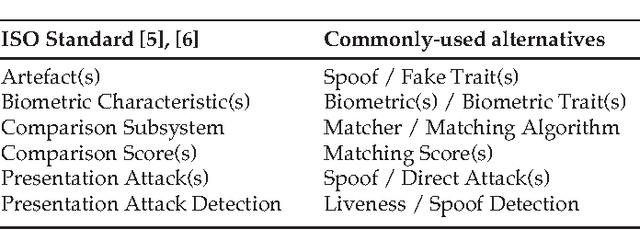

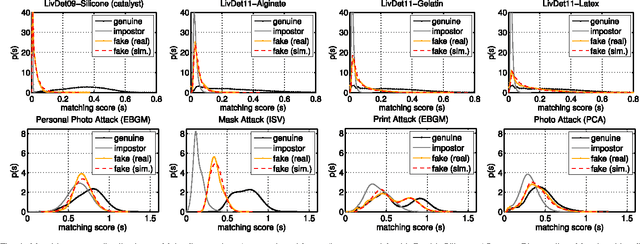
Prior work has shown that multibiometric systems are vulnerable to presentation attacks, assuming that their matching score distribution is identical to that of genuine users, without fabricating any fake trait. We have recently shown that this assumption is not representative of current fingerprint and face presentation attacks, leading one to overestimate the vulnerability of multibiometric systems, and to design less effective fusion rules. In this paper, we overcome these limitations by proposing a statistical meta-model of face and fingerprint presentation attacks that characterizes a wider family of fake score distributions, including distributions of known and, potentially, unknown attacks. This allows us to perform a thorough security evaluation of multibiometric systems against presentation attacks, quantifying how their vulnerability may vary also under attacks that are different from those considered during design, through an uncertainty analysis. We empirically show that our approach can reliably predict the performance of multibiometric systems even under never-before-seen face and fingerprint presentation attacks, and that the secure fusion rules designed using our approach can exhibit an improved trade-off between the performance in the absence and in the presence of attack. We finally argue that our method can be extended to other biometrics besides faces and fingerprints.
* Published in: IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016
Security Evaluation of Support Vector Machines in Adversarial Environments
Jan 30, 2014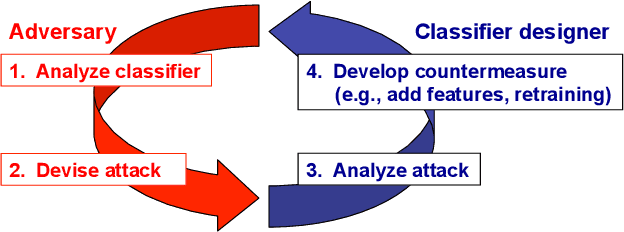
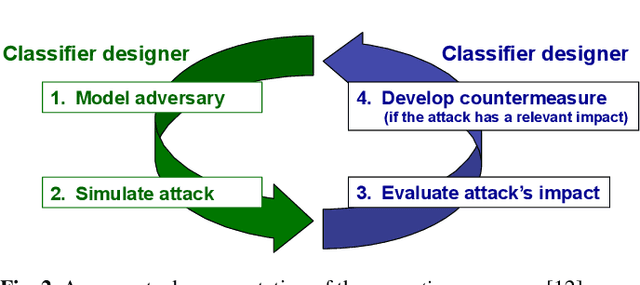
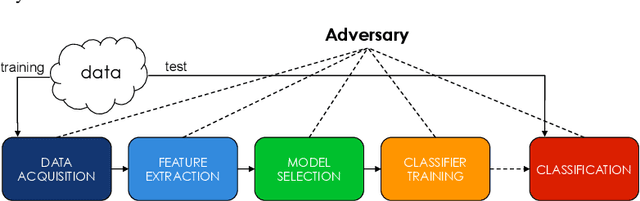
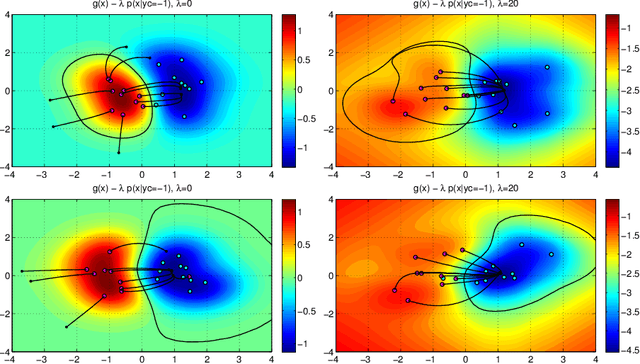
Support Vector Machines (SVMs) are among the most popular classification techniques adopted in security applications like malware detection, intrusion detection, and spam filtering. However, if SVMs are to be incorporated in real-world security systems, they must be able to cope with attack patterns that can either mislead the learning algorithm (poisoning), evade detection (evasion), or gain information about their internal parameters (privacy breaches). The main contributions of this chapter are twofold. First, we introduce a formal general framework for the empirical evaluation of the security of machine-learning systems. Second, according to our framework, we demonstrate the feasibility of evasion, poisoning and privacy attacks against SVMs in real-world security problems. For each attack technique, we evaluate its impact and discuss whether (and how) it can be countered through an adversary-aware design of SVMs. Our experiments are easily reproducible thanks to open-source code that we have made available, together with all the employed datasets, on a public repository.