 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution Detection for Continual Learning: Design Principles and Benchmarking
Dec 16, 2025



Recent years have witnessed significant progress in the development of machine learning models across a wide range of fields, fueled by increased computational resources, large-scale datasets, and the rise of deep learning architectures. From malware detection to enabling autonomous navigation, modern machine learning systems have demonstrated remarkable capabilities. However, as these models are deployed in ever-changing real-world scenarios, their ability to remain reliable and adaptive over time becomes increasingly important. For example, in the real world, new malware families are continuously developed, whereas autonomous driving cars are employed in many different cities and weather conditions. Models trained in fixed settings can not respond effectively to novel conditions encountered post-deployment. In fact, most machine learning models are still developed under the assumption that training and test data are independent and identically distributed (i.i.d.), i.e., sampled from the same underlying (unknown) distribution. While this assumption simplifies model development and evaluation, it does not hold in many real-world applications, where data changes over time and unexpected inputs frequently occur. Retraining models from scratch whenever new data appears is computationally expensive, time-consuming, and impractical in resource-constrained environments. These limitations underscore the need for Continual Learning (CL), which enables models to incrementally learn from evolving data streams without forgetting past knowledge, and Out-of-Distribution (OOD) detection, which allows systems to identify and respond to novel or anomalous inputs. Jointly addressing both challenges is critical to developing robust, efficient, and adaptive AI systems.
Buffer-free Class-Incremental Learning with Out-of-Distribution Detection
May 29, 2025Class-incremental learning (CIL) poses significant challenges in open-world scenarios, where models must not only learn new classes over time without forgetting previous ones but also handle inputs from unknown classes that a closed-set model would misclassify. Recent works address both issues by (i)~training multi-head models using the task-incremental learning framework, and (ii) predicting the task identity employing out-of-distribution (OOD) detectors. While effective, the latter mainly relies on joint training with a memory buffer of past data, raising concerns around privacy, scalability, and increased training time. In this paper, we present an in-depth analysis of post-hoc OOD detection methods and investigate their potential to eliminate the need for a memory buffer. We uncover that these methods, when applied appropriately at inference time, can serve as a strong substitute for buffer-based OOD detection. We show that this buffer-free approach achieves comparable or superior performance to buffer-based methods both in terms of class-incremental learning and the rejection of unknown samples. Experimental results on CIFAR-10, CIFAR-100 and Tiny ImageNet datasets support our findings, offering new insights into the design of efficient and privacy-preserving CIL systems for open-world settings.
Adversarial Pruning: A Survey and Benchmark of Pruning Methods for Adversarial Robustness
Sep 02, 2024Recent work has proposed neural network pruning techniques to reduce the size of a network while preserving robustness against adversarial examples, i.e., well-crafted inputs inducing a misclassification. These methods, which we refer to as adversarial pruning methods, involve complex and articulated designs, making it difficult to analyze the differences and establish a fair and accurate comparison. In this work, we overcome these issues by surveying current adversarial pruning methods and proposing a novel taxonomy to categorize them based on two main dimensions: the pipeline, defining when to prune; and the specifics, defining how to prune. We then highlight the limitations of current empirical analyses and propose a novel, fair evaluation benchmark to address them. We finally conduct an empirical re-evaluation of current adversarial pruning methods and discuss the results, highlighting the shared traits of top-performing adversarial pruning methods, as well as common issues. We welcome contributions in our publicly-available benchmark at https://github.com/pralab/AdversarialPruningBenchmark
HO-FMN: Hyperparameter Optimization for Fast Minimum-Norm Attacks
Jul 11, 2024



Gradient-based attacks are a primary tool to evaluate robustness of machine-learning models. However, many attacks tend to provide overly-optimistic evaluations as they use fixed loss functions, optimizers, step-size schedulers, and default hyperparameters. In this work, we tackle these limitations by proposing a parametric variation of the well-known fast minimum-norm attack algorithm, whose loss, optimizer, step-size scheduler, and hyperparameters can be dynamically adjusted. We re-evaluate 12 robust models, showing that our attack finds smaller adversarial perturbations without requiring any additional tuning. This also enables reporting adversarial robustness as a function of the perturbation budget, providing a more complete evaluation than that offered by fixed-budget attacks, while remaining efficient. We release our open-source code at https://github.com/pralab/HO-FMN.
A Hybrid Training-time and Run-time Defense Against Adversarial Attacks in Modulation Classification
Jul 09, 2024
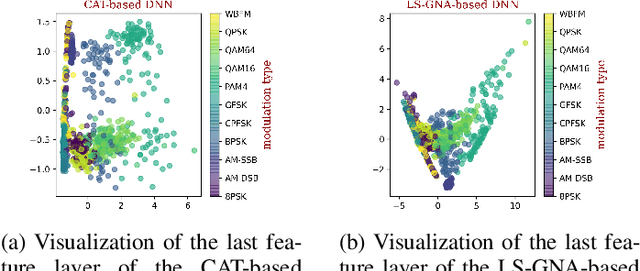
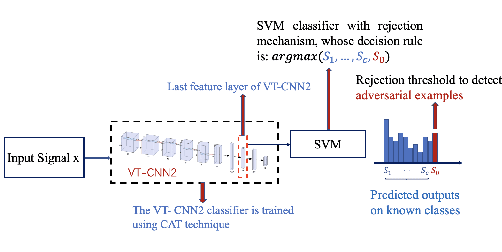
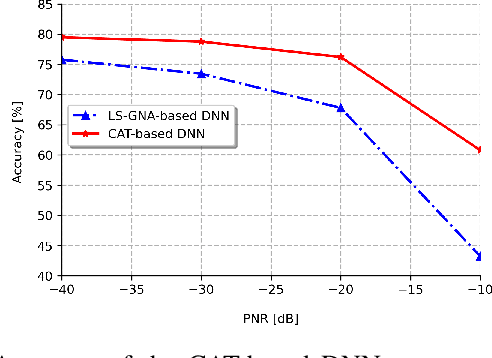
Motivated by the superior performance of deep learning in many applications including computer vision and natural language processing, several recent studies have focused on applying deep neural network for devising future generations of wireless networks. However, several recent works have pointed out that imperceptible and carefully designed adversarial examples (attacks) can significantly deteriorate the classification accuracy. In this paper, we investigate a defense mechanism based on both training-time and run-time defense techniques for protecting machine learning-based radio signal (modulation) classification against adversarial attacks. The training-time defense consists of adversarial training and label smoothing, while the run-time defense employs a support vector machine-based neural rejection (NR). Considering a white-box scenario and real datasets, we demonstrate that our proposed techniques outperform existing state-of-the-art technologies.
Over-parameterization and Adversarial Robustness in Neural Networks: An Overview and Empirical Analysis
Jun 14, 2024



Thanks to their extensive capacity, over-parameterized neural networks exhibit superior predictive capabilities and generalization. However, having a large parameter space is considered one of the main suspects of the neural networks' vulnerability to adversarial example -- input samples crafted ad-hoc to induce a desired misclassification. Relevant literature has claimed contradictory remarks in support of and against the robustness of over-parameterized networks. These contradictory findings might be due to the failure of the attack employed to evaluate the networks' robustness. Previous research has demonstrated that depending on the considered model, the algorithm employed to generate adversarial examples may not function properly, leading to overestimating the model's robustness. In this work, we empirically study the robustness of over-parameterized networks against adversarial examples. However, unlike the previous works, we also evaluate the considered attack's reliability to support the results' veracity. Our results show that over-parameterized networks are robust against adversarial attacks as opposed to their under-parameterized counterparts.
AttackBench: Evaluating Gradient-based Attacks for Adversarial Examples
Apr 30, 2024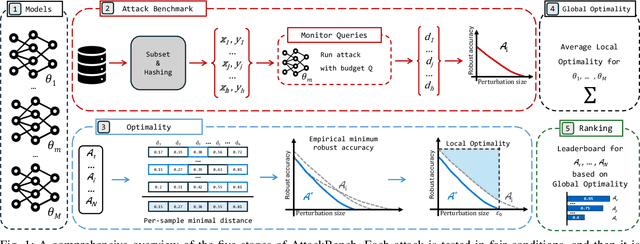
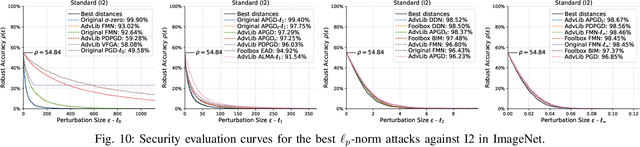
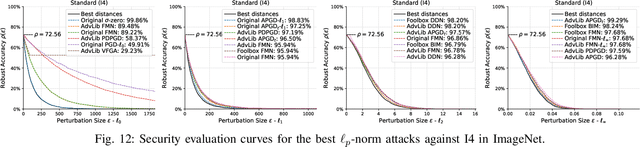
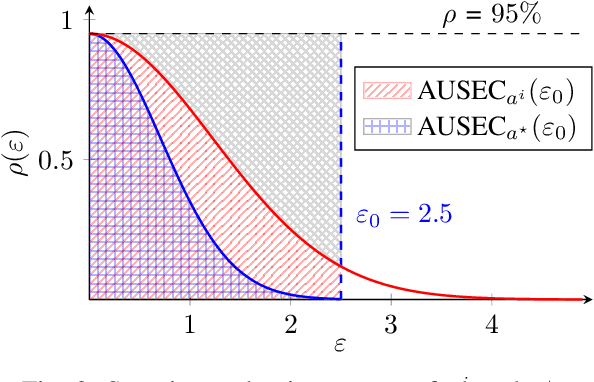
Adversarial examples are typically optimized with gradient-based attacks. While novel attacks are continuously proposed, each is shown to outperform its predecessors using different experimental setups, hyperparameter settings, and number of forward and backward calls to the target models. This provides overly-optimistic and even biased evaluations that may unfairly favor one particular attack over the others. In this work, we aim to overcome these limitations by proposing AttackBench, i.e., the first evaluation framework that enables a fair comparison among different attacks. To this end, we first propose a categorization of gradient-based attacks, identifying their main components and differences. We then introduce our framework, which evaluates their effectiveness and efficiency. We measure these characteristics by (i) defining an optimality metric that quantifies how close an attack is to the optimal solution, and (ii) limiting the number of forward and backward queries to the model, such that all attacks are compared within a given maximum query budget. Our extensive experimental analysis compares more than 100 attack implementations with a total of over 800 different configurations against CIFAR-10 and ImageNet models, highlighting that only very few attacks outperform all the competing approaches. Within this analysis, we shed light on several implementation issues that prevent many attacks from finding better solutions or running at all. We release AttackBench as a publicly available benchmark, aiming to continuously update it to include and evaluate novel gradient-based attacks for optimizing adversarial examples.
Improving Fast Minimum-Norm Attacks with Hyperparameter Optimization
Oct 12, 2023

Evaluating the adversarial robustness of machine learning models using gradient-based attacks is challenging. In this work, we show that hyperparameter optimization can improve fast minimum-norm attacks by automating the selection of the loss function, the optimizer and the step-size scheduler, along with the corresponding hyperparameters. Our extensive evaluation involving several robust models demonstrates the improved efficacy of fast minimum-norm attacks when hyper-up with hyperparameter optimization. We release our open-source code at https://github.com/pralab/HO-FMN.
Samples on Thin Ice: Re-Evaluating Adversarial Pruning of Neural Networks
Oct 12, 2023Neural network pruning has shown to be an effective technique for reducing the network size, trading desirable properties like generalization and robustness to adversarial attacks for higher sparsity. Recent work has claimed that adversarial pruning methods can produce sparse networks while also preserving robustness to adversarial examples. In this work, we first re-evaluate three state-of-the-art adversarial pruning methods, showing that their robustness was indeed overestimated. We then compare pruned and dense versions of the same models, discovering that samples on thin ice, i.e., closer to the unpruned model's decision boundary, are typically misclassified after pruning. We conclude by discussing how this intuition may lead to designing more effective adversarial pruning methods in future work.
Hardening RGB-D Object Recognition Systems against Adversarial Patch Attacks
Sep 13, 2023



RGB-D object recognition systems improve their predictive performances by fusing color and depth information, outperforming neural network architectures that rely solely on colors. While RGB-D systems are expected to be more robust to adversarial examples than RGB-only systems, they have also been proven to be highly vulnerable. Their robustness is similar even when the adversarial examples are generated by altering only the original images' colors. Different works highlighted the vulnerability of RGB-D systems; however, there is a lacking of technical explanations for this weakness. Hence, in our work, we bridge this gap by investigating the learned deep representation of RGB-D systems, discovering that color features make the function learned by the network more complex and, thus, more sensitive to small perturbations. To mitigate this problem, we propose a defense based on a detection mechanism that makes RGB-D systems more robust against adversarial examples. We empirically show that this defense improves the performances of RGB-D systems against adversarial examples even when they are computed ad-hoc to circumvent this detection mechanism, and that is also more effective than adversarial training.