 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADER: Fast Adversarial Example Rejection
Oct 18, 2020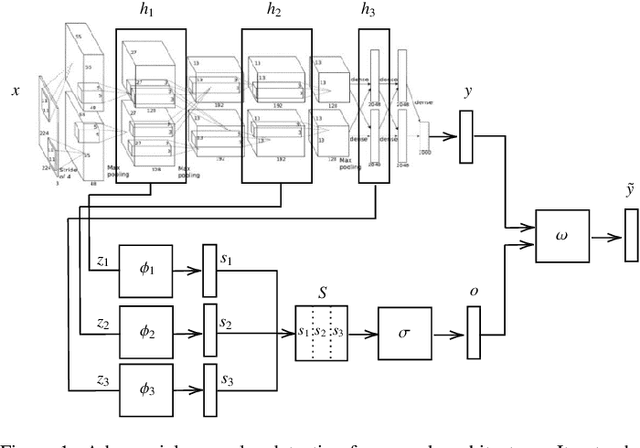
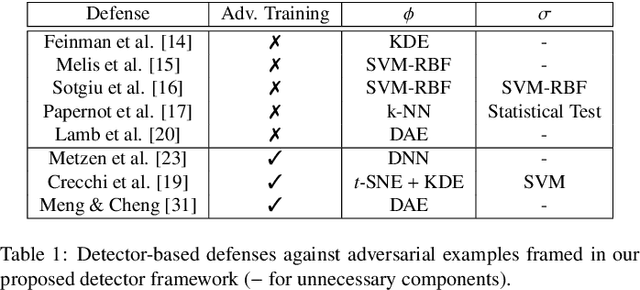
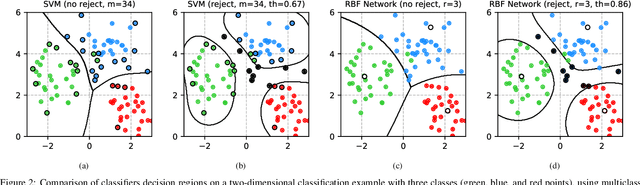

Deep neural networks are vulnerable to adversarial examples, i.e., carefully-crafted inputs that mislead classification at test time. Recent defenses have been shown to improve adversarial robustness by detecting anomalous deviations from legitimate training samples at different layer representations - a behavior normally exhibited by adversarial attacks. Despite technical differences, all aforementioned methods share a common backbone structure that we formalize and highlight in this contribution, as it can help in identifying promising research directions and drawbacks of existing methods. The first main contribution of this work is the review of these detection methods in the form of a unifying framework designed to accommodate both existing defenses and newer ones to come. In terms of drawbacks, the overmentioned defenses require comparing input samples against an oversized number of reference prototypes, possibly at different representation layers, dramatically worsening the test-time efficiency. Besides, such defenses are typically based on ensembling classifiers with heuristic methods, rather than optimizing the whole architecture in an end-to-end manner to better perform detection. As a second main contribution of this work, we introduce FADER, a novel technique for speeding up detection-based methods. FADER overcome the issues above by employing RBF networks as detectors: by fixing the number of required prototypes, the runtime complexity of adversarial examples detectors can be controlled. Our experiments outline up to 73x prototypes reduction compared to analyzed detectors for MNIST dataset and up to 50x for CIFAR10 dataset respectively, without sacrificing classification accuracy on both clean and adversarial data.
Do Gradient-based Explanations Tell Anything About Adversarial Robustness to Android Malware?
May 04, 2020

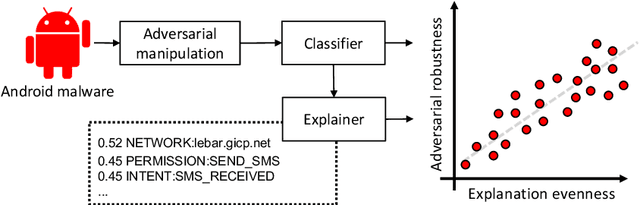
Machine-learning algorithms trained on features extracted from static code analysis can successfully detect Android malware. However, these approaches can be evaded by sparse evasion attacks that produce adversarial malware samples in which only few features are modified. This can be achieved, e.g., by injecting a small set of fake permissions and system calls into the malicious application, without compromising its intrusive functionality. To improve adversarial robustness against such sparse attacks, learning algorithms should avoid providing decisions which only rely upon a small subset of discriminant features; otherwise, even manipulating some of them may easily allow evading detection. Previous work showed that classifiers which avoid overemphasizing few discriminant features tend to be more robust against sparse attacks, and have developed simple metrics to help identify and select more robust algorithms. In this work, we aim to investigate whether gradient-based attribution methods used to explain classifiers' decisions by identifying the most relevant features can also be used to this end. Our intuition is that a classifier providing more uniform, evener attributions should rely upon a larger set of features, instead of overemphasizing few of them, thus being more robust against sparse attacks. We empirically investigate the connection between gradient-based explanations and adversarial robustness on a case study conducted on Android malware detection, and show that, in some cases, there is a strong correlation between the distribution of such explanations and adversarial robustness. We conclude the paper by discussing how our findings may thus enable the development of more efficient mechanisms both to evaluate and to improve adversarial robustness.
secml: A Python Library for Secure and Explainable Machine Learning
Dec 20, 2019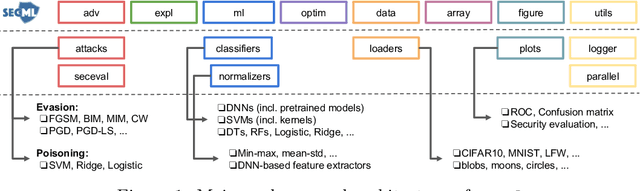

We present secml, an open-source Python library for secure and explainable machine learning. It implements the most popular attacks against machine learning, including not only test-time evasion attacks to generate adversarial examples against deep neural networks, but also training-time poisoning attacks against support vector machines and many other algorithms. These attacks enable evaluating the security of learning algorithms and of the corresponding defenses under both white-box and black-box threat models. To this end, secml provides built-in functions to compute security evaluation curves, showing how quickly classification performance decreases against increasing adversarial perturbations of the input data. secml also includes explainability methods to help understand why adversarial attacks succeed against a given model, by visualizing the most influential features and training prototypes contributing to each decision. It is distributed under the Apache License 2.0, and hosted at https://gitlab.com/secml/secml.
Deep Neural Rejection against Adversarial Examples
Oct 01, 2019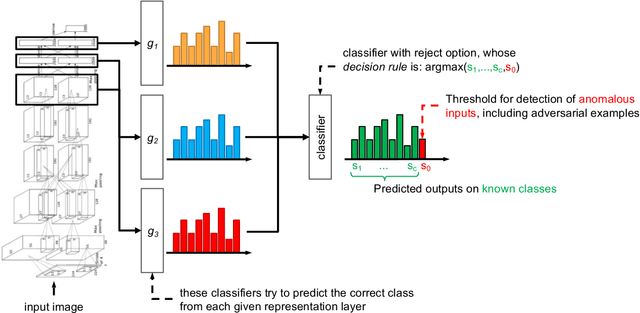
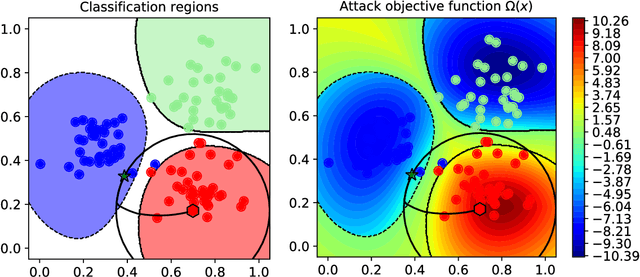
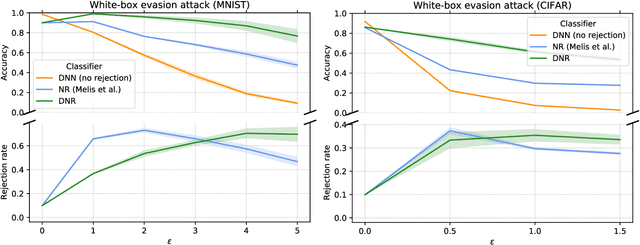
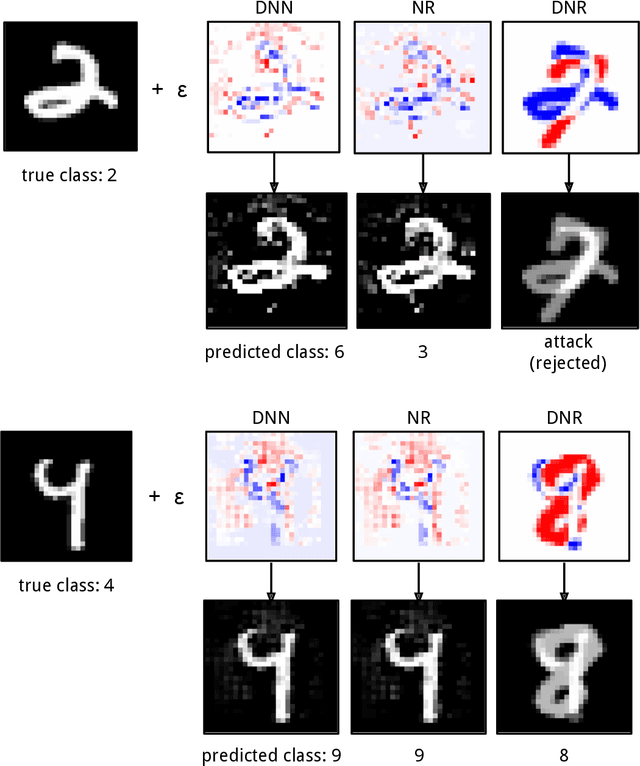
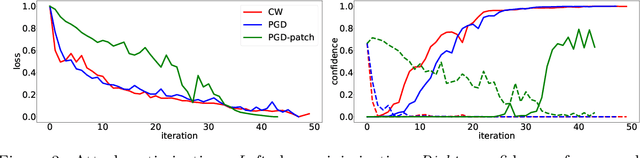
Despite the impressive performances reported by deep neural networks in different application domains, they remain largely vulnerable to adversarial examples, i.e., input samples that are carefully perturbed to cause misclassification at test time. In this work, we propose a deep neural rejection mechanism to detect adversarial examples, based on the idea of rejecting samples that exhibit anomalous feature representations at different network layers. With respect to competing approaches, our method does not require generating adversarial examples at training time, and it is less computationally demanding. To properly evaluate our method, we define an adaptive white-box attack that is aware of the defense mechanism and aims to bypass it. Under this worst-case setting, we empirically show that our approach outperforms previously-proposed methods that detect adversarial examples by only analyzing the feature representation provided by the output network layer.
Explaining Black-box Android Malware Detection
Oct 29, 2018
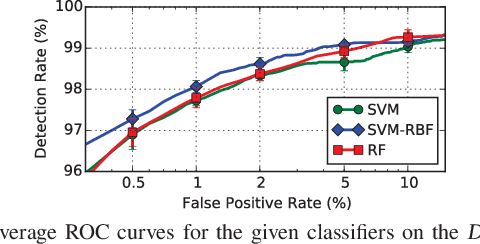
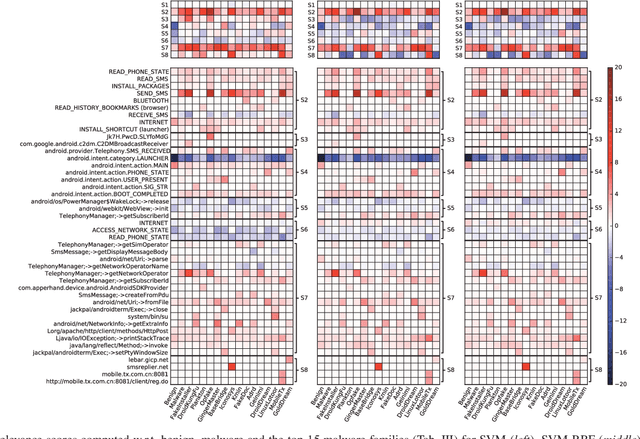

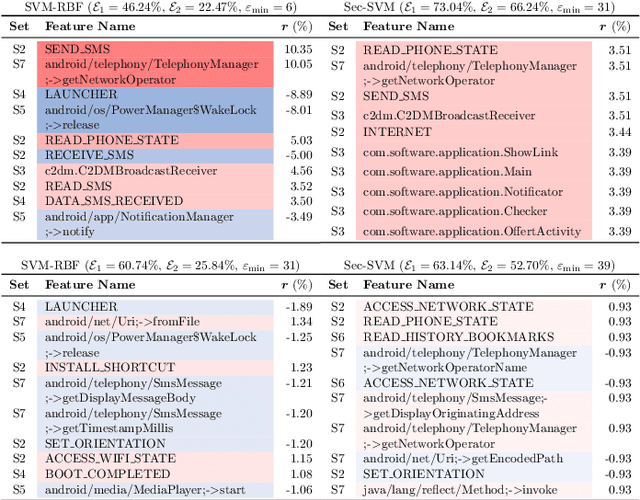
Machine-learning models have been recently used for detecting malicious Android applications, reporting impressive performances on benchmark datasets, even when trained only on features statically extracted from the application, such as system calls and permissions. However, recent findings have highlighted the fragility of such in-vitro evaluations with benchmark datasets, showing that very few changes to the content of Android malware may suffice to evade detection. How can we thus trust that a malware detector performing well on benchmark data will continue to do so when deployed in an operating environment? To mitigate this issue, the most popular Android malware detectors use linear, explainable machine-learning models to easily identify the most influential features contributing to each decision. In this work, we generalize this approach to any black-box machine- learning model, by leveraging a gradient-based approach to identify the most influential local features. This enables using nonlinear models to potentially increase accuracy without sacrificing interpretability of decisions. Our approach also highlights the global characteristics learned by the model to discriminate between benign and malware applications. Finally, as shown by our empirical analysis on a popular Android malware detection task, it also helps identifying potential vulnerabilities of linear and nonlinear models against adversarial manipulations.
On the Intriguing Connections of Regularization, Input Gradients and Transferability of Evasion and Poisoning Attacks
Sep 08, 2018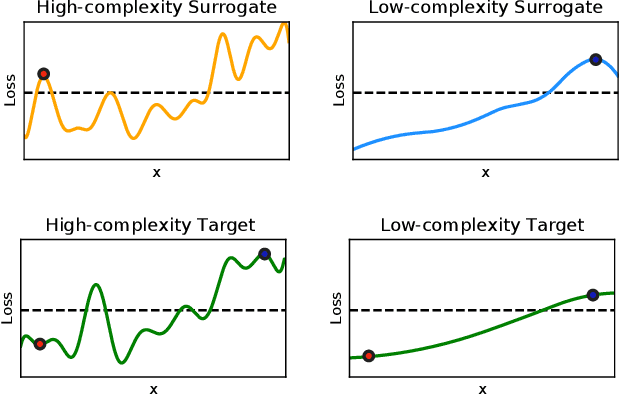
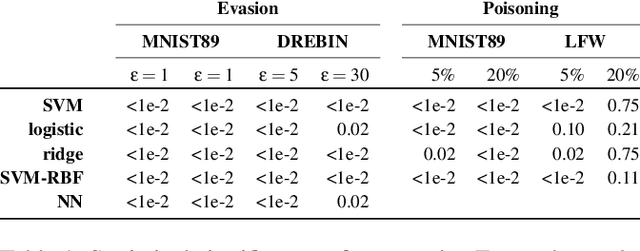

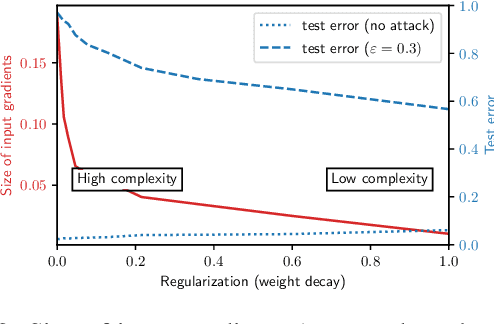
Transferability captures the ability of an attack against a machine-learning model to be effective against a different, potentially unknown, model. Studying transferability of attacks has gained interest in the last years due to the deployment of cyber-attack detection services based on machine learning. For these applications of machine learning, service providers avoid disclosing information about their machine-learning algorithms. As a result, attackers trying to bypass detection are forced to craft their attacks against a surrogate model instead of the actual target model used by the service. While previous work has shown that finding test-time transferable attack samples is possible, it is not well understood how an attacker may construct adversarial examples that are likely to transfer against different models, in particular in the case of training-time poisoning attacks. In this paper, we present the first empirical analysis aimed to investigate the transferability of both test-time evasion and training-time poisoning attacks. We provide a unifying, formal definition of transferability of such attacks and show how it relates to the input gradients of the surrogate and of the target classification models. We assess to which extent some of the most well-known machine-learning systems are vulnerable to transfer attacks, and explain why such attacks succeed (or not) across different models. To this end, we leverage some interesting connections highlighted in this work among the adversarial vulnerability of machine-learning models, their regularization hyperparameters and input gradients.
Super-sparse Learning in Similarity Spaces
Dec 17, 2017

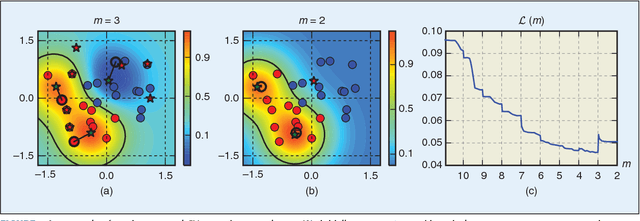

In several applications, input samples are more naturally represented in terms of similarities between each other, rather than in terms of feature vectors. In these settings, machine-learning algorithms can become very computationally demanding, as they may require matching the test samples against a very large set of reference prototypes. To mitigate this issue, different approaches have been developed to reduce the number of required reference prototypes. Current reduction approaches select a small subset of representative prototypes in the space induced by the similarity measure, and then separately train the classification function on the reduced subset. However, decoupling these two steps may not allow reducing the number of prototypes effectively without compromising accuracy. We overcome this limitation by jointly learning the classification function along with an optimal set of virtual prototypes, whose number can be either fixed a priori or optimized according to application-specific criteria. Creating a super-sparse set of virtual prototypes provides much sparser solutions, drastically reducing complexity at test time, at the expense of a slightly increased complexity during training. A much smaller set of prototypes also results in easier-to-interpret decisions. We empirically show that our approach can reduce up to ten times the complexity of Support Vector Machines, LASSO and ridge regression at test time, without almost affecting their classification accuracy.
Is Deep Learning Safe for Robot Vision? Adversarial Examples against the iCub Humanoid
Aug 23, 2017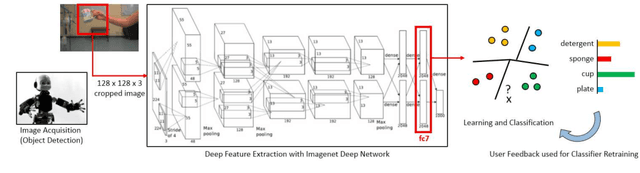



Deep neural networks have been widely adopted in recent years, exhibiting impressive performances in several application domains. It has however been shown that they can be fooled by adversarial examples, i.e., images altered by a barely-perceivable adversarial noise, carefully crafted to mislead classification. In this work, we aim to evaluate the extent to which robot-vision systems embodying deep-learning algorithms are vulnerable to adversarial examples, and propose a computationally efficient countermeasure to mitigate this threat, based on rejecting classification of anomalous inputs. We then provide a clearer understanding of the safety properties of deep networks through an intuitive empirical analysis, showing that the mapping learned by such networks essentially violates the smoothness assumption of learning algorithms. We finally discuss the main limitations of this work, including the creation of real-world adversarial examples, and sketch promising research directions.