 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-space Attacks for Refusal Evasion in Language Models
May 20, 2026Safety-aligned language models are trained to refuse harmful requests, yet refusal behavior can be suppressed by steering their internal representations. Existing methods do so by ablating a refusal direction from model activations, aiming to remove refusal from the model's residual stream. Despite their empirical success, these methods lack a principled account of the latent-space transformation they induce and why it suppresses refusal. In this work, we recast refusal suppression as a latent-space evasion attack against linear probes trained to separate refused from answered prompts. Under this view, prior work's difference-in-means direction naturally defines such a probe, and its ablation is exactly a projection onto its decision boundary, i.e., a minimum-confidence evasion attack. This perspective not only explains the empirical success of prior work but also admits a key limitation: evasion stops at the decision boundary, motivating the need to push representations further into the compliant region, i.e., where the model answers. We leverage this by proposing a Controlled Latent-space Evasion attack that projects representations past the boundary with an optimized confidence. We achieve state-of-the-art attack success rate across 15 instruction-tuned, multimodal, and reasoning models, outperforming existing refusal-ablation baselines and specialized jailbreak attacks.
SOM Directions are Better than One: Multi-Directional Refusal Suppression in Language Models
Nov 13, 2025Refusal refers to the functional behavior enabling safety-aligned language models to reject harmful or unethical prompts. Following the growing scientific interest in mechanistic interpretability, recent work encoded refusal behavior as a single direction in the model's latent space; e.g., computed as the difference between the centroids of harmful and harmless prompt representations. However, emerging evidence suggests that concepts in LLMs often appear to be encoded as a low-dimensional manifold embedded in the high-dimensional latent space. Motivated by these findings, we propose a novel method leveraging Self-Organizing Maps (SOMs) to extract multiple refusal directions. To this end, we first prove that SOMs generalize the prior work's difference-in-means technique. We then train SOMs on harmful prompt representations to identify multiple neurons. By subtracting the centroid of harmless representations from each neuron, we derive a set of multiple directions expressing the refusal concept. We validate our method on an extensive experimental setup, demonstrating that ablating multiple directions from models' internals outperforms not only the single-direction baseline but also specialized jailbreak algorithms, leading to an effective suppression of refusal. Finally, we conclude by analyzing the mechanistic implications of our approach.
Empirical Quantification of Spurious Correlations in Malware Detection
Jun 11, 2025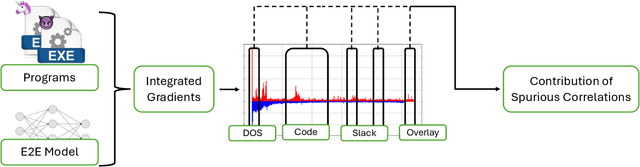
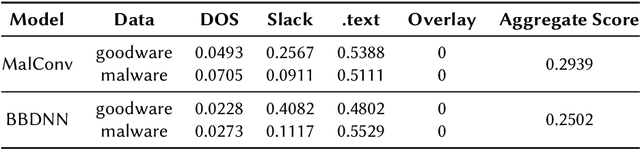
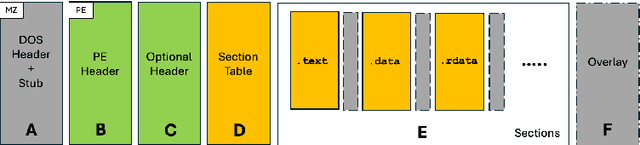
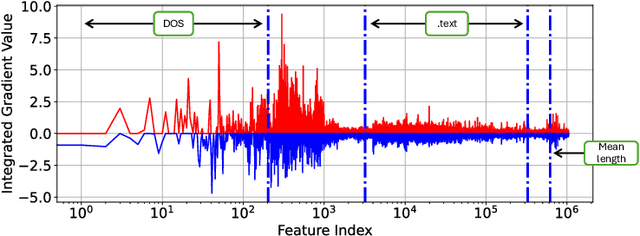
End-to-end deep learning exhibits unmatched performance for detecting malware, but such an achievement is reached by exploiting spurious correlations -- features with high relevance at inference time, but known to be useless through domain knowledge. While previous work highlighted that deep networks mainly focus on metadata, none investigated the phenomenon further, without quantifying their impact on the decision. In this work, we deepen our understanding of how spurious correlation affects deep learning for malware detection by highlighting how much models rely on empty spaces left by the compiler, which diminishes the relevance of the compiled code. Through our seminal analysis on a small-scale balanced dataset, we introduce a ranking of two end-to-end models to better understand which is more suitable to be put in production.
Training-Free Constrained Generation With Stable Diffusion Models
Feb 08, 2025Stable diffusion models represent the state-of-the-art in data synthesis across diverse domains and hold transformative potential for applications in science and engineering, e.g., by facilitating the discovery of novel solutions and simulating systems that are computationally intractable to model explicitly. However, their current utility in these fields is severely limited by an inability to enforce strict adherence to physical laws and domain-specific constraints. Without this grounding, the deployment of such models in critical applications, ranging from material science to safety-critical systems, remains impractical. This paper addresses this fundamental limitation by proposing a novel approach to integrate stable diffusion models with constrained optimization frameworks, enabling them to generate outputs that satisfy stringent physical and functional requirements. We demonstrate the effectiveness of this approach through material science experiments requiring adherence to precise morphometric properties, inverse design problems involving the generation of stress-strain responses using video generation with a simulator in the loop, and safety settings where outputs must avoid copyright infringement.
Over-parameterization and Adversarial Robustness in Neural Networks: An Overview and Empirical Analysis
Jun 14, 2024



Thanks to their extensive capacity, over-parameterized neural networks exhibit superior predictive capabilities and generalization. However, having a large parameter space is considered one of the main suspects of the neural networks' vulnerability to adversarial example -- input samples crafted ad-hoc to induce a desired misclassification. Relevant literature has claimed contradictory remarks in support of and against the robustness of over-parameterized networks. These contradictory findings might be due to the failure of the attack employed to evaluate the networks' robustness. Previous research has demonstrated that depending on the considered model, the algorithm employed to generate adversarial examples may not function properly, leading to overestimating the model's robustness. In this work, we empirically study the robustness of over-parameterized networks against adversarial examples. However, unlike the previous works, we also evaluate the considered attack's reliability to support the results' veracity. Our results show that over-parameterized networks are robust against adversarial attacks as opposed to their under-parameterized counterparts.
Robustness-Congruent Adversarial Training for Secure Machine Learning Model Updates
Feb 27, 2024



Machine-learning models demand for periodic updates to improve their average accuracy, exploiting novel architectures and additional data. However, a newly-updated model may commit mistakes that the previous model did not make. Such misclassifications are referred to as negative flips, and experienced by users as a regression of performance. In this work, we show that this problem also affects robustness to adversarial examples, thereby hindering the development of secure model update practices. In particular, when updating a model to improve its adversarial robustness, some previously-ineffective adversarial examples may become misclassified, causing a regression in the perceived security of the system. We propose a novel technique, named robustness-congruent adversarial training, to address this issue. It amounts to fine-tuning a model with adversarial training, while constraining it to retain higher robustness on the adversarial examples that were correctly classified before the update. We show that our algorithm and, more generally, learning with non-regression constraints, provides a theoretically-grounded framework to train consistent estimators. Our experiments on robust models for computer vision confirm that (i) both accuracy and robustness, even if improved after model update, can be affected by negative flips, and (ii) our robustness-congruent adversarial training can mitigate the problem, outperforming competing baseline methods.
Fairness in Machine Learning
Dec 31, 2020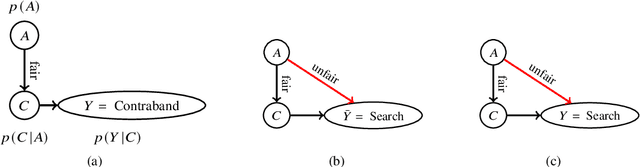
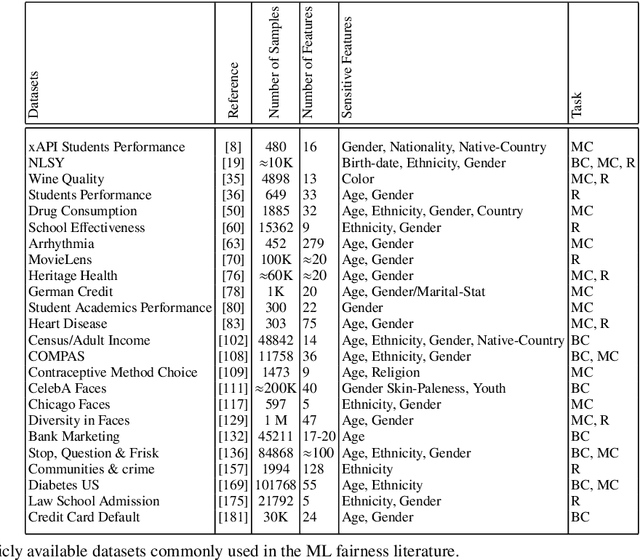
Machine learning based systems are reaching society at large and in many aspects of everyday life. This phenomenon has been accompanied by concerns about the ethical issues that may arise from the adoption of these technologies. ML fairness is a recently established area of machine learning that studies how to ensure that biases in the data and model inaccuracies do not lead to models that treat individuals unfavorably on the basis of characteristics such as e.g. race, gender, disabilities, and sexual or political orientation. In this manuscript, we discuss some of the limitations present in the current reasoning about fairness and in methods that deal with it, and describe some work done by the authors to address them. More specifically, we show how causal Bayesian networks can play an important role to reason about and deal with fairness, especially in complex unfairness scenarios. We describe how optimal transport theory can be used to develop methods that impose constraints on the full shapes of distributions corresponding to different sensitive attributes, overcoming the limitation of most approaches that approximate fairness desiderata by imposing constraints on the lower order moments or other functions of those distributions. We present a unified framework that encompasses methods that can deal with different settings and fairness criteria, and that enjoys strong theoretical guarantees. We introduce an approach to learn fair representations that can generalize to unseen tasks. Finally, we describe a technique that accounts for legal restrictions about the use of sensitive attributes.
Fair Regression with Wasserstein Barycenters
Jun 23, 2020

We study the problem of learning a real-valued function that satisfies the Demographic Parity constraint. It demands the distribution of the predicted output to be independent of the sensitive attribute. We consider the case that the sensitive attribute is available for prediction. We establish a connection between fair regression and optimal transport theory, based on which we derive a close form expression for the optimal fair predictor. Specifically, we show that the distribution of this optimum is the Wasserstein barycenter of the distributions induced by the standard regression function on the sensitive groups. This result offers an intuitive interpretation of the optimal fair prediction and suggests a simple post-processing algorithm to achieve fairness. We establish risk and distribution-free fairness guarantees for this procedure. Numerical experiments indicate that our method is very effective in learning fair models, with a relative increase in error rate that is inferior to the relative gain in fairness.
Learning Fair and Transferable Representations
Jun 25, 2019


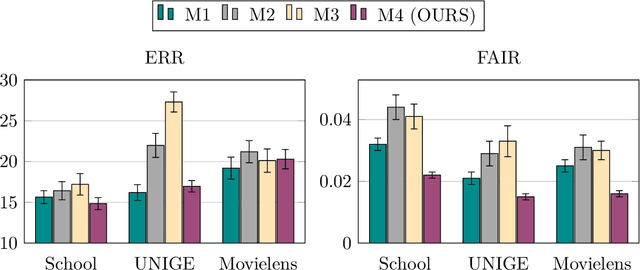
Developing learning methods which do not discriminate subgroups in the population is a central goal of algorithmic fairness. One way to reach this goal is by modifying the data representation in order to meet certain fairness constraints. In this work we measure fairness according to demographic parity. This requires the probability of the possible model decisions to be independent of the sensitive information. We argue that the goal of imposing demographic parity can be substantially facilitated within a multitask learning setting. We leverage task similarities by encouraging a shared fair representation across the tasks via low rank matrix factorization. We derive learning bounds establishing that the learned representation transfers well to novel tasks both in terms of prediction performance and fairness metrics. We present experiments on three real world datasets, showing that the proposed method outperforms state-of-the-art approaches by a significant margin.
Leveraging Labeled and Unlabeled Data for Consistent Fair Binary Classification
Jun 12, 2019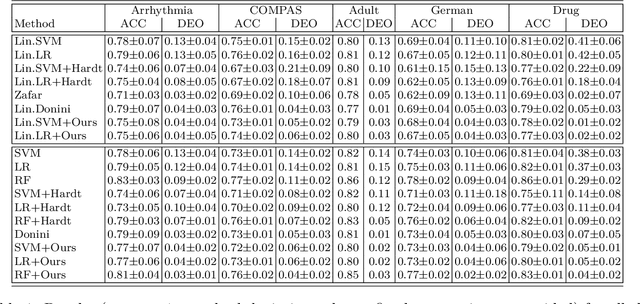
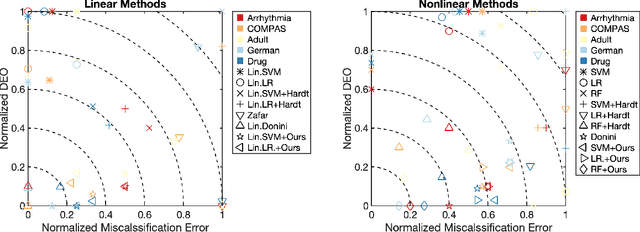
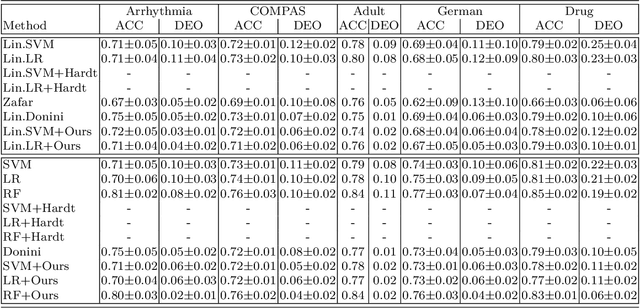
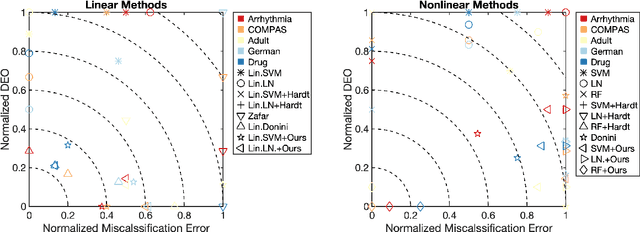
We study the problem of fair binary classification using the notion of Equal Opportunity. It requires the true positive rate to distribute equally across the sensitive groups. Within this setting we show that the fair optimal classifier is obtained by recalibrating the Bayes classifier by a group-dependent threshold. We provide a constructive expression for the threshold. This result motivates us to devise a plug-in classification procedure based on both unlabeled and labeled datasets. While the latter is used to learn the output conditional probability, the former is used for calibration. The overall procedure can be computed in polynomial time and it is shown to be statistically consistent both in terms of classification error and fairness measure. Finally, we present numerical experiments which indicate that our method is often superior or competitive with the state-of-the-art methods on benchmark datasets.